El aprendizaje automático, como su nombre indica, es la ciencia de programar una computadora mediante la cual pueden aprender de diferentes tipos de datos. Una definición más general dada por Arthur Samuel es: «El aprendizaje automático es el campo de estudio que brinda a las computadoras la capacidad de aprender sin ser programadas explícitamente». Por lo general, se utilizan para resolver varios tipos de problemas de la vida.
En los viejos tiempos, las personas solían realizar tareas de aprendizaje automático codificando manualmente todos los algoritmos y fórmulas matemáticas y estadísticas. Esto hizo que el procesamiento fuera lento, tedioso e ineficiente. Pero en los días modernos, se vuelve mucho más fácil y eficiente en comparación con los viejos tiempos con varias bibliotecas, marcos y módulos de Python. Hoy, Python es uno de los lenguajes de programación más populares para esta tarea y ha reemplazado a muchos lenguajes en la industria, una de las razones es su vasta colección de bibliotecas. Las bibliotecas de Python que se utilizan en Machine Learning son:

- entumecido
- Scipy
- Scikit-aprender
- Teano
- TensorFlow
- Keras
- PyTorch
- pandas
- matplotlib
entumecido

NumPy es una biblioteca de Python muy popular para el procesamiento de arrays y arreglos multidimensionales grandes, con la ayuda de una gran colección de funciones matemáticas de alto nivel. Es muy útil para cálculos científicos fundamentales en Machine Learning. Es particularmente útil para el álgebra lineal, la transformada de Fourier y las capacidades de números aleatorios. Las bibliotecas de gama alta como TensorFlow usan NumPy internamente para la manipulación de tensores.
Python3
# Python program using NumPy # for some basic mathematical # operations import numpy as np # Creating two arrays of rank 2 x = np.array([[1, 2], [3, 4]]) y = np.array([[5, 6], [7, 8]]) # Creating two arrays of rank 1 v = np.array([9, 10]) w = np.array([11, 12]) # Inner product of vectors print(np.dot(v, w), "\n") # Matrix and Vector product print(np.dot(x, v), "\n") # Matrix and matrix product print(np.dot(x, y))
Producción:
219 [29 67] [[19 22] [43 50]]
Para obtener más detalles, consulte Numpy .
SciPy

SciPy es una biblioteca muy popular entre los entusiastas del aprendizaje automático, ya que contiene diferentes módulos para optimización, álgebra lineal, integración y estadísticas. Hay una diferencia entre la biblioteca SciPy y la pila SciPy. SciPy es uno de los paquetes principales que componen la pila de SciPy. SciPy también es muy útil para la manipulación de imágenes.
Python3
# Python script using Scipy
# for image manipulation
from scipy.misc import imread, imsave, imresize
# Read a JPEG image into a numpy array
img = imread('D:/Programs / cat.jpg') # path of the image
print(img.dtype, img.shape)
# Tinting the image
img_tint = img * [1, 0.45, 0.3]
# Saving the tinted image
imsave('D:/Programs / cat_tinted.jpg', img_tint)
# Resizing the tinted image to be 300 x 300 pixels
img_tint_resize = imresize(img_tint, (300, 300))
# Saving the resized tinted image
imsave('D:/Programs / cat_tinted_resized.jpg', img_tint_resize)
Imagen original:

Imagen teñida:

Imagen teñida redimensionada:

Para obtener más detalles, consulte la documentación .
Scikit-aprender

Scikit-learn es una de las bibliotecas de ML más populares para algoritmos de ML clásicos. Está construido sobre dos bibliotecas básicas de Python, a saber, NumPy y SciPy. Scikit-learn es compatible con la mayoría de los algoritmos de aprendizaje supervisados y no supervisados. Scikit-learn también se puede usar para la extracción y el análisis de datos, lo que la convierte en una excelente herramienta para quienes comienzan con ML.
Python3
# Python script using Scikit-learn # for Decision Tree Classifier # Sample Decision Tree Classifier from sklearn import datasets from sklearn import metrics from sklearn.tree import DecisionTreeClassifier # load the iris datasets dataset = datasets.load_iris() # fit a CART model to the data model = DecisionTreeClassifier() model.fit(dataset.data, dataset.target) print(model) # make predictions expected = dataset.target predicted = model.predict(dataset.data) # summarize the fit of the model print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Producción:
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
precision recall f1-score support
0 1.00 1.00 1.00 50
1 1.00 1.00 1.00 50
2 1.00 1.00 1.00 50
micro avg 1.00 1.00 1.00 150
macro avg 1.00 1.00 1.00 150
weighted avg 1.00 1.00 1.00 150
[[50 0 0]
[ 0 50 0]
[ 0 0 50]]
Para obtener más detalles, consulte la documentación .
Teano

Todos sabemos que Machine Learning es básicamente matemática y estadística. Theano es una biblioteca popular de Python que se utiliza para definir, evaluar y optimizar expresiones matemáticas que involucran arrays multidimensionales de manera eficiente. Se logra optimizando la utilización de CPU y GPU. Se usa ampliamente para pruebas unitarias y autoverificación para detectar y diagnosticar diferentes tipos de errores. Theano es una biblioteca muy potente que se ha utilizado en proyectos científicos de computación intensiva a gran escala durante mucho tiempo, pero es lo suficientemente simple y accesible como para que las personas la utilicen en sus propios proyectos.
Python3
# Python program using Theano
# for computing a Logistic
# Function
import theano
import theano.tensor as T
x = T.dmatrix('x')
s = 1 / (1 + T.exp(-x))
logistic = theano.function([x], s)
logistic([[0, 1], [-1, -2]])
Producción:
array([[0.5, 0.73105858],
[0.26894142, 0.11920292]])
Para obtener más detalles, consulte la documentación .
TensorFlow

TensorFlow es una biblioteca de código abierto muy popular para computación numérica de alto rendimiento desarrollada por el equipo de Google Brain en Google. Como sugiere el nombre, Tensorflow es un marco que implica definir y ejecutar cálculos que involucran tensores. Puede entrenar y ejecutar redes neuronales profundas que se pueden usar para desarrollar varias aplicaciones de IA. TensorFlow se usa ampliamente en el campo de la investigación y la aplicación del aprendizaje profundo.
Python3
# Python program using TensorFlow # for multiplying two arrays # import `tensorflow` import tensorflow as tf # Initialize two constants x1 = tf.constant([1, 2, 3, 4]) x2 = tf.constant([5, 6, 7, 8]) # Multiply result = tf.multiply(x1, x2) # Initialize the Session sess = tf.Session() # Print the result print(sess.run(result)) # Close the session sess.close()
Producción:
[ 5 12 21 32]
Para obtener más detalles, consulte la documentación .
Keras
![]() It provides many inbuilt methods for groping, combining and filtering data.
It provides many inbuilt methods for groping, combining and filtering data.
Keras es una biblioteca de aprendizaje automático muy popular para Python. Es una API de redes neuronales de alto nivel capaz de ejecutarse sobre TensorFlow, CNTK o Theano. Puede funcionar sin problemas tanto en la CPU como en la GPU. Keras hace que sea realmente para los principiantes de ML construir y diseñar una red neuronal. Una de las mejores cosas de Keras es que permite la creación de prototipos fácil y rápido.
Para obtener más detalles, consulte la documentación .
PyTorch

PyTorch es una biblioteca popular de aprendizaje automático de código abierto para Python basada en Torch, que es una biblioteca de aprendizaje automático de código abierto que se implementa en C con un contenedor en Lua. Tiene una amplia selección de herramientas y bibliotecas compatibles con Computer Vision, Natural Language Processing (NLP) y muchos más programas ML. Permite a los desarrolladores realizar cálculos en tensores con aceleración de GPU y también ayuda a crear gráficos computacionales.
Python3
# Python program using PyTorch
# for defining tensors fit a
# two-layer network to random
# data and calculating the loss
import torch
dtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") Uncomment this to run on GPU
# N is batch size; D_in is input dimension;
# H is hidden dimension; D_out is output dimension.
N, D_in, H, D_out = 64, 1000, 100, 10
# Create random input and output data
x = torch.random(N, D_in, device = device, dtype = dtype)
y = torch.random(N, D_out, device = device, dtype = dtype)
# Randomly initialize weights
w1 = torch.random(D_in, H, device = device, dtype = dtype)
w2 = torch.random(H, D_out, device = device, dtype = dtype)
learning_rate = 1e-6
for t in range(500):
# Forward pass: compute predicted y
h = x.mm(w1)
h_relu = h.clamp(min = 0)
y_pred = h_relu.mm(w2)
# Compute and print loss
loss = (y_pred - y).pow(2).sum().item()
print(t, loss)
# Backprop to compute gradients of w1 and w2 with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# Update weights using gradient descent
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
Producción:
0 47168344.0 1 46385584.0 2 43153576.0 ... ... ... 497 3.987660602433607e-05 498 3.945609932998195e-05 499 3.897604619851336e-05
Para obtener más detalles, consulte la documentación .
pandas

Pandas es una biblioteca popular de Python para el análisis de datos. No está directamente relacionado con el aprendizaje automático. Como sabemos, el conjunto de datos debe estar preparado antes del entrenamiento. En este caso, Pandas es útil ya que fue desarrollado específicamente para la extracción y preparación de datos. Proporciona estructuras de datos de alto nivel y una amplia variedad de herramientas para el análisis de datos. Proporciona muchos métodos incorporados para agrupar, combinar y filtrar datos.
Python3
# Python program using Pandas for
# arranging a given set of data
# into a table
# importing pandas as pd
import pandas as pd
data = {"country": ["Brazil", "Russia", "India", "China", "South Africa"],
"capital": ["Brasilia", "Moscow", "New Delhi", "Beijing", "Pretoria"],
"area": [8.516, 17.10, 3.286, 9.597, 1.221],
"population": [200.4, 143.5, 1252, 1357, 52.98] }
data_table = pd.DataFrame(data)
print(data_table)
Producción:
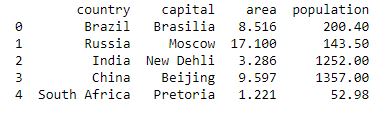
Para obtener más detalles, consulte Pandas .
matplotlib
![]()
Matplotlib es una biblioteca de Python muy popular para la visualización de datos. Al igual que Pandas, no está directamente relacionado con Machine Learning. Es particularmente útil cuando un programador quiere visualizar los patrones en los datos. Es una biblioteca de gráficos 2D que se utiliza para crear gráficos y diagramas 2D. Un módulo llamado pyplot facilita a los programadores el trazado, ya que proporciona funciones para controlar estilos de línea, propiedades de fuente, ejes de formato, etc. Proporciona varios tipos de gráficos y diagramas para la visualización de datos, a saber, histograma, gráficos de error, chats de barra. , etc,
Python3
# Python program using Matplotlib # for forming a linear plot # importing the necessary packages and modules import matplotlib.pyplot as plt import numpy as np # Prepare the data x = np.linspace(0, 10, 100) # Plot the data plt.plot(x, x, label ='linear') # Add a legend plt.legend() # Show the plot plt.show()
Producción:
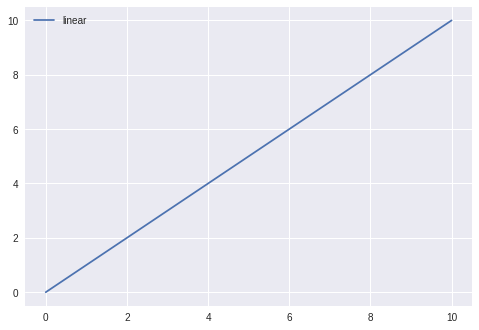
Para obtener más detalles, consulte la documentación .