Requisito previo: clasificación y regresión
La
clasificación y la regresión son dos problemas importantes de predicción que generalmente se tratan en la minería de datos y el aprendizaje automático.
La clasificación es el proceso de encontrar o descubrir un modelo o función que ayude a separar los datos en múltiples clases categóricas, es decir, valores discretos. En la clasificación, los datos se categorizan bajo diferentes etiquetas de acuerdo con algunos parámetros dados en la entrada y luego se predicen las etiquetas para los datos.
La función de mapeo derivada podría demostrarse en forma de reglas «SI-ENTONCES». El proceso de clasificación se ocupa de los problemas en los que los datos se pueden dividir en etiquetas discretas binarias o múltiples.
Tomemos un ejemplo, supongamos que queremos predecir la posibilidad de que el Equipo A gane un partido en base a algunos parámetros registrados anteriormente. Entonces habría dos etiquetas Sí y No.
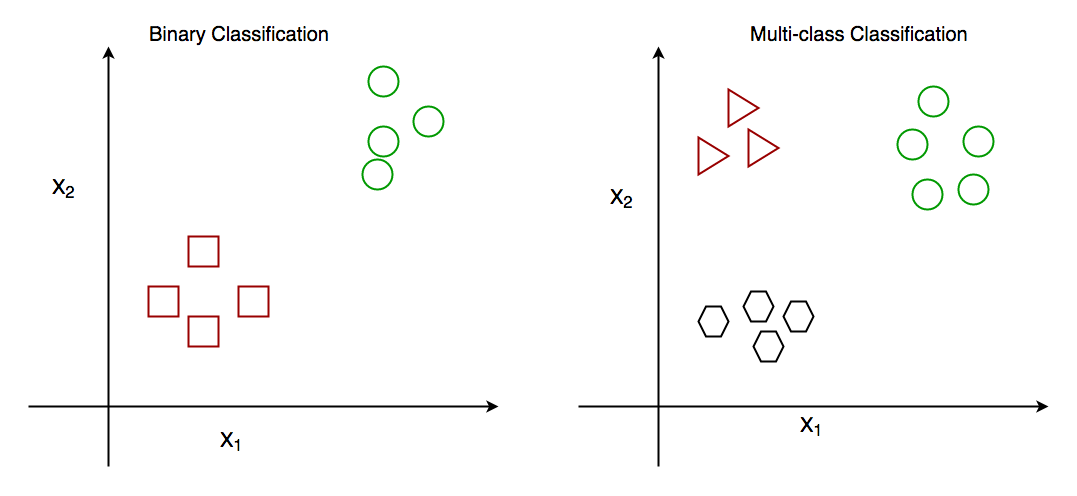
Fig: Clasificación binaria y clasificación multiclase
La regresión es el proceso de encontrar un modelo o función para distinguir los datos en valores reales continuos en lugar de usar clases o valores discretos. También puede identificar el movimiento de distribución en función de los datos históricos. Debido a que un modelo predictivo de regresión predice una cantidad, por lo tanto, la habilidad del modelo debe informarse como un error en esas predicciones.
Tomemos también un ejemplo similar en regresión, donde encontramos la posibilidad de lluvia en algunas regiones particulares con la ayuda de algunos parámetros registrados anteriormente. Entonces hay una probabilidad asociada con la lluvia.
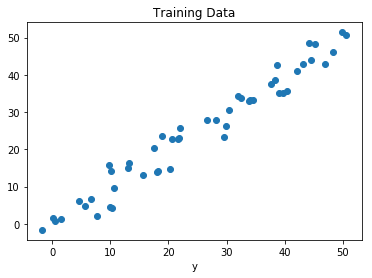
Fig: Regresión de Día vs Precipitación (en mm)
Comparación entre Clasificación y Regresión:
| Parámetro | CLASIFICACIÓN | REGRESIÓN |
|---|---|---|
| Básico | La función de asignación se utiliza para asignar valores a clases predefinidas. | La función de asignación se utiliza para la asignación de valores a la salida continua. |
| Implica la predicción de | Valores discretos | Valores continuos |
| Naturaleza de los datos predichos | desordenado | Ordenado |
| Método de cálculo | midiendo la precisión | por medición del error cuadrático medio de la raíz |
| Algoritmos de ejemplo | Árbol de decisión, regresión logística, etc. | Árbol de regresión (bosque aleatorio), regresión lineal, etc. |
Publicación traducida automáticamente
Artículo escrito por Ankit_Bisht y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA