Meanshift se incluye en la categoría de un algoritmo de agrupamiento en contraste con el aprendizaje no supervisado que asigna los puntos de datos a los grupos de forma iterativa cambiando los puntos hacia la moda (la moda es la mayor densidad de puntos de datos en la región, en el contexto de Meanshift) . Como tal, también se conoce como el algoritmo de búsqueda de modo . El algoritmo de desplazamiento medio tiene aplicaciones en el campo del procesamiento de imágenes y la visión artificial.
Dado un conjunto de puntos de datos, el algoritmo asigna iterativamente cada punto de datos hacia el centroide del clúster más cercano y la dirección hacia el centroide del clúster más cercano se determina según la ubicación de la mayoría de los puntos cercanos. Entonces, cada iteración, cada punto de datos se moverá más cerca de donde se encuentran la mayoría de los puntos, que es o conducirá al centro del grupo. Cuando el algoritmo se detiene, cada punto se asigna a un grupo.
A diferencia del popular algoritmo de conglomerados K-Means, el cambio de media no requiere especificar el número de conglomerados por adelantado. El número de grupos está determinado por el algoritmo con respecto a los datos.
Nota: La desventaja de Mean Shift es que es computacionalmente costoso O(n²).
Estimación de la densidad del kernel:
El primer paso al aplicar algoritmos de agrupamiento de cambio medio es representar sus datos de manera matemática, lo que significa representar sus datos como puntos como el conjunto a continuación.
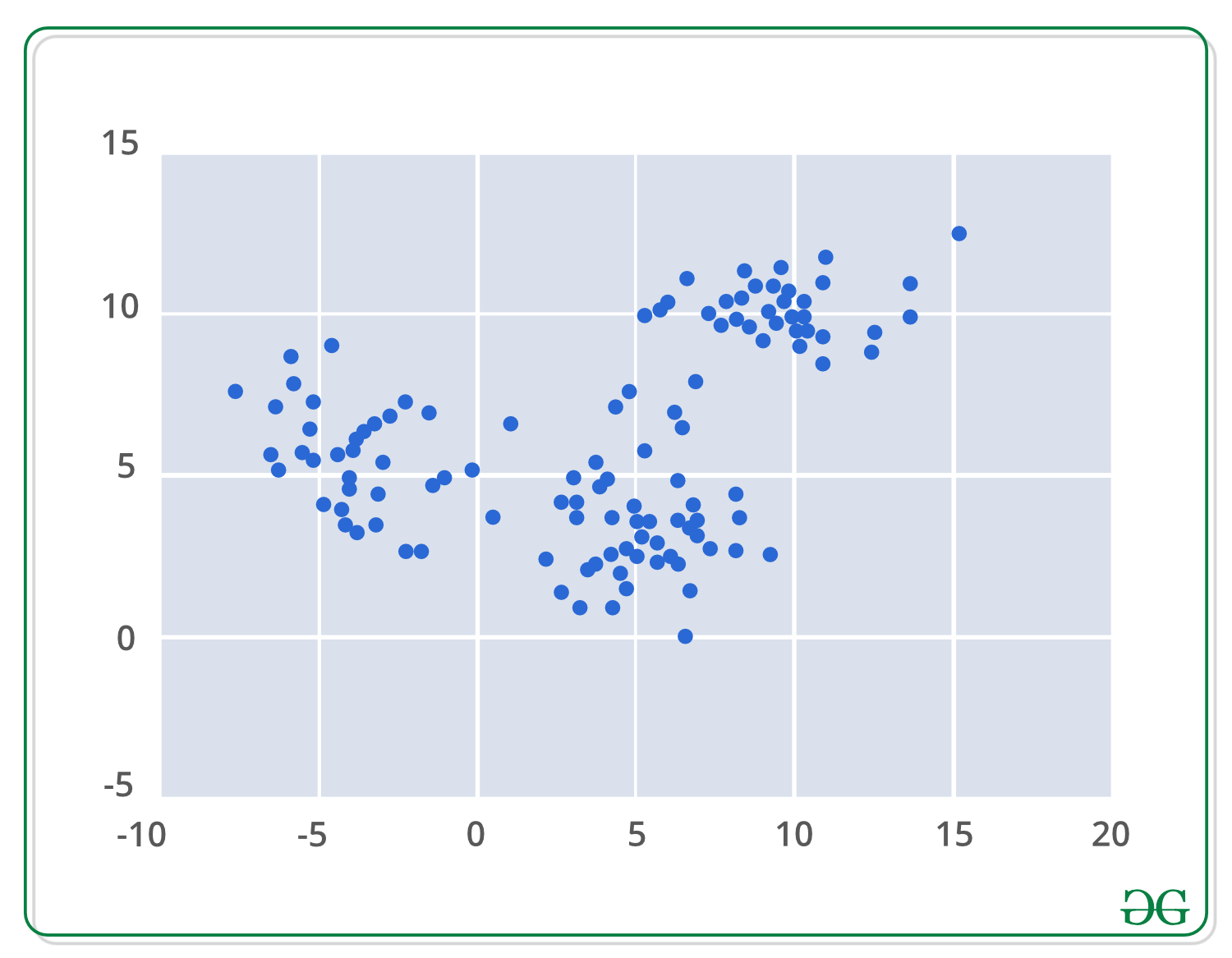
Mean-shift se basa en el concepto de estimación de la densidad del núcleo, en resumen, KDE. Imagine que los datos anteriores se tomaron como muestra de una distribución de probabilidad. KDE es un método para estimar la distribución subyacente, también llamada función de densidad de probabilidad para un conjunto de datos.
Funciona colocando un núcleo en cada punto del conjunto de datos. Un núcleo es una palabra matemática sofisticada para una función de ponderación que generalmente se usa en la convolución. Hay muchos tipos diferentes de núcleos, pero el más popular es el núcleo gaussiano. La suma de todos los núcleos individuales genera una función de densidad de ejemplo de superficie de probabilidad. Según el parámetro de ancho de banda del núcleo utilizado, la función de densidad resultante variará.
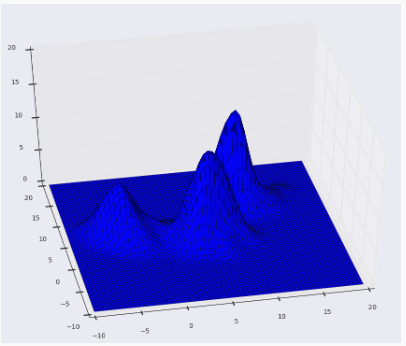
A continuación se muestra la superficie de KDE para nuestros puntos anteriores utilizando un núcleo gaussiano con un ancho de banda del núcleo de 2.
Parcela de superficie:
Dibujo de contorno:
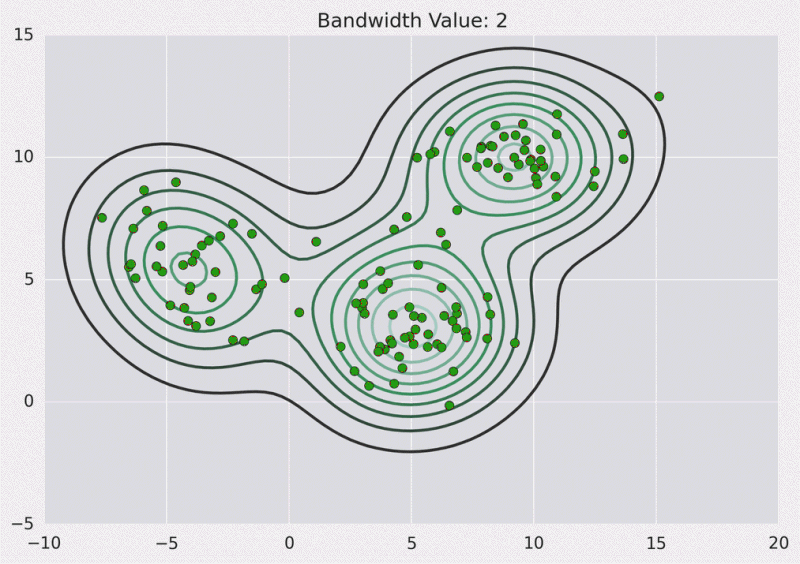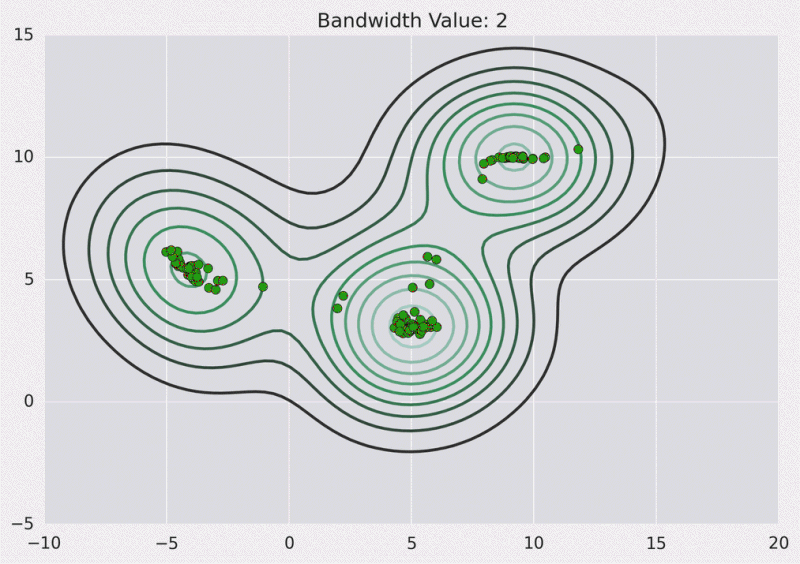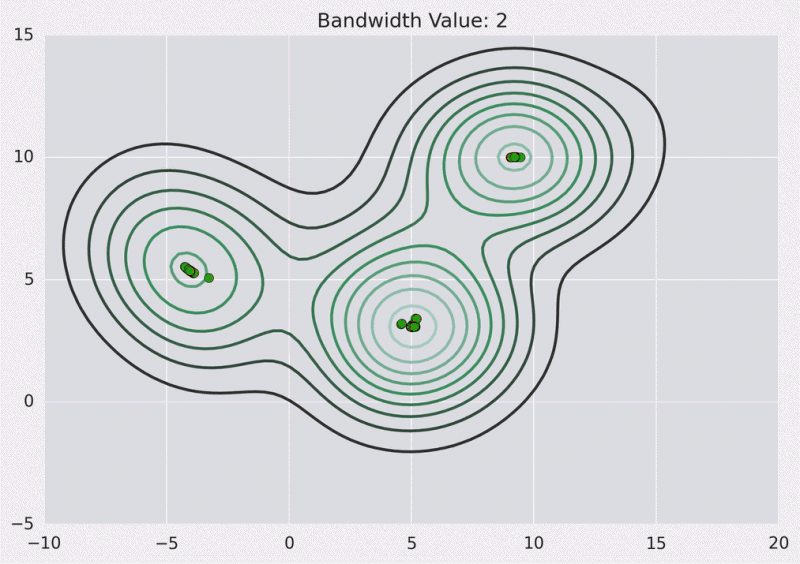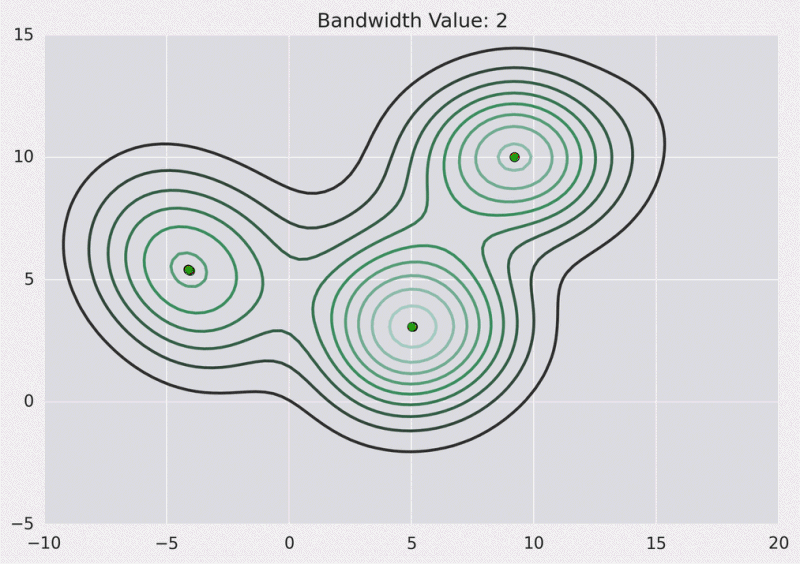
A continuación se muestra la implementación de Python:
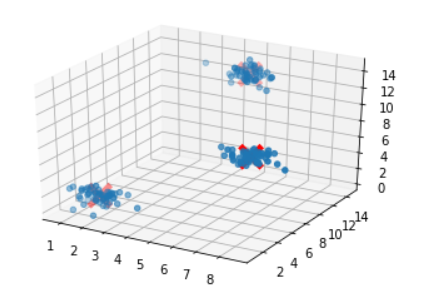
import numpy as np import pandas as pd from sklearn.cluster import MeanShift from sklearn.datasets.samples_generator import make_blobs from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D # We will be using the make_blobs method # in order to generate our own data. clusters = [[2, 2, 2], [7, 7, 7], [5, 13, 13]] X, _ = make_blobs(n_samples = 150, centers = clusters, cluster_std = 0.60) # After training the model, We store the # coordinates for the cluster centers ms = MeanShift() ms.fit(X) cluster_centers = ms.cluster_centers_ # Finally We plot the data points # and centroids in a 3D graph. fig = plt.figure() ax = fig.add_subplot(111, projection ='3d') ax.scatter(X[:, 0], X[:, 1], X[:, 2], marker ='o') ax.scatter(cluster_centers[:, 0], cluster_centers[:, 1], cluster_centers[:, 2], marker ='x', color ='red', s = 300, linewidth = 5, zorder = 10) plt.show()
Producción:
Para ilustrar, supongamos que tenemos un conjunto de datos {ui} de puntos en un espacio d-dimensional, muestreados de una población más grande, y que hemos elegido un kernel K que tiene un parámetro de ancho de banda h. Juntos, estos datos y la función kernel devuelven el siguiente estimador de densidad kernel para la función de densidad de la población completa.

La función kernel aquí es necesaria para satisfacer las siguientes dos condiciones:
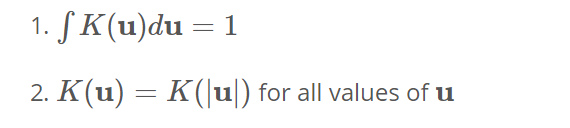
-> El primer requisito es necesario para garantizar que nuestra estimación se normalice.
-> El segundo está asociado a la simetría de nuestro espacio.
Dos funciones populares del kernel que satisfacen estas condiciones vienen dadas por:

A continuación, representamos un ejemplo en una dimensión utilizando el núcleo gaussiano para estimar la densidad de alguna población a lo largo del eje x. Podemos ver que cada punto de muestra agrega una pequeña Gaussiana a nuestra estimación, centrada en ella y las ecuaciones anteriores pueden parecer un poco intimidantes, pero el gráfico aquí debería aclarar que el concepto es bastante sencillo.
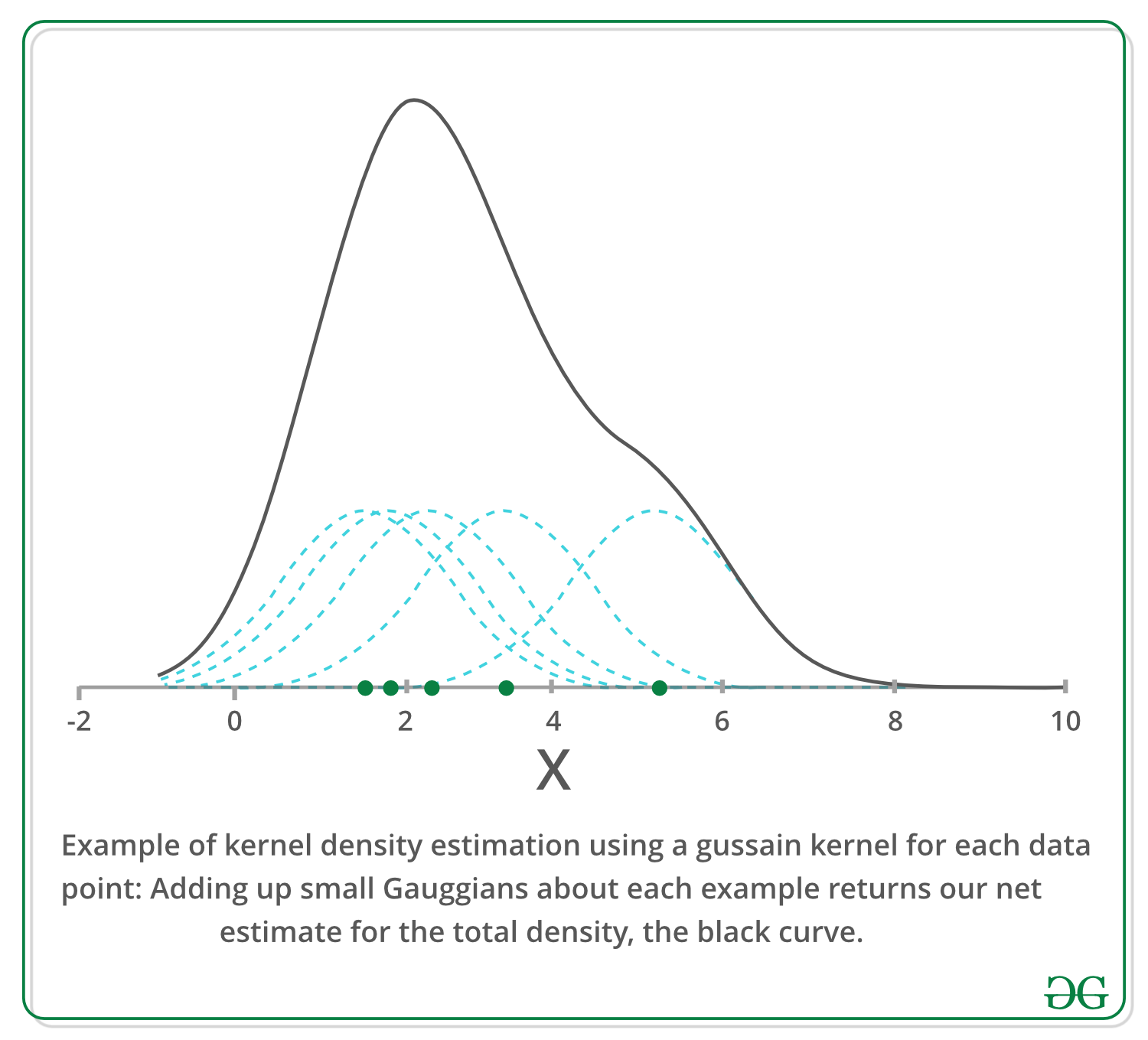
Búsqueda de modo iterativo –
1. Initialize random seed and window W. 2. Calculate the center of gravity (mean) of W. 3. Shift the search window to the mean. 4. Repeat Step 2 until convergence.
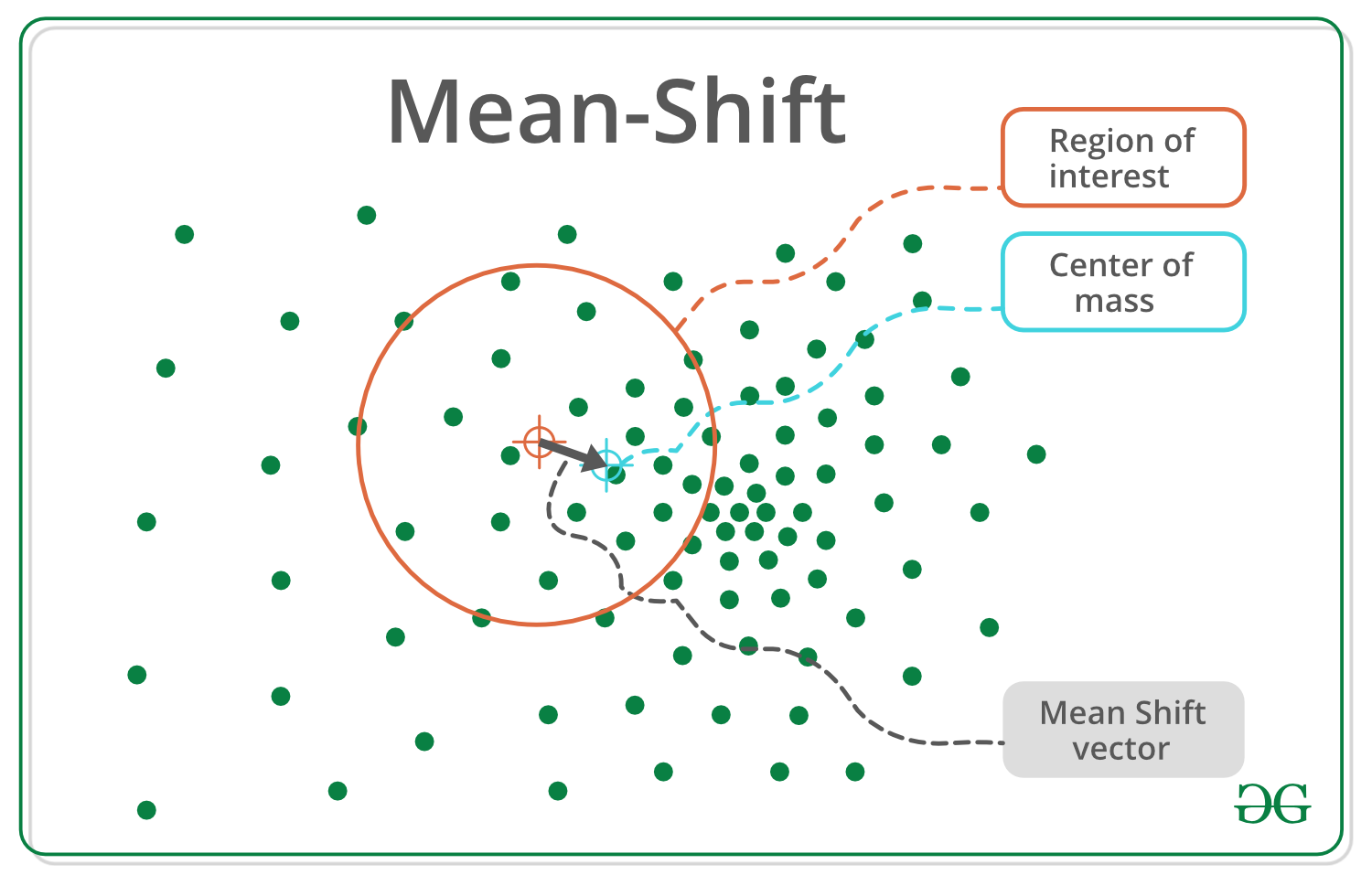
Esquema general del algoritmo –
for p in copied_points: while not at_kde_peak: p = shift(p, original_points)
La función de cambio se ve así:
def shift(p, original_points): shift_x = float(0) shift_y = float(0) scale_factor = float(0) for p_temp in original_points: # numerator dist = euclidean_dist(p, p_temp) weight = kernel(dist, kernel_bandwidth) shift_x += p_temp[0] * weight shift_y += p_temp[1] * weight # denominator scale_factor += weight shift_x = shift_x / scale_factor shift_y = shift_y / scale_factor return [shift_x, shift_y]
Ventajas:
- Encuentra un número variable de modos
- Robusto a valores atípicos
- Herramienta general independiente de la aplicación
- Sin modelo, no asume ninguna forma previa como esférica, elíptica, etc. en grupos de datos
- Solo un único parámetro (tamaño de ventana h) donde h tiene un significado físico (a diferencia de k-means)
Contras:
- La salida depende del tamaño de la ventana
- La selección del tamaño de la ventana (ancho de banda) no es trivial
- Computacionalmente (relativamente) costoso (aproximadamente 2 segundos/imagen)
- No se adapta bien a la dimensión del espacio de funciones.
Publicación traducida automáticamente
Artículo escrito por ankurtripathi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA