En los últimos años se han producido grandes avances en el campo del procesamiento y reconocimiento de imágenes. Las redes neuronales profundas son cada vez más profundas y complejas. Se ha demostrado que agregar más capas a una red neuronal puede hacerla más robusta para tareas relacionadas con imágenes. Pero también puede hacer que pierdan precisión. Ahí es donde entran en juego las Redes Residuales.
La tendencia de agregar tantas capas por parte de los profesionales del aprendizaje profundo es extraer características importantes de imágenes complejas. Por lo tanto, las primeras capas pueden detectar bordes y las capas posteriores al final pueden detectar formas reconocibles, como las llantas de un automóvil. Pero si añadimos más de 30 capas a la red, su rendimiento se resiente y alcanza una precisión baja. Esto es contrario a la idea de que la adición de capas mejorará una red neuronal. Esto no se debe a un sobreajuste, porque en ese caso, uno puede usar técnicas de abandono y regularización para resolver el problema por completo. Está presente principalmente debido al popular problema del gradiente de fuga .
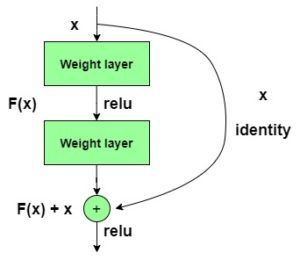
y = F(x) + x
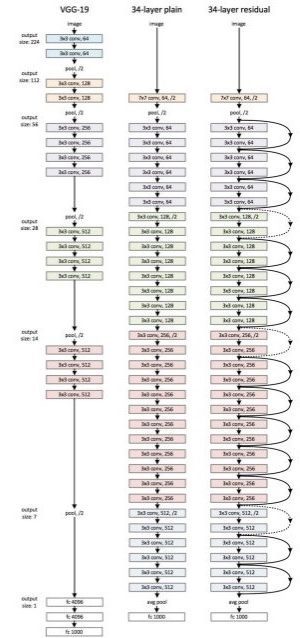
El modelo ResNet152 con 152 capas ganó la prueba ILSVRC Imagenet 2015 y tenía menos parámetros que la red VGG19 , que era muy popular en ese momento. Una red residual consta de unidades o bloques residuales que tienen conexiones de salto , también llamadas conexiones de identidad .
Las conexiones de salto se muestran a continuación:

La salida de la capa anterior se agrega a la salida de la capa posterior en el bloque residual. El salto o salto podría ser 1, 2 o incluso 3 . Al sumar, las dimensiones de x pueden ser diferentes a las de F(x) debido al proceso de convolución, resultando en una reducción de sus dimensiones. Por lo tanto, agregamos una capa de convolución adicional de 1 x 1 para cambiar las dimensiones de x .
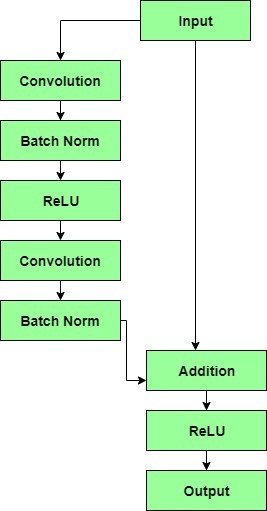
Un bloque residual tiene una capa de convolución de 3 x 3 seguida de una capa de normalización por lotes y una función de activación de ReLU. Esto continúa nuevamente con una capa de convolución de 3 x 3 y una capa de normalización por lotes. La conexión de omisión básicamente omite ambas capas y las agrega directamente antes de la función de activación de ReLU. Dichos bloques residuales se repiten para formar una red residual.
Después de realizar una comparación en profundidad de todas las arquitecturas CNN actuales, ResNet se destacó al mantener la tasa de error más baja del 5 % superior en 3,57 % para las tareas de clasificación, superando a todas las demás arquitecturas. Incluso los humanos no tienen tasas de error mucho más bajas.
Comparación de ResNet de 34 capas con VGG19 y una red simple de 34 capas:
Para concluir, se puede decir que las redes residuales se han vuelto bastante populares para tareas de clasificación y reconocimiento de imágenes debido a su capacidad para resolver gradientes de desaparición y explosión al agregar más capas a una red neuronal ya profunda. Una ResNet con mil capas no tiene mucho uso práctico a partir de ahora.
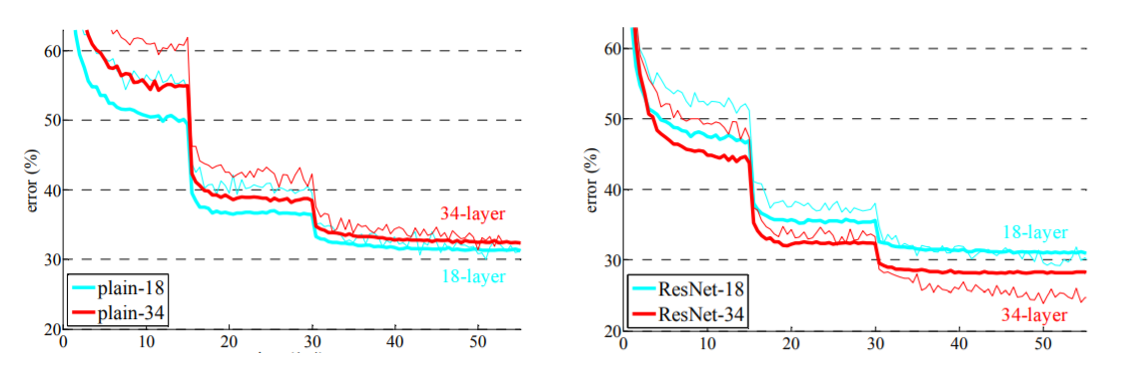
Los gráficos a continuación comparan las precisiones de una red simple con la de una red residual. Tenga en cuenta que con el aumento de las capas , la precisión de una red simple de 34 capas comienza a saturarse antes que la precisión de ResNet.
Publicación traducida automáticamente
Artículo escrito por JaideepSinghSandhu y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA