Cómo funciona ? K-vecinos más cercanoses uno de los algoritmos de clasificación más básicos pero esenciales en Machine Learning. Pertenece al dominio de aprendizaje supervisado y encuentra una intensa aplicación en el reconocimiento de patrones, minería de datos y detección de intrusos. El algoritmo K-Nearest Neighbors (KNN) es un algoritmo de aprendizaje automático supervisado simple y fácil de implementar que se puede usar para resolver problemas de clasificación y regresión. El algoritmo KNN asume que existen cosas similares muy cerca. En otras palabras, las cosas similares están cerca unas de otras. KNN captura la idea de similitud (a veces llamada distancia, proximidad o cercanía) con algunas matemáticas que podríamos haber aprendido en nuestra infancia: calcular la distancia entre puntos en un gráfico. Hay otras formas de calcular la distancia, y una forma podría ser preferible según el problema que estemos resolviendo. Sin embargo, la distancia en línea recta (también llamada distancia euclidiana) es una opción popular y familiar. Es ampliamente disponible en escenarios de la vida real ya que no es paramétrico, lo que significa que no hace suposiciones subyacentes sobre la distribución de datos (a diferencia de otros algoritmos como GMM, que asume una distribución gaussiana de los datos dados) .Este artículo muestra una ilustración de K-vecinos más cercanos en una muestra de datos aleatorios usando la biblioteca sklearn .
Requisitos previos : Numpy , Pandas , matplotlib , sklearn Nos han dado un conjunto de datos aleatorios con una característica como clases de destino. Intentaremos usar KNN para crear un modelo que prediga directamente una clase para un nuevo punto de datos basado en las características.
Importar bibliotecas:
Python3
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import numpy as np
Primero visualicemos nuestros datos con funciones múltiples.
Obtenga los datos: configure index_col=0 para usar la primera columna como índice.
Python3
df = pd.read_csv("Data", index_col = 0)
df.head()
Resultado: 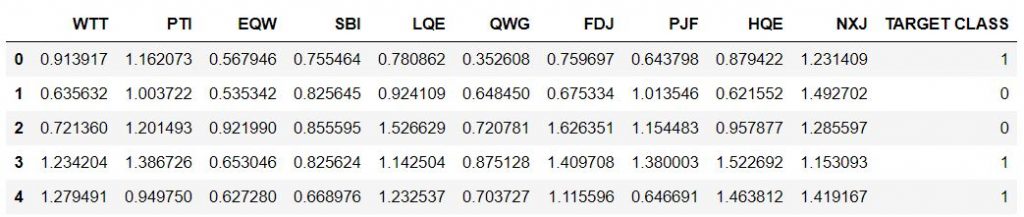 estandarizar las variables: debido a que el clasificador KNN predice la clase de una observación de prueba dada al identificar las observaciones más cercanas, la escala de las variables es importante. Cualquier variable que esté a gran escala tendrá un efecto mucho mayor en la distancia entre las observaciones y, por lo tanto, en el clasificador KNN que las variables que estén a pequeña escala.
estandarizar las variables: debido a que el clasificador KNN predice la clase de una observación de prueba dada al identificar las observaciones más cercanas, la escala de las variables es importante. Cualquier variable que esté a gran escala tendrá un efecto mucho mayor en la distancia entre las observaciones y, por lo tanto, en el clasificador KNN que las variables que estén a pequeña escala.
Python3
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(df.drop('TARGET CLASS', axis = 1))
scaled_features = scaler.transform(df.drop('TARGET CLASS', axis = 1))
df_feat = pd.DataFrame(scaled_features, columns = df.columns[:-1])
df_feat.head()
Salida: 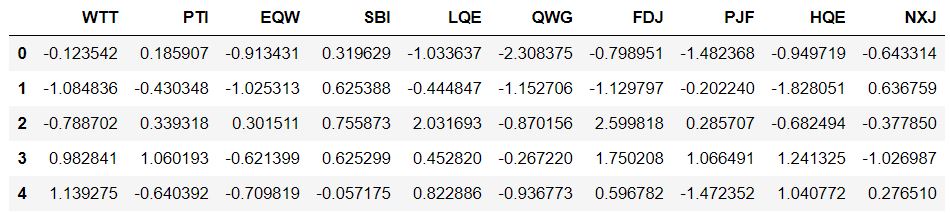 entrenar datos divididos de prueba y usar el modelo KNN de la biblioteca sklearn:
entrenar datos divididos de prueba y usar el modelo KNN de la biblioteca sklearn:
Python3
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( scaled_features, df['TARGET CLASS'], test_size = 0.30) # Remember that we are trying to come up # with a model to predict whether # someone will TARGET CLASS or not. # We'll start with k = 1. from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors = 1) knn.fit(X_train, y_train) pred = knn.predict(X_test) # Predictions and Evaluations # Let's evaluate our KNN model ! from sklearn.metrics import classification_report, confusion_matrix print(confusion_matrix(y_test, pred)) print(classification_report(y_test, pred))
Producción:
[[133 16]
[ 15 136]]
precision recall f1-score support
0 0.90 0.89 0.90 149
1 0.89 0.90 0.90 151
accuracy 0.90 300
macro avg 0.90 0.90 0.90 300
weighted avg 0.90 0.90 0.90 300
Elegir un valor K : sigamos adelante y usemos el método del codo para elegir un buen valor K
Python3
error_rate = []
# Will take some time
for i in range(1, 40):
knn = KNeighborsClassifier(n_neighbors = i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error_rate.append(np.mean(pred_i != y_test))
plt.figure(figsize =(10, 6))
plt.plot(range(1, 40), error_rate, color ='blue',
linestyle ='dashed', marker ='o',
markerfacecolor ='red', markersize = 10)
plt.title('Error Rate vs. K Value')
plt.xlabel('K')
plt.ylabel('Error Rate')
Salida: 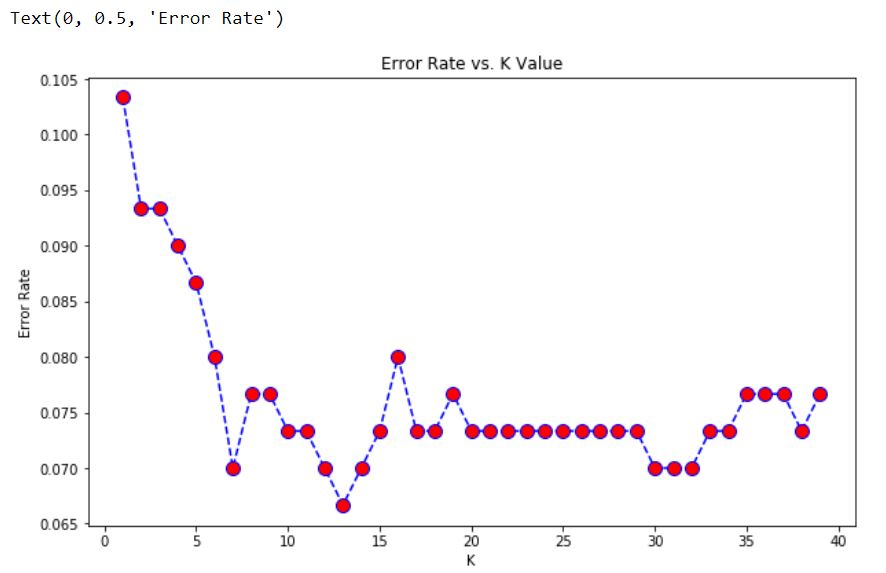 aquí, podemos ver que aproximadamente después de K>15, la tasa de error tiende a oscilar entre 0,07 y 0,08. Volvamos a entrenar el modelo con eso y verifiquemos el informe de clasificación.
aquí, podemos ver que aproximadamente después de K>15, la tasa de error tiende a oscilar entre 0,07 y 0,08. Volvamos a entrenar el modelo con eso y verifiquemos el informe de clasificación.
Python3
# FIRST A QUICK COMPARISON TO OUR ORIGINAL K = 1
knn = KNeighborsClassifier(n_neighbors = 1)
knn.fit(X_train, y_train)
pred = knn.predict(X_test)
print('WITH K = 1')
print('\n')
print(confusion_matrix(y_test, pred))
print('\n')
print(classification_report(y_test, pred))
# NOW WITH K = 15
knn = KNeighborsClassifier(n_neighbors = 15)
knn.fit(X_train, y_train)
pred = knn.predict(X_test)
print('WITH K = 15')
print('\n')
print(confusion_matrix(y_test, pred))
print('\n')
print(classification_report(y_test, pred))
Producción:
WITH K=1
[[133 16]
[ 15 136]]
precision recall f1-score support
0 0.90 0.89 0.90 149
1 0.89 0.90 0.90 151
accuracy 0.90 300
macro avg 0.90 0.90 0.90 300
weighted avg 0.90 0.90 0.90 300
WITH K=15
[[133 16]
[ 6 145]]
precision recall f1-score support
0 0.96 0.89 0.92 149
1 0.90 0.96 0.93 151
accuracy 0.93 300
macro avg 0.93 0.93 0.93 300
weighted avg 0.93 0.93 0.93 300
¡Excelente! Pudimos exprimir un poco más el rendimiento de nuestro modelo ajustando un mejor valor K.
Publicación traducida automáticamente
Artículo escrito por tyagikartik4282 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA