Requisito previo: separación de hiperplanos en SVM
La ecuación del multiplicador de Lagrange para la máquina de vectores de soporte. La ecuación de eso puede estar dada por:
![\underset{\vec{w},b}{min} \underset{\vec{a}\geq 0}{max} \frac{1}{2}\left \| w \right \|^{2} - \sum_{j}a_j\left [ \left ( \vec{w} \cdot \vec{x}_{j} \right )y_j - 1 \right ]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-e3af7b114ae1c6d11097dcf8b453184d_l3.png "Rendered by QuickLaTeX.com")
Ahora, de acuerdo con el principio de dualidad, el problema de optimización anterior puede verse tanto como primario (minimizandob) maximizar
![\underset{\vec{a}\geq 0}{max}\underset{\vec{w},b}{min} \frac{1}{2}\left \| w \right \|^{2} - \sum_{j}a_j\left [ \left ( \vec{w} \cdot \vec{x}_{j} \right )y_j - 1 \right ]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-769d05932d6163e5915c127212c9b757_l3.png "Rendered by QuickLaTeX.com")
La condición de Slater para la optimización convexa garantiza que estos dos son problemas iguales.
Para obtener el valor mínimo de w y b, la derivada parcial de primer orden de estas variables debe ser 0:

Ahora, coloque la ecuación anterior en la ecuación del multiplicador de Lagrange y simplifique.

En la ecuación anterior, el término

porque,
b
es solo una constante y el resto es de la ecuación anterior”

Para encontrar b, también podemos usar la ecuación anterior y la restricción

:

Ahora, la regla de decisión puede estar dada por:

Observe que podemos observar a partir de la regla anterior que el multiplicador de Lagrange solo depende del producto escalar de x i con la variable desconocida x. Este producto escalar se define como la función kernel y se representa por K

Ahora, para el caso linealmente inseparable, la ecuación dual se convierte en:

Aquí, agregamos una constante C, es necesaria por las siguientes razones:
- Impide el valor de


- También evita que los modelos se sobreajusten, lo que significa que se pueden aceptar algunos errores de clasificación.
Imagen que representa la transformación
aplicamos la transformación en otro espacio tal que el siguiente. Tenga en cuenta que no necesitamos calcular específicamente la función de transformación, solo necesitamos encontrar el producto escalar de esos para obtener la función kernel, sin embargo, esta función de transformación se puede establecer fácilmente.

dónde,

es la función de transformación.
La intuición detrás de que muchas veces los datos pueden estar separados por un hiperplano en una dimensión superior. Veamos esto con más detalle:
Supongamos que tenemos un conjunto de datos que contiene solo 1 variable independiente y 1 dependiente. La siguiente gráfica representa los datos:
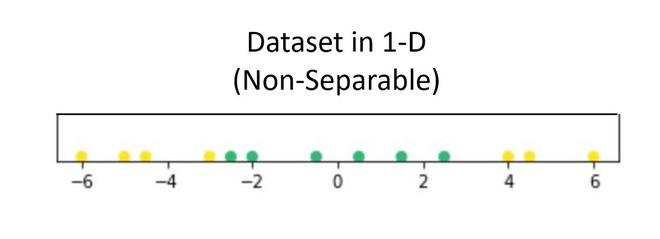
Ahora, en el gráfico anterior, es difícil separar un hiperplano 1D (punto) que separa claramente los puntos de datos de diferentes clases. Pero cuando esto se transformó a 2d usando alguna transformación, brinda opciones para separar las clases.
![]()
En el ejemplo anterior, podemos ver que una línea SVM puede separar claramente las dos clases del conjunto de datos.
Hay un núcleo famoso que se usa con bastante frecuencia:
- Polinomios de grado =n

- Polinomios de grado hasta n

- Núcleo gaussiano/RBF

Implementación
Python3
# code import numpy as np import matplotlib.pyplot as plt from sklearn import svm, datasets # import some data cancer = datasets.load_breast_cancer() X = cancer.data[:,:2] Y = cancer.target X.shape, Y.shape # perform svm with different kernel, here c is the regularizer h = .02 C=100 lin_svc = svm.LinearSVC(C=C) svc = svm.SVC(kernel='linear', C=C) rbf_svc = svm.SVC(kernel='rbf', gamma=0.7, C=C) poly_svc = svm.SVC(kernel='poly', degree=3, C=C) # Fit the training dataset. lin_svc.fit(X, Y) svc.fit(X, Y) rbf_svc.fit(X, Y) poly_svc.fit(X, Y) # plot the results x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h)) titles = ['linear kernel', 'LinearSVC (linear kernel)', 'RBF kernel', 'polynomial (degree 3) kernel'] plt.figure(figsize=(10,10)) for i, clf in enumerate((svc, lin_svc,rbf_svc, poly_svc )): # Plot the decision boundary using the above meshgrid we generated plt.subplot(2, 2, i + 1) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # Put the result into a color plot Z = Z.reshape(xx.shape) plt.set_cmap(plt.cm.flag_r) plt.contourf(xx, yy, Z) # Plot also the training points plt.scatter(X[:, 0], X[:, 1], c=Y) plt.title(titles[i]) plt.show()
((569, 2), (569,))
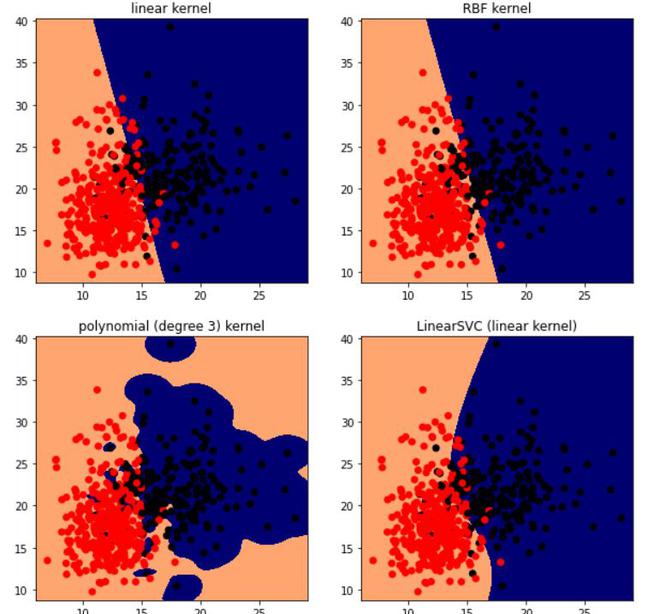
SVM usando diferentes núcleos.