En el aprendizaje automático, generalmente tratamos con conjuntos de datos que contienen múltiples etiquetas en una o más de una columna. Estas etiquetas pueden tener la forma de palabras o números. Para que los datos sean comprensibles o legibles por humanos, los datos de entrenamiento a menudo se etiquetan con palabras.

La codificación de etiquetas se refiere a convertir las etiquetas en un formato numérico para convertirlas en un formato legible por máquina. Los algoritmos de aprendizaje automático pueden decidir de una mejor manera cómo se deben operar esas etiquetas. Es un paso importante de preprocesamiento para el conjunto de datos estructurados en el aprendizaje supervisado.
Ejemplo:
supongamos que tenemos una altura de columna en algún conjunto de datos.
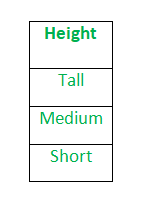
Después de aplicar la codificación de etiquetas, la columna Altura se convierte en:
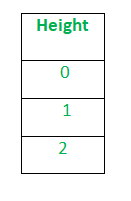
donde 0 es la etiqueta para alto, 1 es la etiqueta para mediano y 2 es una etiqueta para bajo.
Aplicamos la codificación de etiquetas en el conjunto de datos de iris en la columna de destino que es Especie. Contiene tres especies Iris-setosa, Iris-versicolor, Iris-virginica .
Python3
# Import libraries
import numpy as np
import pandas as pd
# Import dataset
df = pd.read_csv('../../data/Iris.csv')
df['species'].unique()
Producción:
array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)
Después de aplicar la codificación de etiquetas:
Python3
# Import label encoder from sklearn import preprocessing # label_encoder object knows how to understand word labels. label_encoder = preprocessing.LabelEncoder() # Encode labels in column 'species'. df['species']= label_encoder.fit_transform(df['species']) df['species'].unique()
Producción:
array([0, 1, 2], dtype=int64)
Limitación de
la codificación de etiquetas La codificación de etiquetas convierte los datos en un formato legible por máquina, pero asigna un número único (a partir de 0) a cada clase de datos. Esto puede conducir a la generación de problemas prioritarios en el entrenamiento de conjuntos de datos. Se puede considerar que una etiqueta con un valor alto tiene mayor prioridad que una etiqueta con un valor más bajo.
Ejemplo
Un atributo que tiene clases de salida Mexico, Paris, Dubai . En la codificación de etiquetas, esta columna permite que México se reemplace con 0 , París se reemplace con 1 y Dubai se reemplace con 2.
Con esto, se puede interpretar que Dubai tiene una prioridad alta que México y París mientras se entrena el modelo, pero en realidad, no existe tal relación de prioridad entre estas ciudades aquí.
Publicación traducida automáticamente
Artículo escrito por aakarsha_chugh y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA