Prerrequisitos: Técnicas de optimización en Gradient Descent
Adam optimizador
Adaptive Moment Estimation es un algoritmo para la técnica de optimización del descenso de gradiente. El método es realmente eficiente cuando se trabaja con un gran problema que involucra una gran cantidad de datos o parámetros. Requiere menos memoria y es eficiente. Intuitivamente, es una combinación del algoritmo de ‘descenso de gradiente con impulso’ y el algoritmo ‘RMSP’.
¿Cómo funciona Adán?
El optimizador de Adam implica una combinación de dos metodologías de descenso de gradiente:
Impulso:
Este algoritmo se utiliza para acelerar el algoritmo de descenso del gradiente teniendo en cuenta el «promedio ponderado exponencialmente» de los gradientes. El uso de promedios hace que el algoritmo converja hacia los mínimos a un ritmo más rápido.

dónde,
![m_{t}=\beta m_{t-1}+(1-\beta)\left[\frac{\delta L}{\delta w_{t}}\right]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-11485c48aad57c3897036904bff90924_l3.png "Rendered by QuickLaTeX.com")
mt = aggregate of gradients at time t [current] (initially, mt = 0) mt-1 = aggregate of gradients at time t-1 [previous] Wt = weights at time t Wt+1 = weights at time t+1 αt = learning rate at time t ∂L = derivative of Loss Function ∂Wt = derivative of weights at time t β = Moving average parameter (const, 0.9)
Propagación de raíz cuadrática media (RMSP):
Root mean square prop o RMSprop es un algoritmo de aprendizaje adaptativo que intenta mejorar AdaGrad. En lugar de tomar la suma acumulada de gradientes cuadrados como en AdaGrad, toma el ‘promedio móvil exponencial’.
![w_{t+1}=w_{t}-\frac{\alpha_{t}}{\left(v_{t}+\varepsilon\right)^{1 / 2}} *\left[\frac{\delta L}{\delta w_{t}}\right]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-c1f05c2b4b465f8fec637fc731d8777e_l3.png "Rendered by QuickLaTeX.com")
dónde,
![v_{t}=\beta v_{t-1}+(1-\beta) *\left[\frac{\delta L}{\delta w_{t}}\right]^{2}](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-a2ad3f644ee1350b15ae1675fc757338_l3.png "Rendered by QuickLaTeX.com")
Wt = weights at time t Wt+1 = weights at time t+1 αt = learning rate at time t ∂L = derivative of Loss Function ∂Wt = derivative of weights at time t Vt = sum of square of past gradients. [i.e sum(∂L/∂Wt-1)] (initially, Vt = 0) β = Moving average parameter (const, 0.9) ϵ = A small positive constant (10-8)
NOTA: El tiempo (t) podría interpretarse como una iteración (i) .
Adam Optimizer hereda las fortalezas o los atributos positivos de los dos métodos anteriores y se basa en ellos para brindar un descenso de gradiente más optimizado.
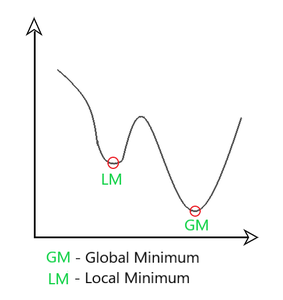
Aquí, controlamos la tasa de descenso del gradiente de tal manera que hay una oscilación mínima cuando alcanza el mínimo global mientras toma pasos lo suficientemente grandes (tamaño de paso) para pasar los obstáculos mínimos locales en el camino. Por lo tanto, combina las características de los métodos anteriores para alcanzar el mínimo global de manera eficiente.
Aspecto matemático de Adam Optimizer
Tomando las fórmulas utilizadas en los dos métodos anteriores, obtenemos
![m_{t}=\beta_{1} m_{t-1}+\left(1-\beta_{1}\right)\left[\frac{\delta L}{\delta w_{t}}\right] v_{t}=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right)\left[\frac{\delta L}{\delta w_{t}}\right]^{2}](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-30ada136b73bc4f46bdbb2cec115c84f_l3.png "Rendered by QuickLaTeX.com")
Parameters Used : 1. ϵ = a small +ve constant to avoid 'division by 0' error when (vt -> 0). (10-8) 2. β1 & β2 = decay rates of average of gradients in the above two methods. (β1 = 0.9 & β2 = 0.999) 3. α — Step size parameter / learning rate (0.001)
Dado que m t y v t se han inicializado como 0 (basado en los métodos anteriores), se observa que tienen una tendencia a estar ‘sesgados hacia 0’ ya que tanto β 1 como β 2 ≈ 1. Este optimizador soluciona este problema al calculando m t y v t ‘corregidos por sesgo’ . Esto también se hace para controlar los pesos mientras se alcanza el mínimo global para evitar altas oscilaciones cuando se está cerca de él. Las fórmulas utilizadas son:

Intuitivamente, nos estamos adaptando al descenso del gradiente después de cada iteración para que permanezca controlado e imparcial durante todo el proceso, de ahí el nombre Adam.
Ahora, en lugar de nuestros parámetros de peso normales m t y v t , tomamos los parámetros de peso con corrección de sesgo (m_hat) t y (v_hat) t . Poniéndolos en nuestra ecuación general, obtenemos

Actuación:
Sobre la base de las fortalezas de los modelos anteriores, el optimizador de Adam brinda un rendimiento mucho mayor que el utilizado anteriormente y los supera por un gran margen al brindar un descenso de gradiente optimizado. El gráfico que se muestra a continuación muestra claramente cómo Adam Optimizer supera al resto del optimizador por un margen considerable en términos de costo de capacitación (bajo) y rendimiento (alto).
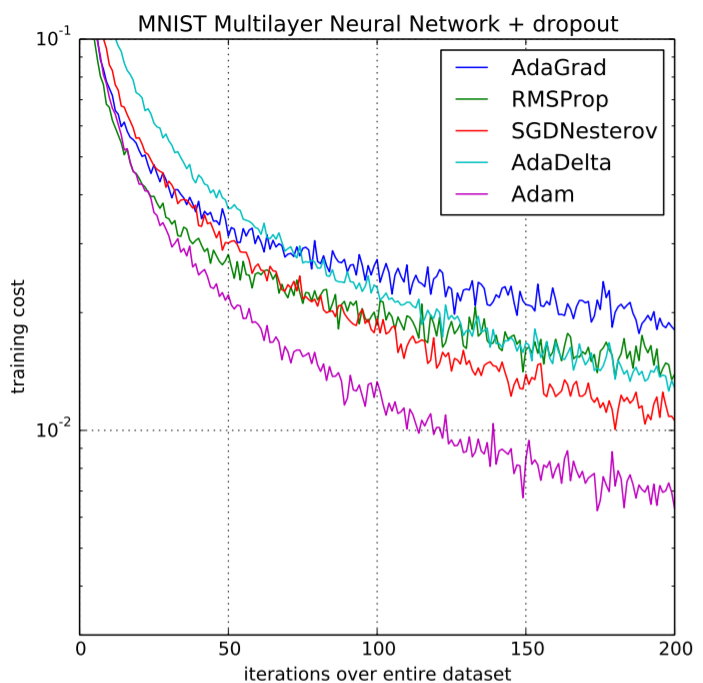
Comparación de rendimiento en el costo de capacitación
Publicación traducida automáticamente
Artículo escrito por prakharr0y y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA