Requisito previo: valor óptimo de K en la agrupación en clústeres de K-Means
K-means es uno de los algoritmos de agrupamiento más populares, principalmente debido a su buen desempeño en el tiempo. Con el aumento del tamaño de los conjuntos de datos que se analizan, el tiempo de cálculo de K-means aumenta debido a su restricción de necesitar todo el conjunto de datos en la memoria principal. Por esta razón, se han propuesto varios métodos para reducir el costo temporal y espacial del algoritmo. Un enfoque diferente es el algoritmo Mini batch K-means .
La idea principal del algoritmo Mini Batch K-means es utilizar pequeños lotes aleatorios de datos de un tamaño fijo, para que puedan almacenarse en la memoria. Cada iteración se obtiene una nueva muestra aleatoria del conjunto de datos y se utiliza para actualizar los grupos y esto se repite hasta la convergencia. Cada mini lote actualiza los clústeres mediante una combinación convexa de los valores de los prototipos y los datos, aplicando una tasa de aprendizaje que disminuye con el número de iteraciones. Esta tasa de aprendizaje es la inversa del número de datos asignados a un clúster durante el proceso. A medida que aumenta el número de iteraciones, se reduce el efecto de los nuevos datos, por lo que se puede detectar la convergencia cuando no se producen cambios en los grupos en varias iteraciones consecutivas.
Los resultados empíricos sugieren que se puede obtener un ahorro sustancial de tiempo computacional a expensas de cierta pérdida de la calidad del conglomerado, pero no se ha realizado un estudio extenso del algoritmo para medir cómo las características de los conjuntos de datos, como el número de conglomerados o su tamaño, afecta la calidad de la partición.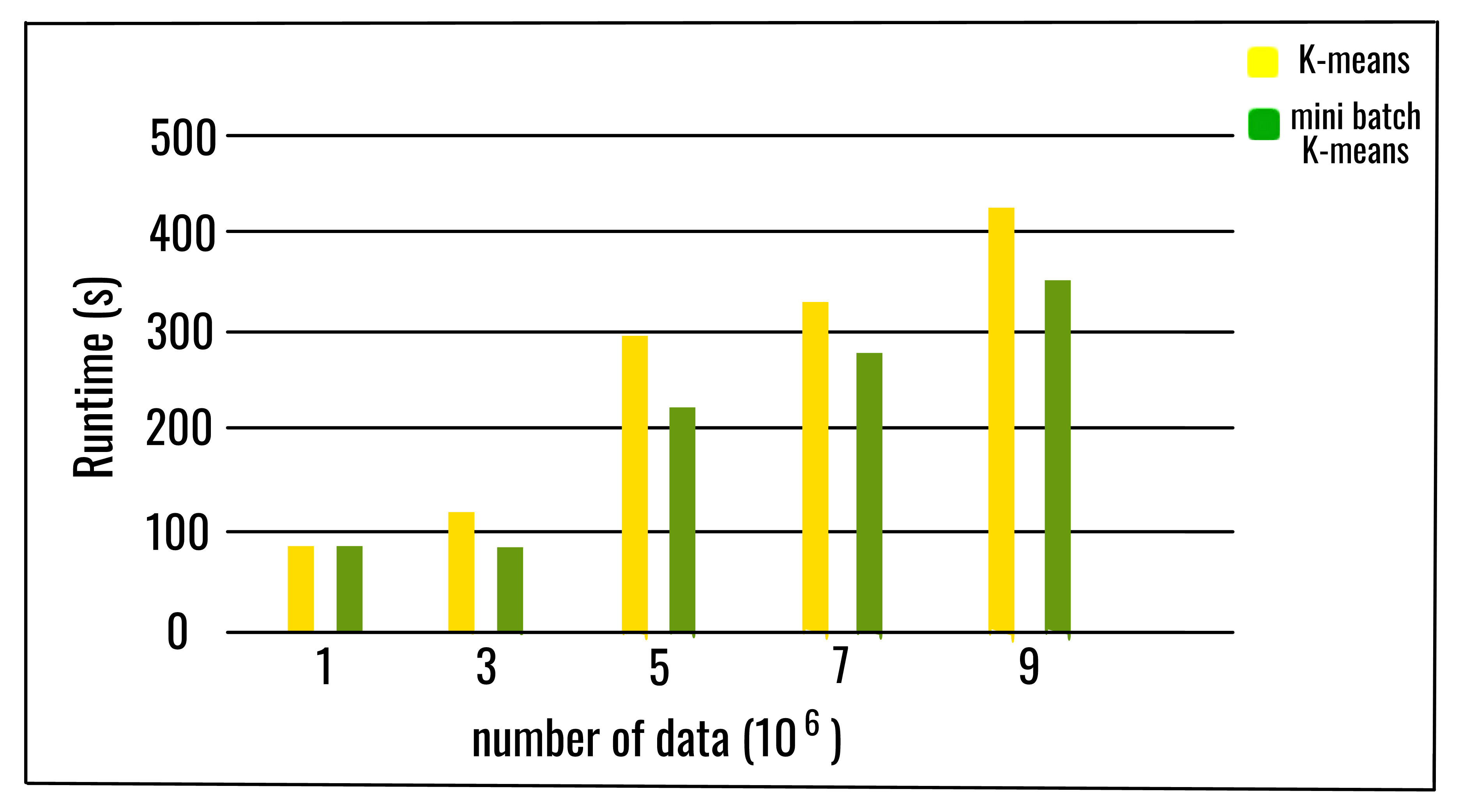
El algoritmo toma pequeños lotes elegidos al azar del conjunto de datos para cada iteración. Cada dato del lote se asigna a los clústeres, según las ubicaciones anteriores de los centroides de los clústeres. Luego actualiza las ubicaciones de los centroides de los clústeres en función de los nuevos puntos del lote. La actualización es una actualización de descenso de gradiente, que es significativamente más rápida que una actualización normal de Batch K-Means .
A continuación se muestra el algoritmo para las medias K de mini lotes :
Given a dataset D = {d1, d2, d3, .....dn},
no. of iterations t,
batch size b,
no. of clusters k.
k clusters C = {c1, c2, c3, ......ck}
initialize k cluster centers O = {o1, o2, .......ok}
# _initialize each cluster
Ci = Φ (1=< i =< k)
# _initialize no. of data in each cluster
Nci = 0 (1=< i =< k)
for j=1 to t do:
# M is the batch dataset and xm
# is the sample randomly chosen from D
M = {xm | 1 =< m =< b}
# catch cluster center for each
# sample in the batch data set
for m=1 to b do:
oi(xm) = sum(xm)/|c|i (xm ε M and xm ε ci)
end for
# update the cluster center with each batch set
for m=1 to b do:
# get the cluster center for xm
oi = oi(xm)
# update number of data for each cluster center
Nci = Nci + 1
#calculate learning rate for each cluster center
lr=1/Nci
# take gradient step to update cluster center
oi = (1-lr)oi + lr*xm
end for
end for
Implementación de Python del algoritmo anterior usando la biblioteca scikit-learn :
from sklearn.cluster import MiniBatchKMeans, KMeans from sklearn.metrics.pairwise import pairwise_distances_argmin from sklearn.datasets.samples_generator import make_blobs # Load data in X batch_size = 45 centers = [[1, 1], [-2, -1], [1, -2], [1, 9]] n_clusters = len(centers) X, labels_true = make_blobs(n_samples = 3000, centers = centers, cluster_std = 0.9) # perform the mini batch K-means mbk = MiniBatchKMeans(init ='k-means++', n_clusters = 4, batch_size = batch_size, n_init = 10, max_no_improvement = 10, verbose = 0) mbk.fit(X) mbk_means_cluster_centers = np.sort(mbk.cluster_centers_, axis = 0) mbk_means_labels = pairwise_distances_argmin(X, mbk_means_cluster_centers) # print the labels of each data print(mbk_means_labels)
El mini lote K-means es más rápido pero da resultados ligeramente diferentes que los K-means de lote normal.
Aquí agrupamos un conjunto de datos, primero con K-medias y luego con mini lotes K-medias, y graficamos los resultados. También trazaremos los puntos que están etiquetados de manera diferente entre los dos algoritmos.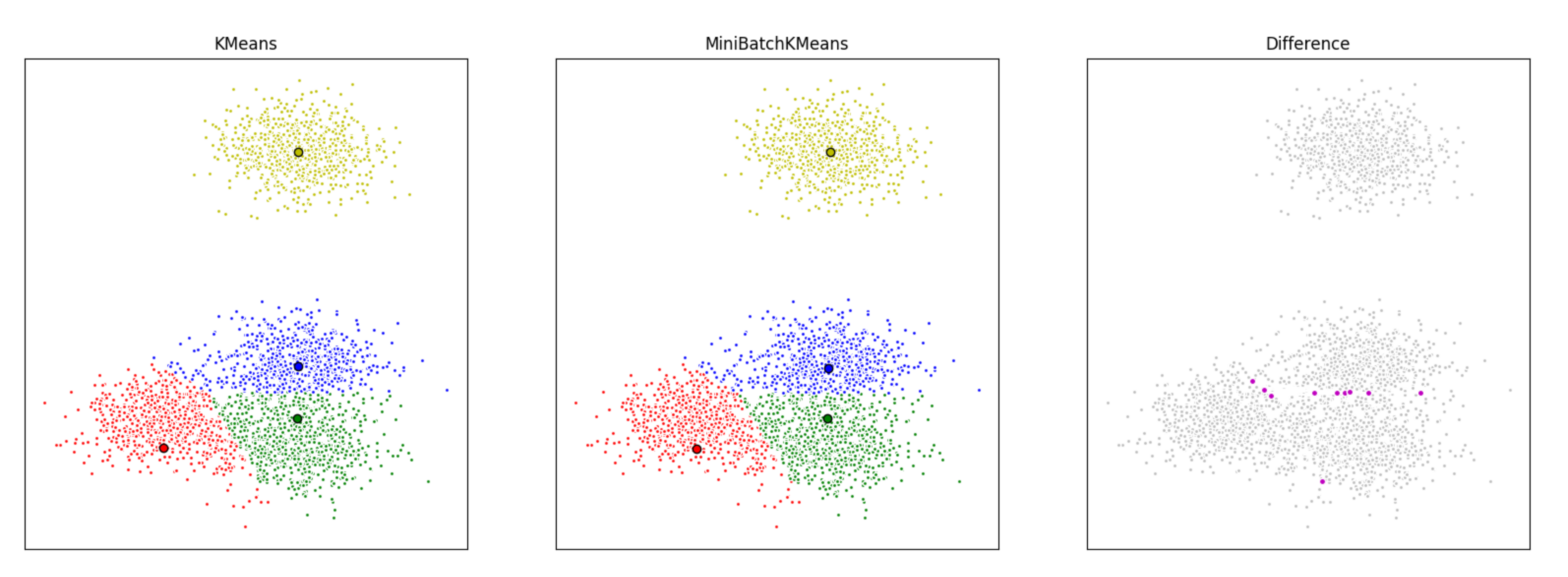
A medida que aumenta el número de grupos y el número de datos, también aumenta el ahorro relativo en el tiempo de cálculo. El ahorro en tiempo computacional es más notable solo cuando el número de clústeres es muy grande. El efecto del tamaño del lote en el tiempo computacional también es más evidente cuando el número de conglomerados es mayor. Se puede concluir que, al aumentar el número de conglomerados, disminuye la similitud de la solución K-means del mini lote con la solución K-means. A pesar de que la concordancia entre las particiones disminuye a medida que aumenta el número de conglomerados, la función objetivo no se degrada al mismo ritmo. Significa que las particiones finales son diferentes, pero más cercanas en calidad.
Referencias:
https://upcommons.upc.edu/bitstream/handle/2117/23414/R13-8.pdf
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.MiniBatchKMeans.html
Publicación traducida automáticamente
Artículo escrito por Debomit Dey y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA