¿Qué son las incrustaciones de palabras?
Es un enfoque para representar palabras y documentos. Word Embedding o Word Vector es una entrada de vector numérico que representa una palabra en un espacio de menor dimensión. Permite que palabras con un significado similar tengan una representación similar. También pueden aproximar el significado. Un vector de palabras con 50 valores puede representar 50 características únicas.
Características: Cualquier cosa que relacione palabras entre sí. Por ejemplo: edad, deportes, forma física, empleado, etc. Cada vector de palabra tiene valores correspondientes a estas características.
Objetivo de las incrustaciones de palabras
- Para reducir la dimensionalidad
- Usar una palabra para predecir las palabras que la rodean.
- La semántica entre palabras debe ser capturada
¿Cómo se utilizan las incrustaciones de palabras?
- Se utilizan como entrada para los modelos de aprendizaje automático.
Tome las palabras —-> Dé su representación numérica —-> Use en entrenamiento o inferencia - Para representar o visualizar cualquier patrón subyacente de uso en el corpus que se usó para entrenarlos.
Implementaciones de Word Embeddings:
Las incrustaciones de palabras son un método para extraer características del texto para que podamos ingresar esas características en un modelo de aprendizaje automático para trabajar con datos de texto. Intentan preservar la información sintáctica y semántica. Los métodos como Bag of Words (BOW), CountVectorizer y TFIDF se basan en el recuento de palabras en una oración, pero no guardan ninguna información sintáctica o semántica. En estos algoritmos, el tamaño del vector es el número de elementos en el vocabulario. Podemos obtener una array dispersa si la mayoría de los elementos son cero. Los vectores de entrada grandes significarán una gran cantidad de pesos, lo que resultará en un alto cálculo requerido para el entrenamiento. Word Embeddings da una solución a estos problemas.
Tomemos un ejemplo para entender cómo se genera un vector de palabras al tomar emoticones que se usan con mayor frecuencia en ciertas condiciones y transformar cada emoji en un vector y las condiciones serán nuestras características.
| Contento | ???? | ???? | ???? |
|---|---|---|---|
| Triste | ???? | ???? | ???? |
| Entusiasmado | ???? | ???? | ???? |
| Enfermo | ???? | ???? | ???? |
The emoji vectors for the emojis will be:
[happy,sad,excited,sick]
???? =[1,0,1,0]
???? =[0,1,0,1]
???? =[0,0,1,1]
.....
De manera similar, también podemos crear vectores de palabras para diferentes palabras en función de las características dadas. Es más probable que las palabras con vectores similares tengan el mismo significado o se utilicen para transmitir el mismo sentimiento.
En este artículo, discutiremos dos enfoques diferentes para obtener incrustaciones de Word:
1) Word2Vec:
En Word2Vec a cada palabra se le asigna un vector. Comenzamos con un vector aleatorio o un vector caliente .
Vector One-Hot: una representación en la que solo un bit en un vector es 1. Si hay 500 palabras en el corpus, la longitud del vector será 500. Después de asignar vectores a cada palabra, tomamos un tamaño de ventana e iteramos a través de todo el corpus . Mientras hacemos esto, hay dos métodos de incrustación neuronal que se utilizan:
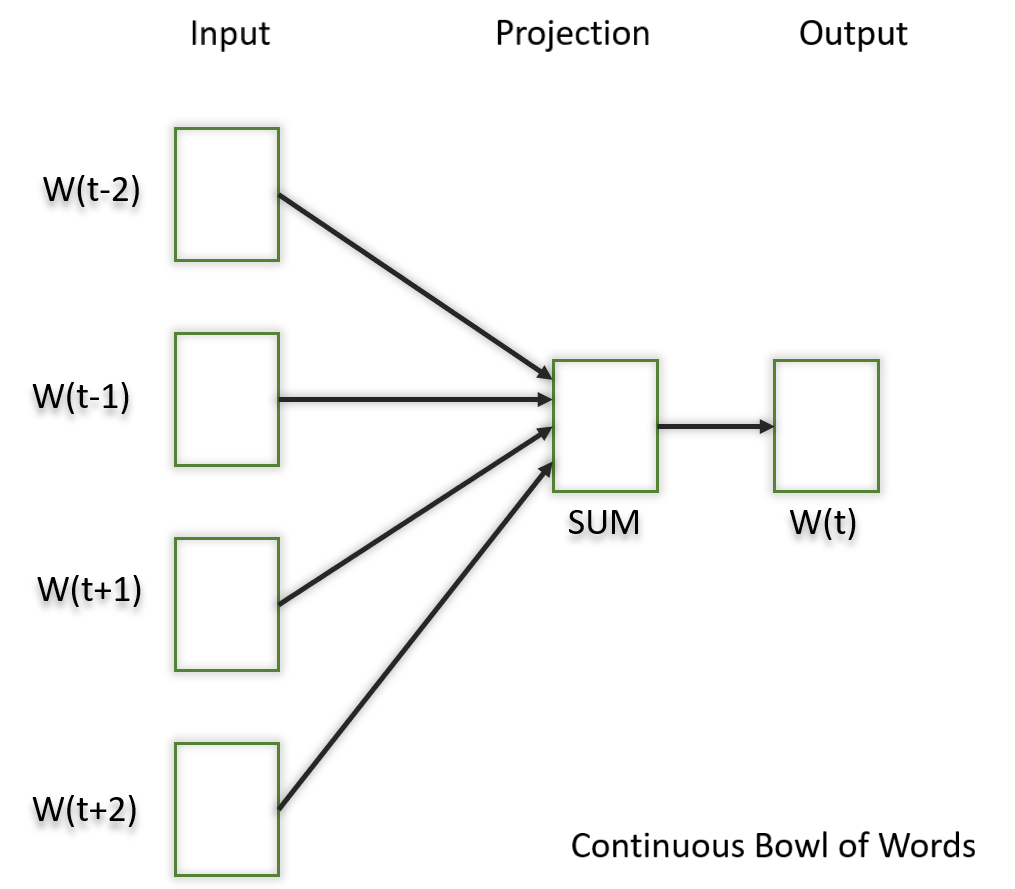
1.1) Cuenco continuo de palabras (CBOW)
En este modelo lo que hacemos es intentar encajar las palabras vecinas en la ventana a la palabra central.
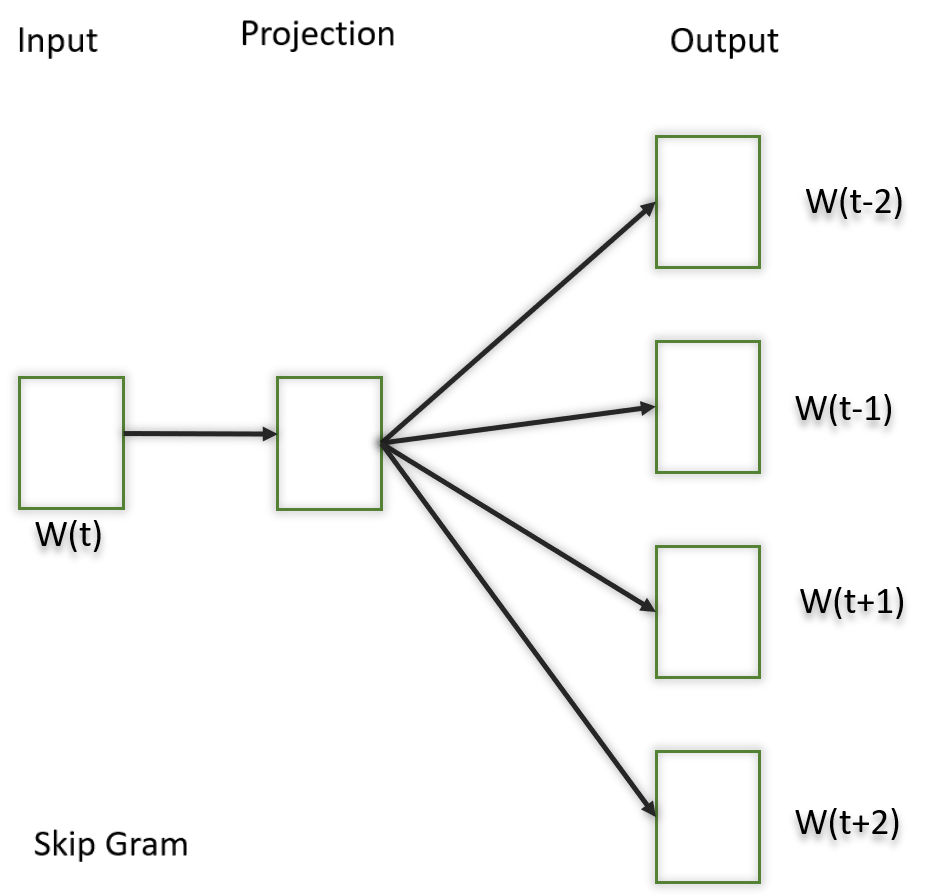
1.2) Saltar gramo
En este modelo, tratamos de acercar la palabra central a las palabras vecinas. Es todo lo contrario del modelo CBOW. Se muestra que este método produce incrustaciones más significativas.
Después de aplicar los métodos de incrustación neuronal anteriores, obtenemos vectores entrenados de cada palabra después de muchas iteraciones a través del corpus. Estos vectores entrenados conservan información sintáctica o semántica y se convierten a dimensiones más bajas. Los vectores con significado similar o información semántica se colocan uno cerca del otro en el espacio.
2) GUANTE:
Este es otro método para crear incrustaciones de palabras. En este método, tomamos el corpus e iteramos a través de él y obtenemos la co-ocurrencia de cada palabra con otras palabras en el corpus. Obtenemos una array de co-ocurrencia a través de esto. Las palabras que aparecen una al lado de la otra obtienen un valor de 1, si están separadas por una palabra entonces 1/2, si están separadas por dos palabras entonces 1/3 y así sucesivamente.
Tomemos un ejemplo para entender cómo se crea la array. Tenemos un pequeño corpus:
Corpus: It is a nice evening. Good Evening! Is it a nice evening?
| eso | es | a | bonito | tardecita | bueno | |
|---|---|---|---|---|---|---|
| eso | 0 | |||||
| es | 1+1 | 0 | ||||
| a | 1/2+1 | 1+1/2 | 0 | |||
| bonito | 1/3+1/2 | 1/2+1/3 | 1+1 | 0 | ||
| tardecita | 1/4+1/3 | 1/3+1/4 | 1/2+1/2 | 1+1 | 0 | |
| bueno | 0 | 0 | 0 | 0 | 1 | 0 |
La mitad superior de la array será un reflejo de la mitad inferior. También podemos considerar un marco de ventana para calcular las co-ocurrencias desplazando el marco hasta el final del corpus. Esto ayuda a recopilar información sobre el contexto en el que se usa la palabra.
Inicialmente, los vectores de cada palabra se asignan aleatoriamente. Luego tomamos dos pares de vectores y vemos qué tan cerca están uno del otro en el espacio. Si ocurren juntos con más frecuencia o tienen un valor más alto en la array de co-ocurrencia y están muy separados en el espacio, entonces se acercan entre sí. Si están cerca uno del otro pero rara vez o no se usan juntos con frecuencia, entonces se separan más en el espacio.
Después de muchas iteraciones del proceso anterior, obtendremos una representación de espacio vectorial que se aproxima a la información de la array de coocurrencia. El rendimiento de GloVe es mejor que Word2Vec en términos de captura semántica y sintáctica.
Modelos de incrustación de palabras preentrenados:
Las personas generalmente usan modelos previamente entrenados para incrustaciones de palabras. Algunos de ellos son:
- Espacioso
- texto rápido
- Estilo, etc
Errores comunes cometidos:
- Debe usar exactamente la misma canalización durante la implementación de su modelo que se usó para crear los datos de entrenamiento para la incrustación de palabras. Si usa un tokenizador diferente o un método diferente para manejar espacios en blanco, puntuación, etc., podría terminar con entradas incompatibles.
- Palabras en su entrada que no tienen un vector entrenado previamente. Estas palabras se conocen como palabras fuera de vocabulario (oov). Lo que puede hacer es reemplazar esas palabras con «UNK», que significa desconocido y luego manejarlas por separado.
- Desajuste de dimensiones: los vectores pueden tener muchas longitudes. Si entrena un modelo con vectores de longitud digamos 400 y luego intenta aplicar vectores de longitud 1000 en el momento de la inferencia, se encontrará con errores. Así que asegúrese de usar las mismas dimensiones en todas partes.
Beneficios de usar Word Embeddings:
- Es mucho más rápido de entrenar que los modelos de construcción manual como WordNet (que usa incrustaciones de gráficos )
- Casi todas las aplicaciones modernas de NLP comienzan con una capa de incrustación
- Almacena una aproximación de significado.
Inconvenientes de las incrustaciones de palabras:
- Puede ser intensivo en memoria
- Es corpus dependiente. Cualquier sesgo subyacente tendrá un efecto en su modelo
- No puede distinguir entre homófonos. Por ejemplo: freno/descanso, celda/venta, clima/si, etc.
Publicación traducida automáticamente
Artículo escrito por shristikotaiah y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA