Aprendizaje automático:
una computadora puede aprender de la experiencia sin ser programada explícitamente. Machine Learning es uno de los principales campos para ingresar actualmente y las principales empresas de todo el mundo lo están utilizando para mejorar sus servicios y productos. Pero no se utiliza un modelo de Machine Learning que esté entrenado en su Jupyter Notebook. Por lo tanto, debemos implementar estos modelos para que todos puedan usarlos. En este artículo, primero entrenaremos un clasificador Iris Species y luego implementaremos el modelo usando Streamlit, que es un marco de aplicación de código abierto que se usa para implementar modelos ML fácilmente.
Biblioteca Streamlit:
Streamlit le permite crear aplicaciones para su proyecto de aprendizaje automático utilizando scripts de Python simples. También es compatible con la recarga en caliente, para que su aplicación pueda actualizarse en vivo mientras edita y guarda su archivo. Una aplicación se puede construir solo con unas pocas líneas de código (como veremos a continuación) utilizando la API de Streamlit. Agregar un widget es lo mismo que declarar una variable. No es necesario escribir un backend, definir diferentes rutas o manejar requests HTTP. Es fácil de implementar y administrar. Se puede encontrar más información en su sitio web: https://www.streamlit.io/
Así que primero entrenaremos a nuestro modelo. No haremos mucho preprocesamiento ya que el objetivo principal de este artículo no es hacer un modelo de ML preciso, sino mostrar su implementación.
En primer lugar, debemos instalar lo siguiente:
pip instalar pandas
pip instalar numpy
pip instalar sklearn
pip instalar streamlit
El conjunto de datos se puede encontrar aquí: https://www.kaggle.com/uciml/iris
Código:
import pandas as pd
import numpy as np
df = pd.read_csv('BankNote_Authentication.csv')
df.head()
Salida: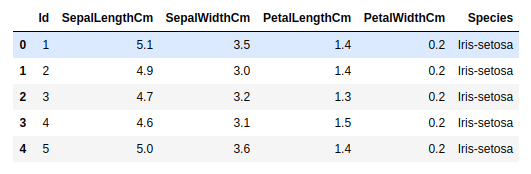
Ahora descartamos primero la columna Id, ya que no es importante para clasificar las especies de Iris. Luego dividiremos el conjunto de datos en conjuntos de datos de entrenamiento y prueba y usaremos un clasificador de bosque aleatorio. Puede utilizar cualquier otro clasificador de su elección, por ejemplo, regresión logística, máquina de vectores de soporte, etc.
Código:
# Dropping the Id column
df.drop('Id', axis = 1, inplace = True)
# Renaming the target column into numbers to aid training of the model
df['Species']= df['Species'].map({'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2})
# splitting the data into the columns which need to be trained(X) and the target column(y)
X = df.iloc[:, :-1]
y = df.iloc[:, -1]
# splitting data into training and testing data with 30 % of data as testing data respectively
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
# importing the random forest classifier model and training it on the dataset
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier()
classifier.fit(X_train, y_train)
# predicting on the test dataset
y_pred = classifier.predict(X_test)
# finding out the accuracy
from sklearn.metrics import accuracy_score
score = accuracy_score(y_test, y_pred)
Obtenemos una precisión del 95,55%, que es bastante buena.
Ahora, para usar este modelo para predecir otros datos desconocidos, debemos guardarlo. Podemos guardarlo usando pickle, que se usa para serializar y deserializar una estructura de objetos de Python.
Código:
# pickling the model
import pickle
pickle_out = open("classifier.pkl", "wb")
pickle.dump(classifier, pickle_out)
pickle_out.close()
Se creará un nuevo archivo llamado «classifier.pkl» en el mismo directorio. Ahora podemos comenzar a usar Streamlit para implementar el modelo:
Pegue el siguiente código en otro archivo python.
Código:
import pandas as pd
import numpy as np
import pickle
import streamlit as st
from PIL import Image
# loading in the model to predict on the data
pickle_in = open('classifier.pkl', 'rb')
classifier = pickle.load(pickle_in)
def welcome():
return 'welcome all'
# defining the function which will make the prediction using
# the data which the user inputs
def prediction(sepal_length, sepal_width, petal_length, petal_width):
prediction = classifier.predict(
[[sepal_length, sepal_width, petal_length, petal_width]])
print(prediction)
return prediction
# this is the main function in which we define our webpage
def main():
# giving the webpage a title
st.title("Iris Flower Prediction")
# here we define some of the front end elements of the web page like
# the font and background color, the padding and the text to be displayed
html_temp = """
<div style ="background-color:yellow;padding:13px">
<h1 style ="color:black;text-align:center;">Streamlit Iris Flower Classifier ML App </h1>
</div>
"""
# this line allows us to display the front end aspects we have
# defined in the above code
st.markdown(html_temp, unsafe_allow_html = True)
# the following lines create text boxes in which the user can enter
# the data required to make the prediction
sepal_length = st.text_input("Sepal Length", "Type Here")
sepal_width = st.text_input("Sepal Width", "Type Here")
petal_length = st.text_input("Petal Length", "Type Here")
petal_width = st.text_input("Petal Width", "Type Here")
result =""
# the below line ensures that when the button called 'Predict' is clicked,
# the prediction function defined above is called to make the prediction
# and store it in the variable result
if st.button("Predict"):
result = prediction(sepal_length, sepal_width, petal_length, petal_width)
st.success('The output is {}'.format(result))
if __name__=='__main__':
main()
Puede ejecutar esto escribiendo el siguiente comando en la terminal:
aplicación de ejecución streamlit.py
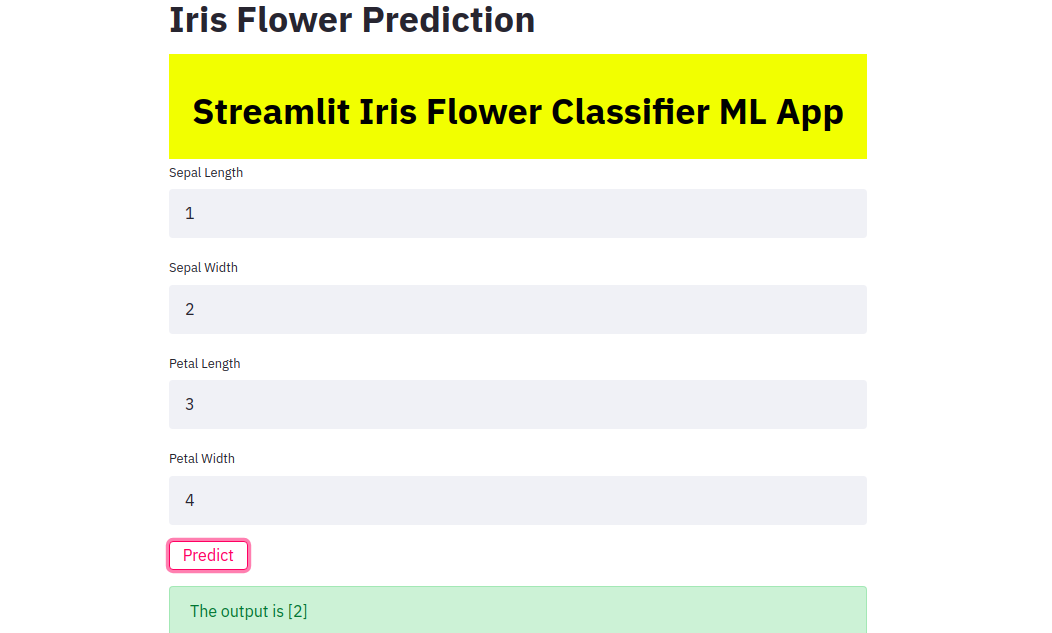
app.py is the name of the file where we wrote the Streamlit code.
El sitio web se abrirá en su navegador y luego podrá probarlo. Este método también se puede usar para implementar otros modelos de aprendizaje automático y profundo.
Publicación traducida automáticamente
Artículo escrito por AashalKamdar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA