Un histograma es una variación de un gráfico de barras en el que los valores de los datos se agrupan y se colocan en diferentes clases. Esta agrupación le permite ver con qué frecuencia ocurren los datos de cada clase en el conjunto de datos.
El histograma muestra gráficamente lo siguiente:
- Frecuencia de diferentes puntos de datos en el conjunto de datos.
- Ubicación del centro de datos.
- La difusión del conjunto de datos.
- Sesgo/varianza del conjunto de datos.
- Presencia de valores atípicos en el conjunto de datos.
Las características proporcionan una fuerte indicación del modelo de distribución adecuado en los datos. Se puede utilizar la gráfica de probabilidad o una prueba de bondad de ajuste para verificar el modelo distribucional.
El histograma contiene los siguientes ejes:
- Eje vertical : frecuencia/recuento de cada contenedor.
- Eje horizontal : Lista de contenedores/categorías.
Interpretaciones del histograma:
- Histograma normal: es un histograma clásico en forma de campana con la mayoría de los conteos de frecuencia enfocados en el medio con colas decrecientes y hay simetría con respecto a la mediana. Dado que la distribución normal se observa más comúnmente en escenarios del mundo real, es más probable que encuentre estos. En el histograma normalmente distribuido, la media es casi igual a la mediana.
- Histograma no normal de cola corta/cola larga: En la distribución de cola corta, la cola se acerca a 0 muy rápido, a medida que nos alejamos de la mediana de los datos. En el histograma de cola larga, la cola se acerca a 0 lentamente a medida que nos alejamos de la mediana. mediana. Aquí, nos referimos a la cola como las regiones extremas en el histograma donde la mayoría de los datos no están concentrados y esto está en ambos lados del pico.
- Histograma bimodal: un modo de datos representa los valores más comunes en el histograma (es decir, el pico del histograma). Un histograma bimodal representa que hay dos picos en el histograma. El histograma se puede usar para probar la unimodalidad de los datos. La bimodalidad ( o, por ejemplo, no unimodalidad) en el conjunto de datos representa que hay algo mal con el proceso. Histograma bimodal muchos uno o ambos de dos caracteres: distribución normal bimodal y distribución simétrica
- Histograma sesgado a izquierda/derecha: Los histogramas sesgados son aquellos en los que la cola de un lado es claramente más larga que la cola del otro lado. Un histograma sesgado hacia la derecha significa que la cola del lado derecho del pico está más estirada que la izquierda y viceversa para el lado izquierdo. En un histograma sesgado a la izquierda, la media siempre es menor que la mediana, mientras que en un histograma sesgado a la derecha, la media es mayor que el histograma.
- Histograma uniforme: en el histograma uniforme, cada contenedor contiene aproximadamente el mismo número de conteos (frecuencia). El ejemplo de histograma uniforme es como un dado que se lanza n (n>>30) veces y registra la frecuencia de diferentes resultados.
- Distribución normal con un valor atípico: este histograma es similar al histograma normal excepto que contiene un valor atípico donde el conteo/probabilidad de resultado es sustantivo. Esto se debe principalmente a algunos errores del sistema en el proceso, lo que condujo a una generación defectuosa de productos, etc.
Implementación
- En esta implementación, utilizaremos las bibliotecas de trazado Numpy, Matplotlib y Seaborn. Estas bibliotecas están preinstaladas en colab; sin embargo, para el entorno local, puede instalarlas fácilmente con el comando pip install .
Python3
# Imports import numpy as np import matplotlib.pyplot as plt import seaborn as sns # Normal histogram plot data = np.random.normal(10.0, 3, 500) sns.displot(data, kde= True, bins=10, color='black') # Left-skewed Histogram wc_goals =[0]* 19 + [1]*49 + [2]*60 + [3] *47 + [4]*32 + [5]* 18+ [6]*3 + [7]*3 + [8] sns.displot(wc_goals, bins=8, kde= True, alpha =0.6,color='blue') # Right-skewed Histogram wc_goals_conc = [0]* 19 + [-1]*49 + [-2]*60 + [-3] *47 + [-4]*32 + [-5]* 18+ [-6]*3 + [-7]*3 + [-8] sns.displot(wc_goals_conc, kde = True,bins=8, alpha=0.6, color='red') # Bi-modal histogram N=400 mu_1, sigma_1 = 80, 10 mu_2, sigma_2 = 20, 10 # Generate two normal distributions of given mean sdand concatenate X_1 = np.random.normal(mu, sigma, N) X_2 = np.random.normal(mu2, sigma2, N) X = np.concatenate([X1, X2]) sns.displot(X,bins=10,kde=True , color='green') # Uniform histogram (an example of die roll with N=600) die_roll = [1]*89 + [2]*94 + [3]*110 + [4]*101 + [5]*90 +[6]*116 sns.displot(die_roll, kde=True, bins =6) # Normal distribution with an outlier X_1 = np.random.normal(mu, sigma, N) X_1 =np.concatenate([X1, [200]*30]) sns.displot(X_1, kde= True, bins=13)
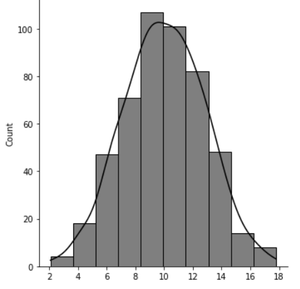
Histograma normal
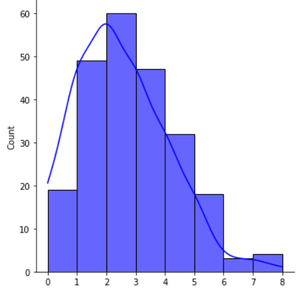
Histograma sesgado a la izquierda
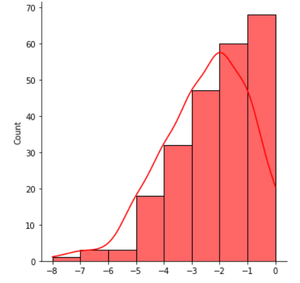
Histograma sesgado a la derecha
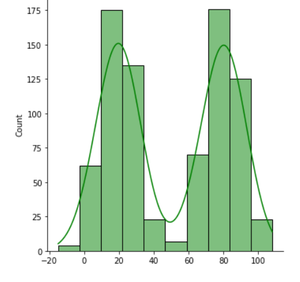
Histograma bimodal
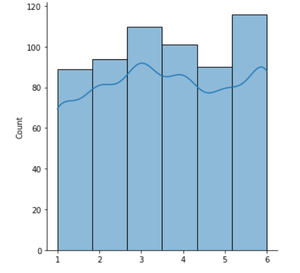
Histograma uniforme
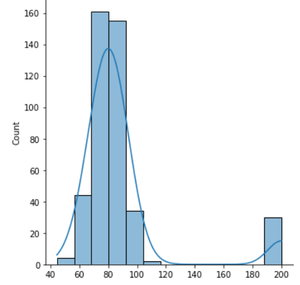
Normal con un valor atípico