¿Qué son las máquinas de vectores de soporte? Support Vector Machine (SVM) es un algoritmo de aprendizaje automático supervisado relativamente simple que se utiliza para la clasificación y/o la regresión. Se prefiere más para la clasificación, pero a veces también es muy útil para la regresión. Básicamente, SVM encuentra un hiperplano que crea un límite entre los tipos de datos. En el espacio bidimensional, este hiperplano no es más que una línea. En SVM, trazamos cada elemento de datos en el conjunto de datos en un espacio N-dimensional, donde N es el número de características/atributos en los datos. A continuación, encuentre el hiperplano óptimo para separar los datos. Entonces, con esto, debe haber entendido que inherentemente, SVM solo puede realizar una clasificación binaria (es decir, elegir entre dos clases). Sin embargo, hay varias técnicas para usar en problemas multiclase.Máquina de vectores de soporte para problemas de clases múltiples Para realizar SVM en problemas de clases múltiples, podemos crear un clasificador binario para cada clase de datos. Los dos resultados de cada clasificador serán:
- El punto de datos pertenece a esa clase O
- El punto de datos no pertenece a esa clase.
Por ejemplo, en una clase de frutas, para realizar una clasificación multiclase, podemos crear un clasificador binario para cada fruta. Por ejemplo, la clase ‘mango’, habrá un clasificador binario para predecir si ES un mango O NO es un mango. El clasificador con la puntuación más alta se elige como salida del SVM. SVM para datos complejos (no separables linealmente) SVM funciona muy bien sin ninguna modificación para datos separables linealmente. Los datos separables linealmente son cualquier dato que se puede trazar en un gráfico y se puede separar en clases usando una línea recta.
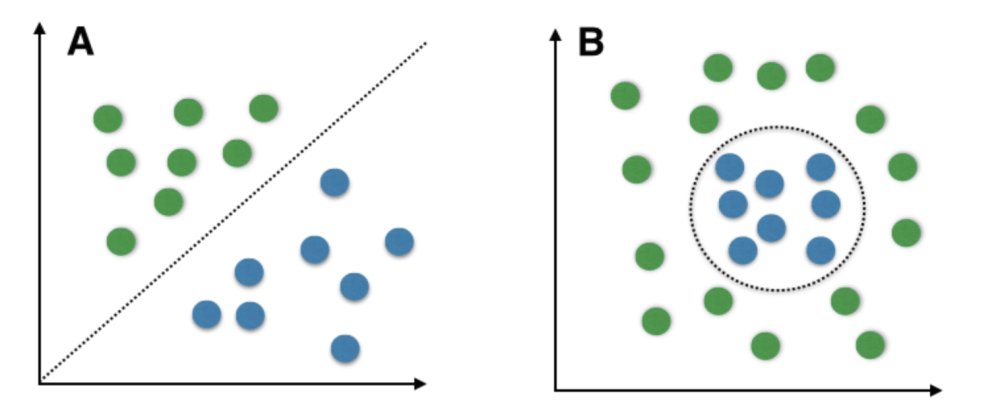
A: Datos separables linealmente B: Datos separables no lineales
Usamos SVM kernelizado para datos separables no lineales. Digamos que tenemos algunos datos separables no linealmente en una dimensión. Podemos transformar estos datos en dos dimensiones y los datos se volverán linealmente separables en dos dimensiones. Esto se hace asignando cada punto de datos 1-D a un par ordenado 2-D correspondiente. Entonces, para cualquier dato separable no linealmente en cualquier dimensión, podemos asignar los datos a una dimensión superior y luego hacerlos separables linealmente. Esta es una transformación muy poderosa y general. Un kernel no es más que una medida de similitud entre puntos de datos. La función del núcleoen un SVM kernelizado le dice que, dados dos puntos de datos en el espacio de características original, cuál es la similitud entre los puntos en el espacio de características recién transformado. Hay varias funciones del kernel disponibles, pero dos son muy populares:
- Núcleo de función de base radial (RBF): la similitud entre dos puntos en el espacio de características transformado es una función que decae exponencialmente de la distancia entre los vectores y el espacio de entrada original, como se muestra a continuación. RBF es el núcleo predeterminado utilizado en SVM.

- Núcleo polinomial: el núcleo polinomial toma un parámetro adicional, «grado» que controla la complejidad del modelo y el costo computacional de la transformación
Un hecho muy interesante es que SVM en realidad no tiene que realizar esta transformación real en los puntos de datos al nuevo espacio de características de alta dimensión. Esto se llama el truco del núcleo . El truco del kernel: internamente, la SVM kernelizada puede calcular estas transformaciones complejas solo en términos de cálculos de similitud entre pares de puntos en el espacio de características de mayor dimensión donde la representación de características transformadas está implícita. Esta función de similitud, que matemáticamente es una especie de producto escalar complejo, es en realidad el núcleo de una SVM kernelizada. Esto hace que sea práctico aplicar SVM cuando el espacio de características subyacente es complejo o incluso de dimensión infinita. El truco del kernel en sí es bastante complejo y está más allá del alcance de este artículo.Parámetros importantes en Kernelized SVC (Clasificador de vectores de soporte)
- El kernel : el kernel se selecciona en función del tipo de datos y también del tipo de transformación. De forma predeterminada, el kernel es Radial Basis Function Kernel (RBF).
- Gamma : este parámetro decide qué tan lejos llega la influencia de un solo ejemplo de entrenamiento durante la transformación, lo que a su vez afecta qué tan ajustados los límites de decisión terminan rodeando los puntos en el espacio de entrada. Si hay un valor pequeño de gamma, los puntos más alejados se consideran similares. Por lo tanto, se agrupan más puntos y tienen límites de decisión más suaves (quizás menos precisos). Los valores más grandes de gamma hacen que los puntos estén más juntos (pueden causar un sobreajuste).
- El parámetro ‘C’ : este parámetro controla la cantidad de regularización aplicada a los datos. Los valores grandes de C significan una baja regularización que, a su vez, hace que los datos de entrenamiento se ajusten muy bien (pueden provocar un sobreajuste). Los valores más bajos de C significan una mayor regularización, lo que hace que el modelo sea más tolerante a los errores (puede dar lugar a una menor precisión).
Ventajas de SVM kernelizado:
- Se desempeñan muy bien en una variedad de conjuntos de datos.
- Son versátiles: se pueden especificar diferentes funciones del núcleo o también se pueden definir núcleos personalizados para tipos de datos específicos.
- Funcionan bien para datos dimensionales altos y bajos.
Contras de SVM kernelizado:
- La eficiencia (tiempo de ejecución y uso de memoria) disminuye a medida que aumenta el tamaño del conjunto de entrenamiento.
- Necesita una cuidadosa normalización de los datos de entrada y ajuste de parámetros.
- No proporciona un estimador de probabilidad directo.
- Difícil de interpretar por qué se hizo una predicción.
Ejemplo
Python3
import numpy as np
from sklearn.datasets import make_classification
from sklearn import svm
from sklearn.model_selection import train_test_split
classes = 4
X,t= make_classification(100, 5, n_classes = classes, random_state= 40, n_informative = 2, n_clusters_per_class = 1)
#%%
X_train, X_test, y_train, y_test= train_test_split(X, t , test_size=0.50)
#%%
model = svm.SVC(kernel = 'linear', random_state = 0, C=1.0)
#%%
model.fit(X_train, y_train)
#%%
y=model.predict(X_test)
y2=model.predict(X_train)
#%%
from sklearn.metrics import accuracy_score
score =accuracy_score(y, y_test)
print(score)
score2 =accuracy_score(y2, y_train)
print(score2)
#%%
import matplotlib.pyplot as plt
color = ['black' if c == 0 else 'lightgrey' for c in y]
plt.scatter(X_train[:,0], X_train[:,1], c=color)
# Create the hyperplane
w = model.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(-2.5, 2.5)
yy = a * xx - (model.intercept_[0]) / w[1]
# Plot the hyperplane
plt.plot(xx, yy)
plt.axis("off"), plt.show();
Conclusión: ahora que conoce los conceptos básicos de cómo funciona un SVM, puede ir al siguiente enlace para aprender cómo implementar SVM para clasificar elementos usando Python: https://www.geeksforgeeks.org/classifying-data-using-support -máquinas vectoriales svms-en-python/
Publicación traducida automáticamente
Artículo escrito por alokesh985 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA