Motivar la IA explicable
El vasto campo de la Inteligencia Artificial (IA) ha experimentado un enorme crecimiento en los últimos años. Con modelos más nuevos y complejos cada año, los modelos de IA han comenzado a superar el intelecto humano a un ritmo que nadie podría haber predicho. Pero a medida que obtenemos resultados más exactos y precisos, se vuelve más difícil explicar el razonamiento detrás de las complejas decisiones matemáticas que toman estos modelos. Esta abstracción matemática tampoco ayuda a los usuarios a mantener su confianza en las decisiones de un modelo en particular.
Por ejemplo, supongamos que un modelo de aprendizaje profundo toma una imagen y predice con un 70 % de precisión que un paciente tiene cáncer de pulmón. Aunque el modelo podría haber dado el diagnóstico correcto, un médico realmente no puede aconsejar a un paciente con confianza , ya que no conoce el razonamiento detrás del diagnóstico de dicho modelo .
¡Aquí es donde entra la IA explicable (o más popularmente conocida como XAI)! La IA explicable se refiere colectivamente a técnicas o métodos que ayudan a explicar el proceso de toma de decisiones de un modelo de IA dado. Esta rama recién descubierta de la IA ha mostrado un enorme potencial, con técnicas más nuevas y sofisticadas que llegan cada año. Algunas de las técnicas XAI más famosas incluyen SHAP (explicaciones de aditivos de Shapley), DeepSHAP, DeepLIFT, CXplain y LIME. Este artículo cubre LIME en detalle.
Presentamos LIME (o explicaciones locales interpretables independientes del modelo)
La belleza de LIME su accesibilidad y sencillez. ¡La idea central detrás de LIME, aunque exhaustiva, es realmente intuitiva y simple! Profundicemos y veamos qué representa el nombre en sí:
- El agnosticismo del modelo se refiere a la propiedad de LIME mediante la cual puede dar explicaciones para cualquier modelo de aprendizaje supervisado dado al tratarlo como una «caja negra» por separado. ¡Esto significa que LIME puede manejar casi cualquier modelo que existe en la naturaleza!
- Las explicaciones locales significan que LIME da explicaciones que son localmente fieles dentro del entorno o vecindad de la observación/muestra que se está explicando.
Aunque LIME se limita a los modelos supervisados de Machine Learning y Deep Learning en su estado actual, es uno de los métodos XAI más populares y utilizados que existen. Con una rica API de código abierto, disponible en R y Python, LIME cuenta con una enorme base de usuarios, con casi 8 000 estrellas y 2 000 bifurcaciones en su repositorio de Github .
¿Cómo funciona LIME?
En términos generales, cuando se le proporciona un modelo de predicción y una muestra de prueba, LIME realiza los siguientes pasos:
- Muestreo y obtención de un conjunto de datos sustituto: LIME proporciona explicaciones localmente fieles en torno a la vecindad de la instancia que se está explicando. Por defecto, produce 5000 muestras (ver la variable num_samples ) del vector de características siguiendo la distribución normal. Luego obtiene la variable objetivo para estas 5000 muestras utilizando el modelo de predicción, cuyas decisiones intenta explicar.
- Selección de características del conjunto de datos sustituto: después de obtener el conjunto de datos sustituto, pesa cada fila de acuerdo con lo cerca que están de la muestra/observación original. Luego utiliza una técnica de selección de características como Lasso para obtener las características más importantes.
LIME también emplea un modelo de regresión de crestas en las muestras utilizando solo las características obtenidas. En teoría, la predicción generada debería ser similar en magnitud a la generada por el modelo de predicción original. Esto se hace para enfatizar la relevancia e importancia de estas características obtenidas.
Realmente no profundizaremos en los detalles técnicos y matemáticos detrás de las partes internas de LIME en este artículo. Aún así, puede revisar el trabajo de investigación base si está interesado en él. Ahora, a la parte más interesante, ¡el código!
Instalando LIME
Llegando a la parte de la instalación, podemos usar pip o conda para instalar LIME en Python.
pip install lime
o
conda install -c conda-forge lime
Antes de continuar, aquí hay algunos consejos clave que ayudarían a obtener una mejor comprensión de todo el flujo de trabajo que rodea a LIME.
Descripción del conjunto de datos:
LIME en su estado actual solo puede dar explicaciones para el siguiente tipo de conjuntos de datos:
- Conjuntos de datos tabulares (lime.lime_tabular.LimeTabularExplainer): por ejemplo: Regresión, conjuntos de datos de clasificación
- Conjuntos de datos relacionados con imágenes (lime.lime_image.LimeImageExplainer)
- Conjuntos de datos relacionados con texto (lime.lime_text.LimeTextExplainer)
Dado que este es un artículo introductorio, mantendremos las cosas simples y seguiremos adelante con un conjunto de datos tabulares. Más específicamente, utilizaremos el conjunto de datos de precios de la vivienda de Boston para nuestro análisis. Usaremos la utilidad Scikit-Learn para cargar el conjunto de datos .
Modelo de predicción utilizado:
Como LIME es independiente del modelo por naturaleza, puede manejar casi cualquier modelo que se le presente. Para enfatizar este hecho, usaremos un regresor de árboles adicionales a través de la utilidad Scitkit-learn como nuestro modelo de predicción cuyas decisiones estamos tratando de investigar.
Breve introducción a LimeTabularExplainer
Como se explicó anteriormente, usaremos un conjunto de datos tabulares para nuestro análisis. Para abordar tales conjuntos de datos, la API de LIME ofrece LimeTabularExplainer.
Sintaxis: lime.lime_tabular.LimeTabularExplainer(training_data, mode, feature_names, verbose)
Parámetros:
- training_data: array 2d que consta del conjunto de datos de entrenamiento
- modo – Depende del problema; “clasificación” o “regresión”
- feature_names: lista de títulos correspondientes a las columnas en el conjunto de datos de entrenamiento. Si no se menciona, utiliza los índices de columna.
- detallado: si es verdadero, imprime los valores de predicción locales del modelo de regresión entrenado en las muestras usando solo las características obtenidas
Una vez instanciado, usaremos un método del objeto explicativo definido para explicar una muestra de prueba dada.
Sintaxis: explicación_instancia(data_row, predict_fn, num_features=10, num_samples=5000)
Parámetros:
- data_row: array 1d que contiene valores correspondientes a la muestra de prueba que se explica
- predict_fn: función de predicción utilizada por el modelo de predicción
- num_features: número máximo de funciones presentes en la explicación
- num_samples – tamaño del vecindario para aprender el modelo lineal
En aras de la brevedad y la concisión, solo algunos de los argumentos se han mencionado en las dos sintaxis anteriores. El resto de los argumentos, la mayoría de los cuales tienen por defecto algunos valores inteligentemente optimizados, pueden ser consultados por el lector interesado en la documentación oficial de LIME .
flujo de trabajo
- Preprocesamiento de datos
- Entrenamiento de un regresor de árboles adicionales en el conjunto de datos
- Obtener explicaciones para una muestra de prueba dada
Análisis
1. Extraer los datos de la utilidad Scikit-learn
Python
# Importing the necessary libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd # Loading the dataset using sklearn from sklearn.datasets import load_boston data = load_boston() # Displaying relevant information about the data print(data['DESCR'][200:1420])
Producción:
Salida del cuaderno Jupyter del código anterior
2. Extraer la array de características X y la variable de destino y, y hacer una división de prueba de entrenamiento
Python
# Separating data into feature variable X and target variable y respectively
from sklearn.model_selection import train_test_split
X = data['data']
y = data['target']
# Extracting the names of the features from data
features = data['feature_names']
# Splitting X & y into training and testing set
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=0.90, random_state=50)
# Creating a dataframe of the data, for a visual check
df = pd.concat([pd.DataFrame(X), pd.DataFrame(y)], axis=1)
df.columns = np.concatenate((features, np.array(['label'])))
print("Shape of data =", df.shape)
# Printing the top 5 rows of the dataframe
df.head()
Producción:
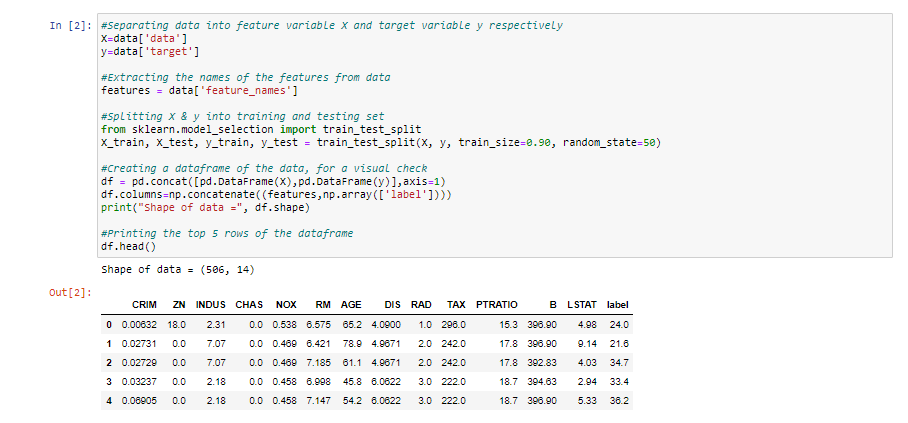
Salida del cuaderno Jupyter del código anterior
3. Crear una instancia del modelo de predicción y entrenarlo en (X_train, y_train)
Python
# Instantiating the prediction model - an extra-trees regressor
from sklearn.ensemble import ExtraTreesRegressor
reg = ExtraTreesRegressor(random_state=50)
# Fitting the predictino model onto the training set
reg.fit(X_train, y_train)
# Checking the model's performance on the test set
print('R2 score for the model on test set =', reg.score(X_test, y_test))
Producción:

Salida del cuaderno Jupyter del código anterior
4. Instanciando el objeto explicativo
Python
# Importing the module for LimeTabularExplainer import lime.lime_tabular # Instantiating the explainer object by passing in the training set, and the extracted features explainer_lime = lime.lime_tabular.LimeTabularExplainer(X_train, feature_names=features, verbose=True, mode='regression')
5. Obtener explicaciones llamando al método Explain_instance()
- Supongamos que queremos explorar el razonamiento del modelo de predicción detrás de la predicción que dio para el i-ésimo vector de prueba .
- Además, supongamos que queremos visualizar las k características principales que llevaron a este razonamiento .
Para este artículo, hemos dado explicaciones para dos combinaciones de i & k :
5.1 Explicando las decisiones para i=10, k=5
Básicamente, le pedimos a LIME que explique las decisiones detrás de las predicciones para el décimo vector de prueba al mostrar las 5 características principales que contribuyeron a la predicción de dicho modelo.
Python
# Index corresponding to the test vector
i = 10
# Number denoting the top features
k = 5
# Calling the explain_instance method by passing in the:
# 1) ith test vector
# 2) prediction function used by our prediction model('reg' in this case)
# 3) the top features which we want to see, denoted by k
exp_lime = explainer_lime.explain_instance(
X_test[i], reg.predict, num_features=k)
# Finally visualizing the explanations
exp_lime.show_in_notebook()
Producción:
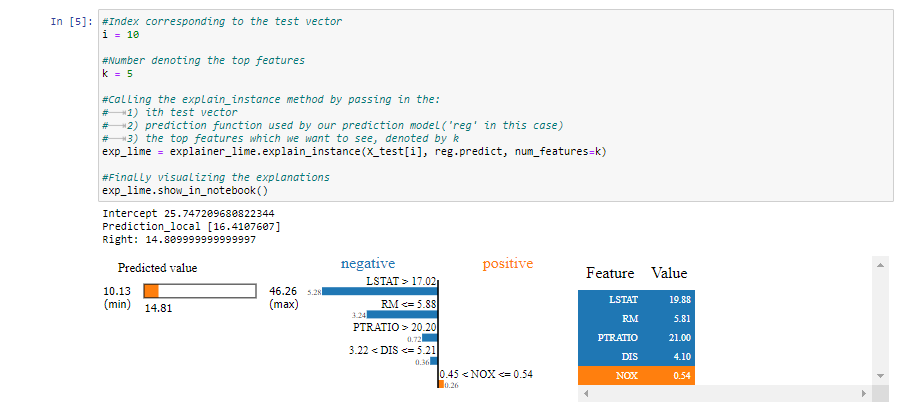
Salida del cuaderno Jupyter del código anterior
Interpretando la salida:
¡Hay mucha información que genera LIME! Vayamos paso a paso e interpretemos lo que intenta transmitir
- En primer lugar, vemos tres valores justo encima de las visualizaciones:
- Derecha: Esto denota la predicción dada por nuestro modelo de predicción (un regresor de árboles adicionales en este caso) para el vector de prueba dado.
- Prediction_local: esto denota el valor generado por un modelo lineal entrenado en las muestras perturbadas (obtenidas al muestrear alrededor del vector de prueba siguiendo una distribución normal) y usando solo las características k principales generadas por LIME.
- Intersección: la intersección es la parte constante de la predicción dada por la predicción del modelo lineal anterior para el vector de prueba dado.

- En cuanto a las visualizaciones, podemos ver los colores azul y naranja , que representan asociaciones negativas y positivas , respectivamente.
- Para interpretar los resultados anteriores, podemos concluir que el valor del precio relativamente más bajo (representado por una barra a la izquierda) de la casa representada por el vector dado puede atribuirse a las siguientes razones socioeconómicas:
- el alto valor de LSTAT que indica el estado más bajo de una sociedad en términos de educación y desempleo
- el valor alto de PTRATIO que indica el valor alto del número de alumnos por profesor
- el alto valor de DIS indica el alto valor de la distancia a los centros de empleo.
- el valor bajo de RM indica la menor cantidad de habitaciones por vivienda
- También podemos ver que el bajo valor de NOX indica que la baja cantidad de concentración de rust nítrico en el aire ha aumentado el valor de la casa en una pequeña medida.
- Para interpretar los resultados anteriores, podemos concluir que el valor del precio relativamente más bajo (representado por una barra a la izquierda) de la casa representada por el vector dado puede atribuirse a las siguientes razones socioeconómicas:
Podemos ver lo fácil que se ha vuelto correlacionar las decisiones tomadas por un modelo de predicción relativamente complejo (un regresor de árboles adicionales) de una manera interpretable y significativa. ¡Probemos este ejercicio en un vector de prueba más!
5.2 Explicando las decisiones para i=47, k=5
Aquí nuevamente le pedimos a LIME que explique las decisiones detrás de las predicciones para el vector de prueba 47 al mostrar las 5 características principales que contribuyeron a la predicción de dicho modelo.
Python
# Index corresponding to the test vector
i = 47
# Number denoting the top features
k = 5
# Calling the explain_instance method by passing in the:
# 1) ith test vector
# 2) prediction function used by our prediction model('reg' in this case)
# 3) the top features which we want to see, denoted by k
exp_lime = explainer_lime.explain_instance(
X_test[i], reg.predict, num_features=k)
# Finally visualizing the explanations
exp_lime.show_in_notebook()
Producción:
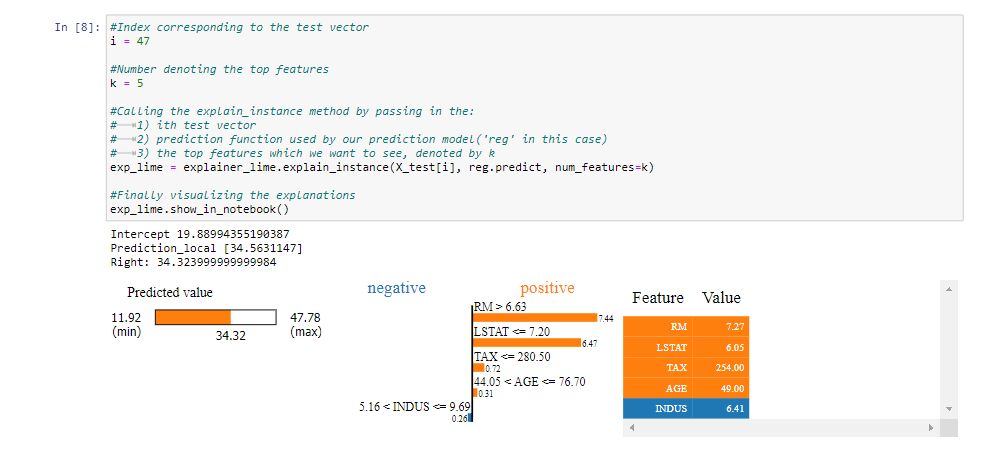
Salida del cuaderno Jupyter del código anterior
Interpretando la salida:
- De las visualizaciones, podemos concluir que el valor del precio relativamente más alto (representado por una barra a la izquierda) de la casa representada por el vector dado puede atribuirse a las siguientes razones socioeconómicas:
- El bajo valor de LSTAT que indica el gran estatus de una sociedad en términos de educación y empleabilidad.
- El alto valor de RM indica el alto número de cuartos por vivienda
- El bajo valor de TAX que indica la baja tasa impositiva de la propiedad
- El bajo valor de AGE que representa la novedad del establecimiento.
- También podemos ver que el valor promedio de INDUS , que indica que el bajo número de no minoristas cerca de la sociedad , ha disminuido el valor de la casa en una pequeña medida.
Resumen:
Este artículo es una breve introducción a la IA explicable (XAI) usando LIME en Python. Es evidente lo beneficioso que LIME podría brindarnos una intuición mucho más profunda detrás del proceso de toma de decisiones de un modelo de caja negra dado, al tiempo que brinda información sólida sobre el conjunto de datos inherente. ¡Esto hace que LIME sea un recurso útil tanto para los investigadores de IA como para los científicos de datos!
Referencias:
- https://lime-ml.readthedocs.io/en/latest/
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.ExtraTreesRegressor.html
- https://scikit-learn.org/0.16/modules/generated/sklearn.datasets.load_boston.html#sklearn.datasets.load_boston
- Marco Tulio Ribeiro, Sameer Singh y Carlos Guestrin. “¿Por qué debería confiar en ti?”: Explicando las predicciones de cualquier clasificador. En Actas de la 22.ª Conferencia Internacional ACM SIGKDD sobre Descubrimiento de Conocimiento y Minería de Datos, página 1135–1144. Asociación de Maquinaria de Computación, 2016.
Publicación traducida automáticamente
Artículo escrito por adityasaini70 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA