En un conjunto de datos, para k conjunto de variables/columnas (X 1 , X 2 , ….X k ), la array de gráficos de dispersión traza toda la dispersión por pares entre diferentes variables en forma de array.
La array de diagramas de dispersión responde las siguientes preguntas:
- ¿Hay alguna relación por pares entre diferentes variables? Y si hay relaciones, ¿cuál es la naturaleza de estas relaciones?
- ¿Hay valores atípicos en el conjunto de datos?
- ¿Hay algún agrupamiento por grupos presente en el conjunto de datos sobre la base de una variable en particular?
Para k variables en el conjunto de datos, la array de gráficos de dispersión contiene k filas y k columnas. Cada fila y columna se representa como un solo diagrama de dispersión. Cada parcela individual (i, j) se puede definir como:
- Eje Vertical: Variable X j
- Eje Horizontal: Variable X i
A continuación se presentan algunos factores importantes que consideramos al trazar la array de diagrama de dispersión:
- La gráfica se encuentra en la diagonal, es solo una línea de 45 porque estamos trazando aquí X i vs X i. Sin embargo, podemos trazar el histograma para X i en las diagonales o simplemente dejarlo en blanco.
- Dado que X i frente a X j es equivalente a X j frente a X i con los ejes invertidos, también podemos omitir los gráficos debajo de la diagonal.
- Puede ser más útil si superponemos un diagrama de líneas en los puntos dispersos en los diagramas para brindar una mayor comprensión del diagrama.
- La idea de la gráfica por pares también se puede extender a otras gráficas diferentes, como las gráficas cuantil-cuantil o bihistograma.
Implementación
- Para esta implementación, utilizaremos el conjunto de datos Titanic. Este conjunto de datos se puede descargar desde Kaggle . Antes de trazar la array de dispersión, realizaremos algunas operaciones de preprocesamiento en el marco de datos para obtener la forma deseada.
Python3
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
% matplotlib inline
# load titanic dataset
titanic_dataset = pd.read_csv('tested.csv.xls')
titanic_dataset.head()
# Drop some unimportant columns in the dataset.
titanic_dataset.drop(['Name', 'Ticket','Cabin','PassengerId'],axis=1, inplace=True)
# check for different data types
titanic_dataset.dtypes
# print unique values of dataset
titanic_dataset['Embarked'].unique()
titanic_dataset['Sex'].unique()
# Replace NAs with mean
titanic_dataset.fillna(titanic_dataset.mean(), inplace=True)
# convert some column into integer for representation in
# scatter matrix
titanic_dataset["Sex"] = titanic_dataset["Sex"].cat.codes
titanic_dataset["Embarked"] = titanic_dataset["Embarked"].cat.codes
titanic_dataset.head()
# plot scatter matrix using pandas and matplotlib
survive_colors = {0:'orange', 1:'blue'}
pd.plotting.scatter_matrix(titanic_dataset,figsize=(20,20),grid=True,
marker='o', c= titanic_dataset['Survived'].map(colors))
# plot scatter matrix using seaborn
sns.set_theme(style="ticks")
sns.pairplot(titanic_dataset, hue='Survived')
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 892 0 3 Kelly, Mr. James male 34.5 0 0 330911 7.8292 NaN Q 1 893 1 3 Wilkes, Mrs. James (Ellen Needs) female 47.0 1 0 363272 7.0000 NaN S 2 894 0 2 Myles, Mr. Thomas Francis male 62.0 0 0 240276 9.6875 NaN Q 3 895 0 3 Wirz, Mr. Albert male 27.0 0 0 315154 8.6625 NaN S 4 896 1 3 Hirvonen, Mrs. Alexander (Helga E Lindqvist) female 22.0 1 1 3101298 12.2875 NaN S
PassengerId int64 Survived int64 Pclass int64 Sex object Age float64 SibSp int64 Parch int64 Fare float64 Embarked object dtype: object
Survived Pclass Sex Age SibSp Parch Fare Embarked 0 0 3 1 34.5 0 0 7.8292 1 1 1 3 0 47.0 1 0 7.0000 2 2 0 2 1 62.0 0 0 9.6875 1 3 0 3 1 27.0 0 0 8.6625 2 4 1 3 0 22.0 1 1 12.2875 2
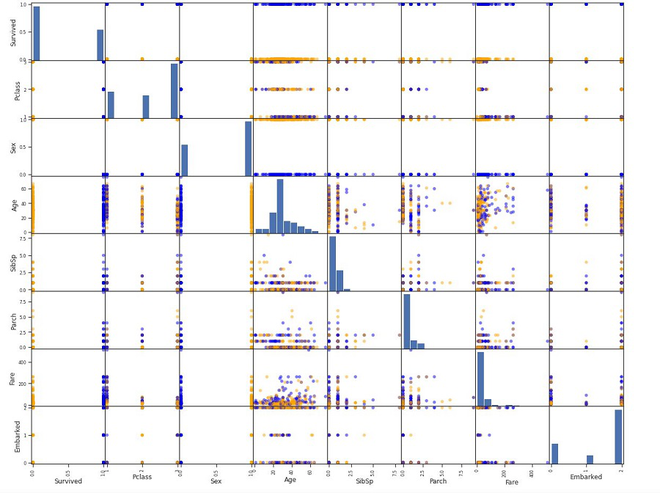
Matplotlib Array de dispersión
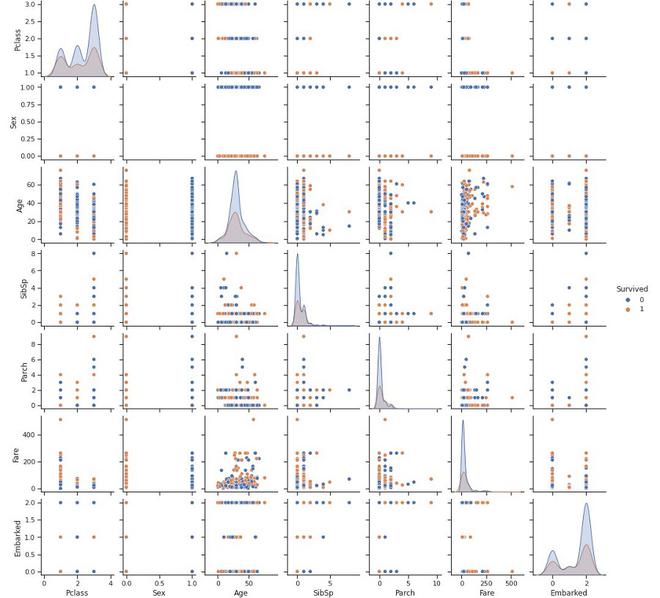
Array de dispersión marina