Self Organizing Map (o Kohonen Map o SOM) es un tipo de red neuronal artificial que también se inspira en modelos biológicos de sistemas neuronales de la década de 1970. Sigue un enfoque de aprendizaje no supervisado y entrenó su red a través de un algoritmo de aprendizaje competitivo. SOM se utiliza para técnicas de agrupación y mapeo (o reducción de dimensionalidad) para mapear datos multidimensionales en dimensiones más bajas, lo que permite a las personas reducir problemas complejos para una fácil interpretación. SOM tiene dos capas, una es la capa de Entrada y la otra es la capa de Salida. La arquitectura del Self Organizing Map con dos clústeres y n características de entrada de cualquier muestra se muestra a continuación:
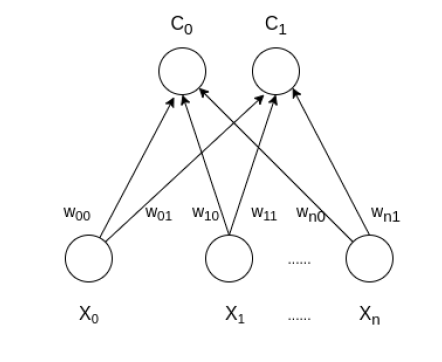
¿Cómo funciona SOM?
Digamos una entrada de datos de tamaño (m, n) donde m es el número de ejemplos de entrenamiento y n es el número de funciones en cada ejemplo. Primero, inicializa los pesos de tamaño (n, C) donde C es el número de grupos. Luego, al iterar sobre los datos de entrada, para cada ejemplo de entrenamiento, actualiza el vector ganador (vector de peso con la distancia más corta (p. ej., distancia euclidiana) del ejemplo de entrenamiento). La regla de actualización de peso viene dada por:
wij = wij(old) + alpha(t) * (xik - wij(old))
donde alfa es una tasa de aprendizaje en el tiempo t, j denota el vector ganador, i denota la i -ésima característica del ejemplo de entrenamiento yk denota el k -ésimo ejemplo de entrenamiento de los datos de entrada. Después de entrenar la red SOM, los pesos entrenados se utilizan para agrupar nuevos ejemplos. Un nuevo ejemplo cae en el grupo de vectores ganadores.
Algoritmo
Los pasos involucrados son:
- Inicialización de peso
- Para 1 a N número de épocas
- Seleccione un ejemplo de entrenamiento
- Calcule el vector ganador
- Actualizar el vector ganador
- Repita los pasos 3, 4, 5 para todos los ejemplos de entrenamiento.
- Agrupación de la muestra de prueba
A continuación se muestra la implementación del enfoque anterior:
Python3
import math
class SOM:
# Function here computes the winning vector
# by Euclidean distance
def winner(self, weights, sample):
D0 = 0
D1 = 0
for i in range(len(sample)):
D0 = D0 + math.pow((sample[i] - weights[0][i]), 2)
D1 = D1 + math.pow((sample[i] - weights[1][i]), 2)
if D0 > D1:
return 0
else:
return 1
# Function here updates the winning vector
def update(self, weights, sample, J, alpha):
for i in range(len(weights)):
weights[J][i] = weights[J][i] + alpha * (sample[i] - weights[J][i])
return weights
# Driver code
def main():
# Training Examples ( m, n )
T = [[1, 1, 0, 0], [0, 0, 0, 1], [1, 0, 0, 0], [0, 0, 1, 1]]
m, n = len(T), len(T[0])
# weight initialization ( n, C )
weights = [[0.2, 0.6, 0.5, 0.9], [0.8, 0.4, 0.7, 0.3]]
# training
ob = SOM()
epochs = 3
alpha = 0.5
for i in range(epochs):
for j in range(m):
# training sample
sample = T[j]
# Compute winner vector
J = ob.winner(weights, sample)
# Update winning vector
weights = ob.update(weights, sample, J, alpha)
# classify test sample
s = [0, 0, 0, 1]
J = ob.winner(weights, s)
print("Test Sample s belongs to Cluster : ", J)
print("Trained weights : ", weights)
if __name__ == "__main__":
main()
la muestra de prueba s pertenece al clúster: 0
Pesos entrenados: [[0.6000000000000001, 0.8, 0.5, 0.9], [0.3333984375, 0.0666015625, 0.7, 0.3]]
Publicación traducida automáticamente
Artículo escrito por mohit baliyan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA