- El algoritmo del árbol de decisiones cae dentro de la categoría de aprendizaje supervisado. Se pueden utilizar para resolver problemas de regresión y clasificación.
- El árbol de decisión utiliza la representación del árbol para resolver el problema en el que cada Node hoja corresponde a una etiqueta de clase y los atributos se representan en el Node interno del árbol.
- Podemos representar cualquier función booleana en atributos discretos usando el árbol de decisión.
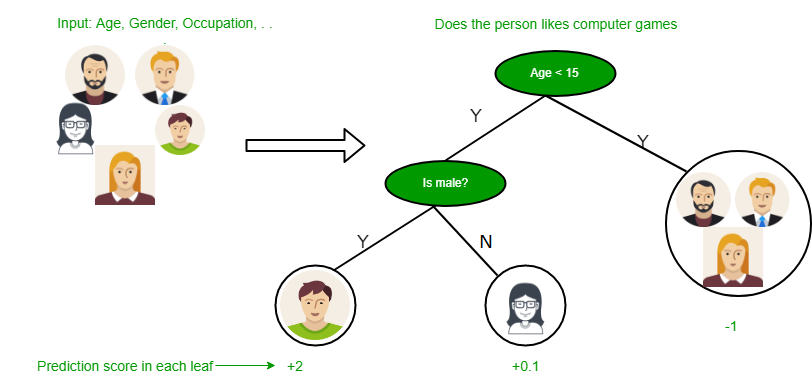

A continuación se presentan algunas suposiciones que hicimos al usar el árbol de decisión:
- Al principio, consideramos todo el conjunto de entrenamiento como la raíz.
- Se prefiere que los valores de característica sean categóricos. Si los valores son continuos, se discretizan antes de construir el modelo.
- Sobre la base de los valores de los atributos, los registros se distribuyen recursivamente.
- Usamos métodos estadísticos para ordenar atributos como raíz o el Node interno.
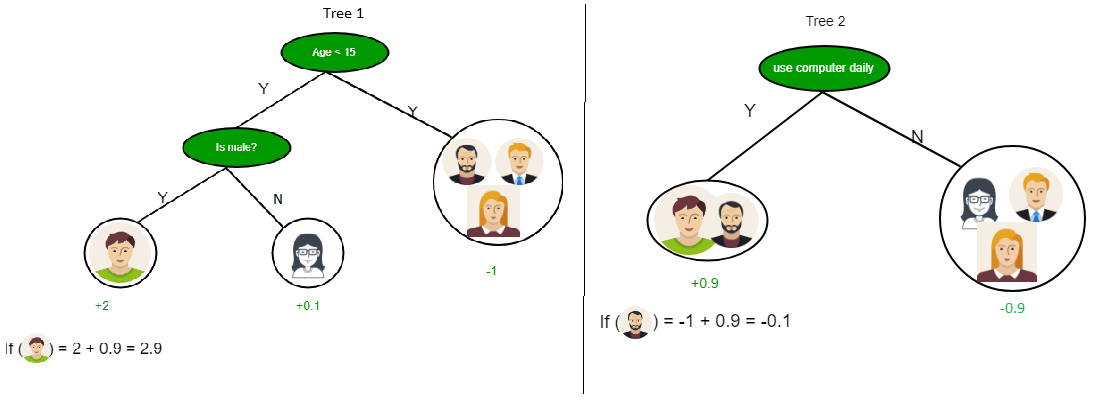
Como puede ver en la imagen de arriba, el árbol de decisiones funciona en la forma de suma de productos, que también se conoce como forma normal disyuntiva . En la imagen de arriba, estamos prediciendo el uso de la computadora en la vida diaria de las personas.
En Decision Tree, el mayor desafío es la identificación del atributo para el Node raíz en cada nivel. Este proceso se conoce como selección de atributos. Tenemos dos medidas populares de selección de atributos:
- Ganancia de información
- Índice Gini
1. Ganancia de información
Cuando usamos un Node en un árbol de decisión para dividir las instancias de entrenamiento en subconjuntos más pequeños, la entropía cambia. La ganancia de información es una medida de este cambio en la entropía.
Definición : supongamos que S es un conjunto de instancias, A es un atributo, S v es el subconjunto de S con A = v y Values (A) es el conjunto de todos los valores posibles de A, entonces
Entropía La
entropía es la medida de incertidumbre de una variable aleatoria, caracteriza la impureza de una colección arbitraria de ejemplos. A mayor entropía mayor contenido de información.
Definición : supongamos que S es un conjunto de instancias, A es un atributo, S v es el subconjunto de S con A = v y Values (A) es el conjunto de todos los valores posibles de A, entonces
Ejemplo:
For the set X = {a,a,a,b,b,b,b,b}
Total instances: 8
Instances of b: 5
Instances of a: 3
![Entropy H(X) = -\left [ \left ( \frac{3}{8} \right )log_{2}\frac{3}{8} + \left ( \frac{5}{8} \right )log_{2}\frac{5}{8} \right ]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-4b2ec6c432a20a955f66ed0da0c5ad3e_l3.png "Rendered by QuickLaTeX.com") = -[0.375 * (-1.415) + 0.625 * (-0.678)]
=-(-0.53-0.424)
= 0.954
= -[0.375 * (-1.415) + 0.625 * (-0.678)]
=-(-0.53-0.424)
= 0.954
Creación de un árbol de decisión utilizando la ganancia de información
Los elementos esenciales:
- Comience con todas las instancias de capacitación asociadas con el Node raíz
- Use la ganancia de información para elegir con qué atributo etiquetar cada Node
- Nota: ninguna ruta de raíz a hoja debe contener el mismo atributo discreto dos veces
- Construya recursivamente cada subárbol en el subconjunto de instancias de entrenamiento que se clasificarían en esa ruta en el árbol.
- Si quedan todas las instancias de entrenamiento positivas o negativas, etiquete ese Node como «sí» o «no» según corresponda.
- Si no quedan atributos, etiquete con un voto mayoritario de las instancias de capacitación que quedan en ese Node
- Si no quedan instancias, etiquete con un voto mayoritario de las instancias de capacitación de los padres
Los casos fronterizos:
Ejemplo:
ahora, dibujemos un árbol de decisión para los siguientes datos utilizando la ganancia de información.
Conjunto de entrenamiento: 3 funciones y 2 clases
| X | Y | Z | C |
|---|---|---|---|
| 1 | 1 | 1 | yo |
| 1 | 1 | 0 | yo |
| 0 | 0 | 1 | II |
| 1 | 0 | 0 | II |
Aquí, tenemos 3 características y 2 clases de salida.
Para construir un árbol de decisión utilizando la ganancia de información. Tomaremos cada una de las funciones y calcularemos la información para cada función.
Dividir en función X
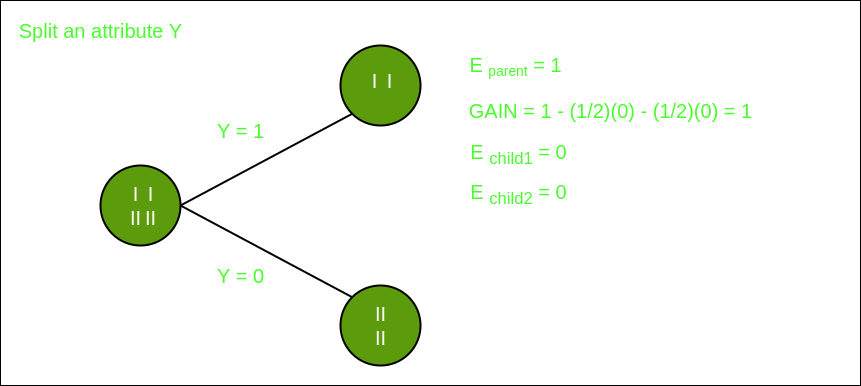
Dividir en función Y
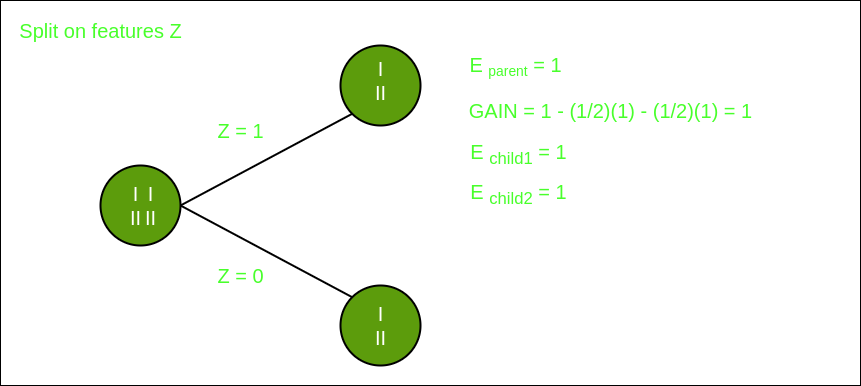
Dividir en función Z
En las imágenes anteriores, podemos ver que la ganancia de información es máxima cuando hacemos una división en la característica Y. Entonces, para el Node raíz, la característica más adecuada es la característica Y. Ahora podemos ver que al dividir el conjunto de datos por característica Y, el niño contiene un subconjunto puro de la variable de destino. Por lo tanto, no necesitamos dividir aún más el conjunto de datos.
El árbol final para el conjunto de datos anterior se vería así: 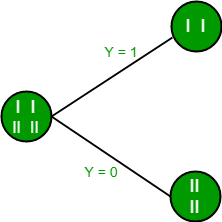
2. Índice de Gini
- El índice Gini es una métrica para medir la frecuencia con la que un elemento elegido al azar se identificaría incorrectamente.
- Significa que se debe preferir un atributo con un índice de Gini más bajo.
- Sklearn admite los criterios «Gini» para el índice Gini y, de forma predeterminada, toma el valor «gini».
- La fórmula para el cálculo del índice de Gini se proporciona a continuación.

Ejemplo:
Consideremos el conjunto de datos en la imagen a continuación y dibujemos un árbol de decisión usando el índice Gini.
| Índice | A | B | C | D | mi |
|---|---|---|---|---|---|
| 1 | 4.8 | 3.4 | 1.9 | 0.2 | positivo |
| 2 | 5 | 3 | 1.6 | 1.2 | positivo |
| 3 | 5 | 3.4 | 1.6 | 0.2 | positivo |
| 4 | 5.2 | 3.5 | 1.5 | 0.2 | positivo |
| 5 | 5.2 | 3.4 | 1.4 | 0.2 | positivo |
| 6 | 4.7 | 3.2 | 1.6 | 0.2 | positivo |
| 7 | 4.8 | 3.1 | 1.6 | 0.2 | positivo |
| 8 | 5.4 | 3.4 | 1.5 | 0.4 | positivo |
| 9 | 7 | 3.2 | 4.7 | 1.4 | negativo |
| 10 | 6.4 | 3.2 | 4.7 | 1.5 | negativo |
| 11 | 6.9 | 3.1 | 4.9 | 1.5 | negativo |
| 12 | 5.5 | 2.3 | 4 | 1.3 | negativo |
| 13 | 6.5 | 2.8 | 4.6 | 1.5 | negativo |
| 14 | 5.7 | 2.8 | 4.5 | 1.3 | negativo |
| 15 | 6.3 | 3.3 | 4.7 | 1.6 | negativo |
| dieciséis | 4.9 | 2.4 | 3.3 | 1 | negativo |
En el conjunto de datos anterior, hay 5 atributos de los cuales el atributo E es la función de predicción que contiene 2 clases (positivas y negativas). Tenemos una proporción igual para ambas clases.
En el Índice Gini, tenemos que elegir algunos valores aleatorios para categorizar cada atributo. Estos valores para este conjunto de datos son:
A B C D >= 5 >= 3.0 >= 4.2 >= 1.4 < 5 < 3.0 < 4.2 < 1.4
Cálculo del índice de Gini para Var A:
Valor >= 5: 12
Atributo A >= 5 & clase = positivo: 
Atributo A >= 5 & clase = negativo: 
Gini(5, 7) = 1 – ![\left [ \left ( \frac{5}{12} \right )^{2} + \left ( \frac{7}{12} \right )^{2}\right ] = 0.4860](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-9e4da24121695bf83629d453d625b97a_l3.png "Rendered by QuickLaTeX.com")
Valor < 5: 4
Atributo A < 5 & clase = positivo: 
Atributo A < 5 & clase = negativo: 
Gini(3, 1) = 1 – ![\left [ \left ( \frac{3}{4} \right )^{2} + \left ( \frac{1}{4} \right )^{2}\right ] = 0.375](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-cd839511a4c9b5d7a8253d8b21cb5e5a_l3.png "Rendered by QuickLaTeX.com")
Agregando peso y sumando cada uno de los índices de Gini:
Cálculo del índice de Gini para Var B:
Valor >= 3: 12
Atributo B >= 3 & clase = positivo: 
Atributo B >= 5 & clase = negativo: 
Gini(5, 7) = 1 – ![\left [ \left ( \frac{8}{12} \right )^{2} + \left ( \frac{4}{12} \right )^{2}\right ] = 0.4460](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-e51ae059395978963276fb4824fdd76e_l3.png "Rendered by QuickLaTeX.com")
Valor < 3: 4
Atributo A < 3 & clase = positivo: 
Atributo A < 3 & clase = negativo: 
Gini(3, 1) = 1 – ![\left [ \left ( \frac{0}{4} \right )^{2} + \left ( \frac{4}{4} \right )^{2}\right ] = 1](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-f9a8e3f184b7cbcf5ff48ae37a627a98_l3.png "Rendered by QuickLaTeX.com")
Agregando peso y sumando cada uno de los índices de Gini:
Usando el mismo enfoque podemos calcular el índice de Gini para los atributos C y D.
Positive Negative
For A|>= 5.0 5 7
|<5 3 1
Ginin Index of A = 0.45825
Positive Negative
For B|>= 3.0 8 4
|< 3.0 0 4
Gini Index of B= 0.3345
Positive Negative
For C|>= 4.2 0 6
|< 4.2 8 2
Gini Index of C= 0.2
Positive Negative
For D|>= 1.4 0 5
|< 1.4 8 3
Gini Index of D= 0.273
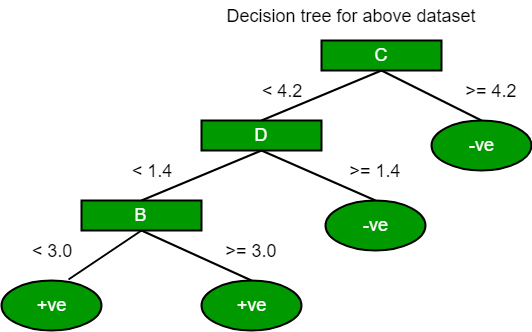
Los tipos más notables de algoritmos de árboles de decisión son: –
1. Dichotomizador iterativo 3 (ID3): este algoritmo utiliza la ganancia de información para decidir qué atributo se utilizará para clasificar el subconjunto actual de datos. Para cada nivel del árbol, la ganancia de información se calcula recursivamente para los datos restantes.
2. C4.5: Este algoritmo es el sucesor del algoritmo ID3. Este algoritmo utiliza la ganancia de información o la relación de ganancia para decidir sobre el atributo de clasificación. Es una mejora directa del algoritmo ID3, ya que puede manejar valores de atributos continuos y faltantes.
3. Árbol de clasificación y regresión (CART): es un algoritmo de aprendizaje dinámico que puede producir un árbol de regresión y un árbol de clasificación según la variable dependiente.
Referencia: aspirante de datos
Publicación traducida automáticamente
Artículo escrito por Abhishek Sharma 44 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA