Estadística simplemente significa datos numéricos, y es un campo de las matemáticas que generalmente se ocupa de la recopilación de datos, la tabulación y la interpretación de datos numéricos. En realidad, es una forma de análisis matemático que utiliza diferentes modelos cuantitativos para producir un conjunto de datos experimentales o estudios de la vida real. Es un área de interés de las matemáticas aplicadas con el análisis, la interpretación y la presentación de la recopilación de datos. La estadística se ocupa de cómo se pueden utilizar los datos para resolver problemas complejos. Algunas personas consideran que la estadística es una ciencia matemática distinta en lugar de una rama de las matemáticas.
Las estadísticas facilitan y simplifican el trabajo y brindan una imagen clara y limpia del trabajo que realiza regularmente.
Terminología básica de Estadística:
- Población:
en realidad es una colección de un conjunto de individuos u objetos o eventos cuyas propiedades se van a analizar. - Muestra:
es el subconjunto de una población.
Tipos de estadísticas:

1. Estadísticas
descriptivas: las estadísticas descriptivas utilizan datos que proporcionan una descripción de la población, ya sea a través de cálculos numéricos, gráficos o tablas. Proporciona un resumen gráfico de los datos. Simplemente se usa para resumir objetos, etc. Hay dos categorías en esto como sigue a continuación.
- (a). Medida de tendencia central: la
medida de tendencia central también se conoce como estadística de resumen que se utiliza para representar el punto central o un valor particular de un conjunto de datos o un conjunto de muestras.
En estadística, hay tres medidas comunes de tendencia central como se muestra a continuación:- (i) Media:
es la medida del promedio de todos los valores en un conjunto de muestras.
Por ejemplo,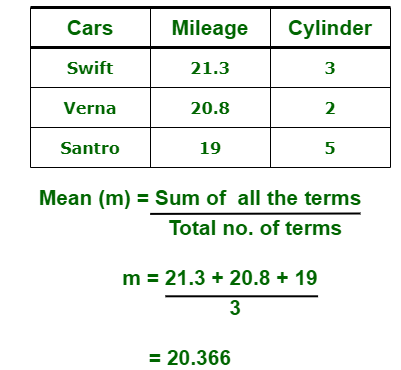
- (ii) Mediana:
es la medida del valor central de un conjunto de muestras. En estos, el conjunto de datos se ordena de menor a mayor valor y luego encuentra el medio exacto.
Por ejemplo,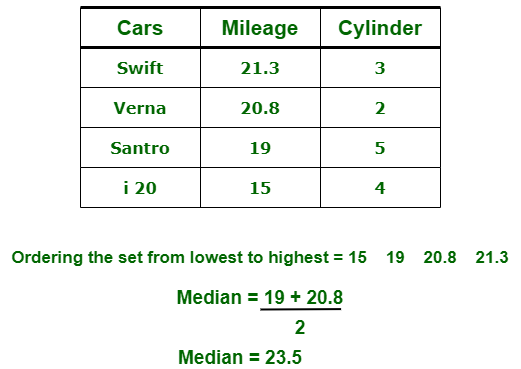
- (iii) Moda:
Es el valor que llega con mayor frecuencia en el conjunto de la muestra. El valor que se repite la mayor parte del tiempo en el conjunto central es en realidad el modo.
Por ejemplo,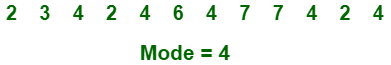
- (i) Media:
- (b). Medida de variabilidad:
la medida de variabilidad también se conoce como medida de dispersión y se utiliza para describir la variabilidad en una muestra o población. En estadística, hay tres medidas comunes de variabilidad como se muestra a continuación:- (i) Rango:
se da una medida de cómo separar los valores en un conjunto de muestra o conjunto de datos.Range = Maximum value - Minimum value
- (ii) Varianza:
simplemente describe cuánto difiere una variable aleatoria del valor esperado y también se calcula como el cuadrado de la desviación.S2= ∑ni=1 [(xi - ͞x)2 ÷ n]
En esta fórmula, n representa los puntos de datos totales, ͞x representa la media de los puntos de datos y x i representa los puntos de datos individuales.
- (iii) Dispersión:
es una medida de dispersión de un conjunto de datos de su media.σ= √
- (i) Rango:
2. Estadísticas
inferenciales: las estadísticas inferenciales hacen inferencias y predicciones sobre la población en función de una muestra de datos tomados de la población. Generaliza un gran conjunto de datos y aplica probabilidades para sacar una conclusión. Simplemente se usa para explicar el significado de las estadísticas descriptivas. Simplemente se utiliza para analizar, interpretar resultados y sacar conclusiones. La Estadística Inferencial está principalmente relacionada y asociada con la prueba de hipótesis cuyo principal objetivo es rechazar la hipótesis nula.
La prueba de hipótesis es un tipo de procedimiento inferencial que toma la ayuda de datos de muestra para evaluar y evaluar la credibilidad de una hipótesis sobre una población. Las estadísticas inferenciales generalmente se usan para determinar qué tan fuerte es la relación dentro de la muestra. Pero es muy difícil obtener una lista de población y extraer una muestra aleatoria.
Las estadísticas inferenciales se pueden hacer con la ayuda de varios pasos como se indica a continuación:
- Obtener y comenzar con una teoría.
- Generar una hipótesis de investigación.
- Operacionalizar o usar variables
- Identificar o averiguar población a la que podamos aplicar material de estudio.
- Genere o forme una hipótesis nula para esta población.
- Recopile y reúna una muestra de niños de la población y simplemente realice el estudio.
- Luego, realice todas las pruebas estadísticas para aclarar si las características obtenidas de la muestra son lo suficientemente diferentes de lo que se esperaría bajo la hipótesis nula para que podamos encontrar y rechazar la hipótesis nula.
Tipos de estadísticas inferenciales:
hoy en día se utilizan ampliamente varios tipos de estadísticas inferenciales y son muy fáciles de interpretar. Estos se dan a continuación:
- Prueba de diferencia de una muestra/Prueba de hipótesis de una muestra
- Intervalo de confianza
- Tablas de contingencia y estadística chi-cuadrado
- Prueba T o Anova
- correlación de Pearson
- Regresión bivariada
- Regresión multivariada
Publicación traducida automáticamente
Artículo escrito por madhurihammad y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA