Aprendizaje automático: el estudio de algoritmos informáticos que mejoran automáticamente a través de la experiencia. Es visto como un subconjunto de la inteligencia artificial.
La clasificación es el proceso de categorizar un conjunto dado de datos en clases.
En Machine Learning (ML), enmarca el problema, recopila y limpia los datos, agrega algunas variables de características necesarias (si las hay), entrena el modelo, mide su rendimiento, lo mejora utilizando alguna función de costo y luego está listo para desplegar.
Pero, ¿cómo medimos su rendimiento? ¿Hay alguna característica en particular para mirar?
Una respuesta trivial y amplia sería comparar los valores reales con los valores predichos. Pero eso no resuelve el problema.
Consideremos el famoso conjunto de datos MNIST e intentemos analizar el problema.
Python3
# Importing the dataset.
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
# Creating independent and dependent variables.
X, y = mnist['data'], mnist['target']
# Splitting the data into training set and test set.
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
"""
The training set is already shuffled for us, which is good as this guarantees that all
cross-validation folds will be similar.
"""
# Training a binary classifier.
y_train_5 = (y_train == 5) # True for all 5s, False for all other digits.
y_test_5 = (y_test == 5)
"""
Building a dumb classifier that just classifies every single image in the “not-5” class.
"""
from sklearn.model_selection import cross_val_score
from sklearn.base import BaseEstimator
class Never5Classifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
never_5_clf = Never5Classifier()
cross_val_score(never_5_clf, X_train, y_train_5, cv=3, scoring="accuracy")
Si ejecutó el mismo código en un IDE, ¡obtendría una serie de precisiones, cada una con una precisión superior al 90%! Esto se debe simplemente a que solo alrededor del 10 % de las imágenes son 5, por lo que si siempre adivina que una imagen no es un 5, acertará aproximadamente el 90 % de las veces.
Esto demuestra por qué la precisión generalmente no es la medida de desempeño preferida para los clasificadores, especialmente cuando se trata de conjuntos de datos sesgados (es decir, cuando algunas clases son mucho más frecuentes que otras).
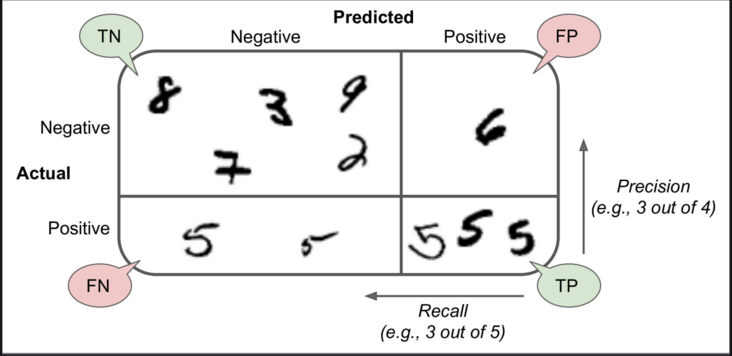
Array de confusión
Una forma mucho mejor de evaluar el rendimiento de un clasificador es observar la array de confusión. La idea general es contar la cantidad de veces que las instancias de la clase A se clasifican como clase B. Por ejemplo, para saber la cantidad de veces que el clasificador confundió imágenes de 5 con 3, buscaría en la quinta fila y la tercera columna de la array de confusión.
Python3
# Creating some predictions. from sklearn.model_selection import cross_val_predict y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) """ You could make predictions on the test set, but use the test set only at the very end of your project, once you have a classifier that you are ready to launch. """ # Constructing the confusion matrix. from sklearn.metrics import confusion_matrix confusion_matrix(y_train_5, y_train_pred)
Cada fila en una array de confusión representa una clase real, mientras que cada columna representa una clase predicha. Para obtener más información sobre la confusión, haga clic en matrix aquí.
La array de confusión le brinda mucha información, pero a veces puede preferir una métrica más concisa.
- Precisión
precisión = (TP) / (TP+FP)
TP es el número de verdaderos positivos y FP es el número de falsos positivos.
Una forma trivial de tener una precisión perfecta es hacer una sola predicción positiva y asegurarse de que sea correcta (precisión = 1/1 = 100 %). Esto no sería muy útil ya que el clasificador ignoraría todas las instancias positivas excepto una.
- Recuperar
recordar = (TP) / (TP+FN)
Python3
# Finding precision and recall from sklearn.metrics import precision_score, recall_score precision_score(y_train_5, y_train_pred) recall_score(y_train_5, y_train_pred)
Ahora su detector 5 no se ve tan brillante como cuando miró su precisión. Cuando afirma que una imagen representa un 5, es correcta solo el 72,9% (precisión) de las veces. Además, solo detecta el 75,6% (recall) de los 5s.
A menudo, es conveniente combinar la precisión y la recuperación en una sola métrica llamada puntaje F1, en particular, si necesita una forma simple de comparar dos clasificadores.
La puntuación F1 es la media armónica de precisión y recuperación.
Python3
# To compute the F1 score, simply call the f1_score() function: from sklearn.metrics import f1_score f1_score(y_train_5, y_train_pred)
La puntuación F1 favorece a los clasificadores que tienen una precisión y recuperación similares.
Esto no siempre es lo que desea: en algunos contextos, lo que más le importa es la precisión, y en otros contextos, realmente le importa la recuperación. Por ejemplo, si entrenó un clasificador para detectar videos que son seguros para los niños, probablemente preferiría un clasificador que rechace muchos videos buenos (baja recuperación) pero solo mantenga los seguros (alta precisión), en lugar de un clasificador que tiene mucho más. mayor recuerdo, pero permite que aparezcan algunos videos terribles en su producto (en tales casos, es posible que desee agregar una canalización humana para verificar la selección de videos del clasificador). Por otro lado, suponga que entrena a un clasificador para detectar ladrones en imágenes de vigilancia: probablemente esté bien si su clasificador tiene solo un 30 % de precisión siempre que tenga un 99 % de recuperación (claro, los guardias de seguridad recibirán algunas alertas falsas, pero casi todos los ladrones serán atrapados).
Desafortunadamente, no puede tener las dos cosas: aumentar la precisión reduce la recuperación y viceversa. Esto se llama equilibrio precisión/recuperación .
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA