El rápido incremento de la información computarizada o digital ha provocado un enorme volumen de información y datos. Una parte sustancial de la información disponible se almacena en bases de datos de texto, que consisten en grandes colecciones de documentos de varias fuentes. Las bases de datos de texto están creciendo rápidamente debido a la creciente cantidad de información disponible en formato electrónico. Más del 80% de la información actual se encuentra en forma de datos no estructurados o semiorganizados. Las técnicas tradicionales de recuperación de información se vuelven inadecuadas para la cantidad cada vez mayor de datos de texto. Por lo tanto, la minería de texto se ha convertido en una parte cada vez más popular y esencial de la minería de datos. El descubrimiento de patrones adecuados y el análisis del documento de texto a partir del enorme volumen de datos es un problema importante en las áreas de aplicación del mundo real.
“La extracción de información interesante o patrones de datos en grandes bases de datos se conoce como minería de datos”.
La minería de texto es un proceso de extracción de información útil y patrones no triviales de un gran volumen de bases de datos de texto. Existen diversas estrategias y dispositivos para minar el texto y encontrar datos importantes para el proceso de predicción y toma de decisiones. La selección del procedimiento de minería de texto correcto y preciso también ayuda a mejorar la velocidad y la complejidad del tiempo. Este artículo discute y analiza brevemente la minería de texto y sus aplicaciones en diversos campos.
“Text Mining es el procedimiento de síntesis de información, mediante el análisis de relaciones, patrones y reglas entre datos textuales”.
Como discutimos anteriormente, el tamaño de la información se está expandiendo a tasas exponenciales. Hoy en día, todos los institutos, empresas, diferentes organizaciones y empresas comerciales almacenan su información electrónicamente. Una gran colección de datos disponibles en Internet y almacenados en bibliotecas digitales, repositorios de bases de datos y otros datos textuales como sitios web, blogs, redes sociales y correos electrónicos. Es una tarea difícil determinar patrones y tendencias apropiados para extraer conocimiento de este gran volumen de datos. La minería de texto es una parte de la minería de datos para extraer información de texto valiosa de un depósito de base de datos de texto. La minería de textos es un campo multidisciplinario basado en la recuperación de datos, la minería de datos, la inteligencia artificial, las estadísticas, el aprendizaje automático y la lingüística computacional.
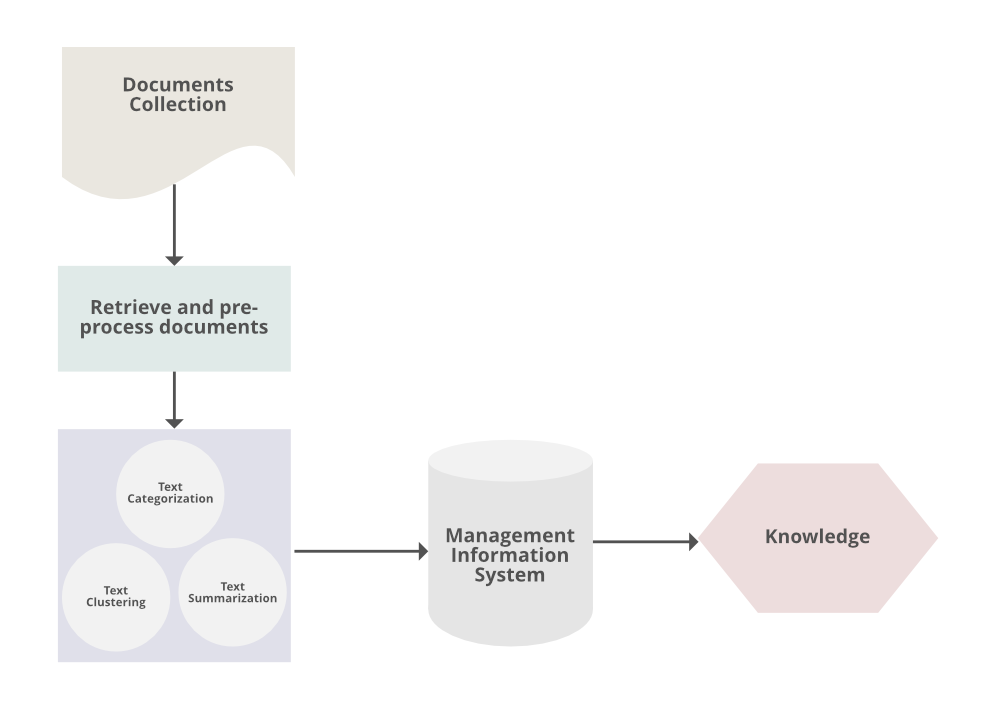
El proceso convencional de minería de texto de la siguiente manera:
- Recopilación de información no estructurada de varias fuentes accesibles en varias organizaciones de documentos, por ejemplo, texto sin formato, páginas web, registros PDF, etc.
- Se realizan tareas de preprocesamiento y limpieza de datos para distinguir y eliminar la inconsistencia de los datos. El proceso de limpieza de datos se asegura de capturar el texto genuino y se realiza para eliminar la derivación de palabras vacías (el proceso de identificar la raíz de una determinada palabra e indexar los datos).
- Las tareas de procesamiento y control se aplican para revisar y limpiar aún más el conjunto de datos.
- El análisis de patrones se implementa en el Sistema de información de gestión.
- La información procesada en los pasos anteriores se utiliza para extraer datos importantes y aplicables para un proceso de toma de decisiones y análisis de tendencias poderoso y conveniente.
Procedimientos de análisis de Minería de Texto:
- Resumen de texto: para extraer su contenido parcial reflejando todo su contenido automáticamente.
- Categorización de Texto: Para asignar una categoría al texto entre categorías predefinidas por los usuarios.
- Agrupamiento de texto: para segmentar textos en varios grupos, dependiendo de la relevancia sustancial.
Técnicas de minería de textos:
- Extracción de información : es un proceso de extracción de palabras significativas de los documentos.
- Recuperación de información : es un proceso de extracción de patrones relevantes y asociados de acuerdo con un conjunto determinado de palabras o documentos de texto.
- Procesamiento del lenguaje natural: se refiere al procesamiento y análisis automático de información de texto no estructurado.
- Clustering: Es un proceso de aprendizaje no supervisado que agrupa textos de acuerdo a sus características similares.
- Resumen de texto: para extraer su contenido parcial, refleja su contenido completo automáticamente.
Descripción general de las técnicas de minería de texto
|
Fase del proceso de minería de texto |
Algoritmo |
Pregunta seleccionada |
Motivo |
Técnicas |
|
|---|---|---|---|---|---|
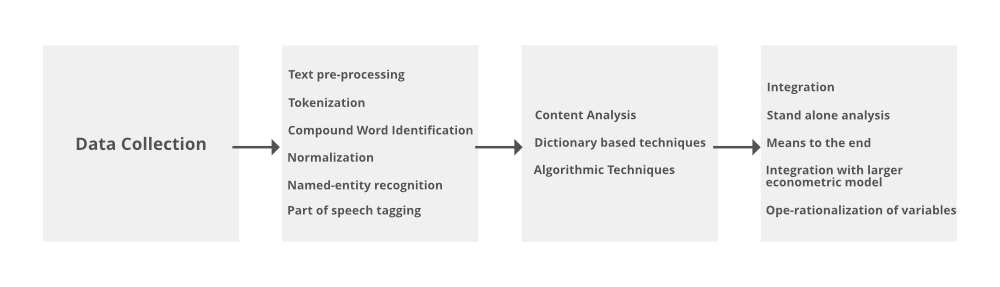
| 1. Fase de preprocesamiento de texto | Tokenización | ¿Cómo se puede transformar un texto en palabras o formato de texto? | Transferir strings a un solo token textual. | Separación de espacios en blanco. | |
| Identificación de palabras compuestas | ¿Cómo puedo identificar palabras que tienen un significado conjunto? | Identificar palabras con un significado conjunto que se pierde palabra | n-grms | ||
| Normalización y reducción de ruido | ¿Cómo puedo hacer frente a demasiadas variables en mi Document-Term-Matrix? | Reduciendo la dimensionalidad de Document‐Term‐Matrix | Lematización, Lematización, Eliminación de palabras vacías. término poco frecuente. | ||
| Análisis lingüístico | ¿Cómo puedo identificar palabras con un significado o función gramatical especial? | etiquetado de palabras | Reconocimiento de entidad nombrada, etiquetado de parte del discurso | ||
| 2. Análisis de contenido | basado en diccionario | ¿Cómo puedo identificar cómo los rasgos y estados sociológicos o psicológicos latentes se reflejan en el lenguaje natural? | Medición de conceptos y construcciones contextuales, psicológicas, lingüísticas o semánticas |
diccionarios predefinidos Diccionarios personalizados |
|
| Técnicas algorítmicas | ¿Cómo puedo asignar textos a clases predefinidas? | Clasificación de entidades textuales en categorías predefinidas | Técnicas de aprendizaje supervisado como clasificadores binarios o multiclase | ||
| ¿Cómo puedo agrupar documentos similares? | Agrupación de entidades textuales en anteriormente indefinidas y desconocidas | Técnicas de aprendizaje no supervisado como LDA, k‐means o non‐negative |
Área de aplicación de la minería de texto
1. Biblioteca digital
Se están utilizando varias estrategias y herramientas de minería de texto para obtener el patrón y las tendencias de las revistas y actas que se almacenan en repositorios de bases de datos de texto. Estos recursos de información ayudan en el ámbito del área de investigación. Las bibliotecas son un buen recurso de datos de texto en forma digital. Brinda una técnica novedosa para obtener datos útiles de tal manera que hace posible acceder a millones de registros en línea. Una biblioteca digital internacional de piedra verde que admite numerosos idiomas e interfaces multilingües brinda un método elástico para extraer informes que manejan varios formatos, es decir, Microsoft Word, PDF, postscript, HTML, lenguajes de secuencias de comandos y correo electrónico. Además, admite la extracción de formatos audiovisuales y de imagen junto con documentos de texto. Los procesos de minería de texto realizan diferentes actividades como la recopilación de documentos, determinación, mejora, eliminación de datos y manipulación de sustancias, y Producción de resúmenes. Existen diferentes tipos de herramientas de minería de texto de bibliotecas digitales, a saber: GATE, Net Owl y Aylien, que se utilizan para la minería de texto.
2. Campo Académico y de Investigación
En el campo de la educación, se utilizan diferentes herramientas y estrategias de minería de texto para examinar los patrones instructivos en una región/campo de investigación específico. El objetivo principal de la utilización de minería de texto en el campo de la investigación es ayudar a descubrir y organizar trabajos de investigación y material relevante de varios campos en una plataforma. Para esto, utilizamos el agrupamiento de k-Means y diferentes estrategias ayudan a distinguir las propiedades de los datos significativos. Asimismo, se puede acceder al desempeño de los estudiantes en diversas materias, y cómo diversas cualidades impactan en la selección de materias evaluadas por esta minería.
3. Ciencias de la vida
Las industrias de ciencias de la vida y atención de la salud están produciendo un volumen enorme de datos textuales y matemáticos sobre registros de pacientes, enfermedades, medicamentos, síntomas y tratamientos de enfermedades, etc. Es un problema importante filtrar datos y texto relevante para tomar decisiones desde un punto de vista biológico. repositorio de datos. Las historias clínicas contienen datos variables, impredecibles, extensos. La minería de texto puede ayudar a administrar este tipo de datos. Uso de minería de texto en la divulgación de biomarcadores, industria farmacéutica, un examen de análisis de comercio clínico, estudio clínico, inteligencia competitiva de patentes también.
4. Redes Sociales
La minería de texto es accesible para diseccionar el análisis de aplicaciones de medios basadas en la web para monitorear e investigar contenido en línea como texto sin formato de noticias de Internet, revistas web, correo electrónico, blogs, etc. Los dispositivos de minería de texto ayudan a distinguir e investigar la cantidad de publicaciones, me gusta y seguidores en la red de medios basada en la web. Este tipo de análisis muestra las respuestas de las personas a varias publicaciones, noticias y cómo se difundió. Muestra el comportamiento de las personas que pertenecen a un grupo de edad específico y la variación en Me gusta, vistas sobre la misma publicación.
5. Inteligencia de negocios
La minería de texto juega un papel importante en la inteligencia comercial que ayuda a diferentes organizaciones y empresas a analizar a sus clientes y competidores para tomar mejores decisiones. Brinda una comprensión precisa del negocio y brinda datos sobre cómo mejorar la satisfacción del consumidor y obtener beneficios competitivos. Los dispositivos de minería de texto como el análisis de texto de IBM.
GATE ayuda a tomar la decisión sobre la organización que produce alertas sobre buen y mal desempeño, un cambio de mercado que ayuda a tomar las acciones necesarias. Esta minería se puede utilizar en el sector de las telecomunicaciones, el comercio, el sistema de gestión de la string de clientes.
Problemas en la minería de texto
Numerosos problemas ocurren durante el proceso de minería de texto:
1. La eficiencia y eficacia de la toma de decisiones.
2. El problema incierto puede presentarse en una etapa intermedia de la minería de texto. En la etapa de preprocesamiento se caracterizan diferentes reglas y lineamientos para normalizar el texto que hacen eficiente el proceso de minería de textos. Antes de aplicar el análisis de patrones en el documento, es necesario cambiar los datos no estructurados a una estructura moderada.
3. A veces, el mensaje original o el significado se pueden cambiar debido a la alteración.
4. Otro problema en la minería de texto es que muchos algoritmos y técnicas admiten texto en varios idiomas. Puede crear ambigüedad en el significado del texto. Este problema puede dar lugar a resultados falsos positivos.
5. La utilización de sinónimos, polisemias y antónimos en el texto del documento genera problemas para las herramientas de minería de texto que toman ambos en un entorno similar. Es difícil categorizar este tipo de texto/palabras.
Publicación traducida automáticamente
Artículo escrito por varshachoudhary y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA