Datos de vivienda de Boston: este conjunto de datos se tomó de la biblioteca StatLib y lo mantiene la Universidad Carnegie Mellon. Este conjunto de datos se refiere a los precios de la vivienda en la ciudad inmobiliaria de Boston. El conjunto de datos provisto tiene 506 instancias con 13 características.
La descripción del conjunto de datos se toma de la siguiente referencia, como se muestra en la siguiente tabla:

Hagamos el modelo de regresión lineal, prediciendo los precios de la vivienda ingresando bibliotecas y conjuntos de datos.
Python3
# Importing Libraries import numpy as np import pandas as pd import matplotlib.pyplot as plt # Importing Data from sklearn.datasets import load_boston boston = load_boston()
La forma de los datos de entrada de Boston y la obtención de nombres_de_características.
Python3
boston.data.shape

Python3
boston.feature_names

Conversión de datos de nd-array a marco de datos y adición de nombres de características a los datos
Python3
data = pd.DataFrame(boston.data) data.columns = boston.feature_names data.head(10)
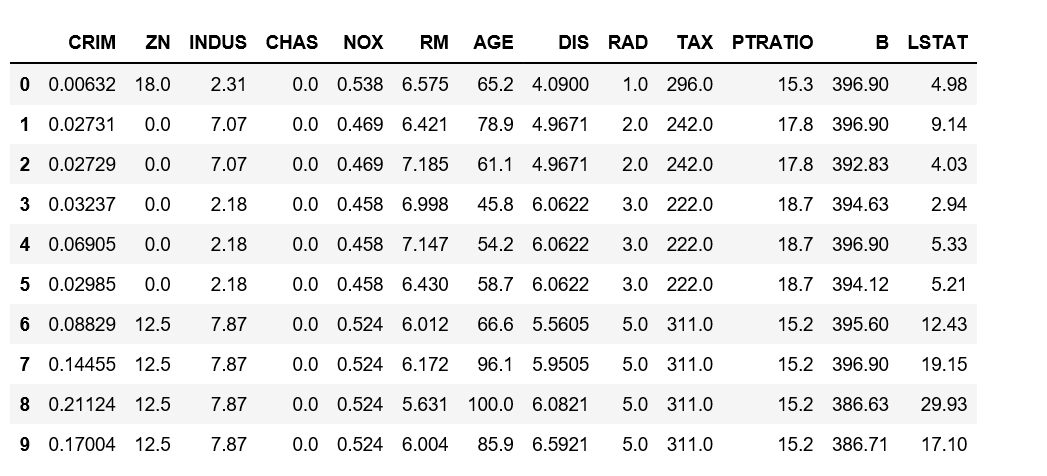
Agregar la columna ‘Precio’ al conjunto de datos
Python3
# Adding 'Price' (target) column to the data boston.target.shape

Python3
data['Price'] = boston.target data.head()
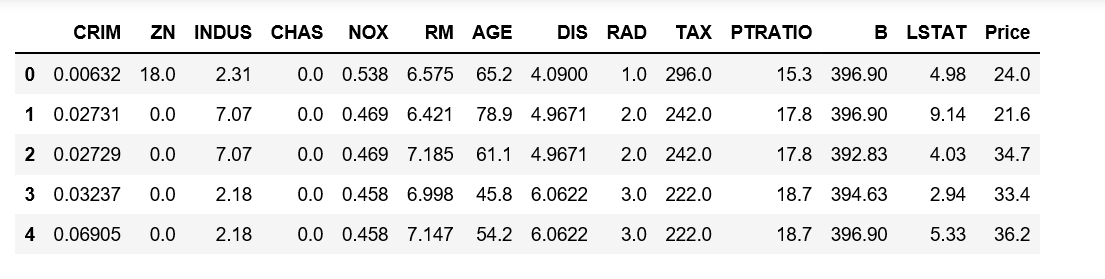
Descripción del conjunto de datos de Boston
Python3
data.describe()
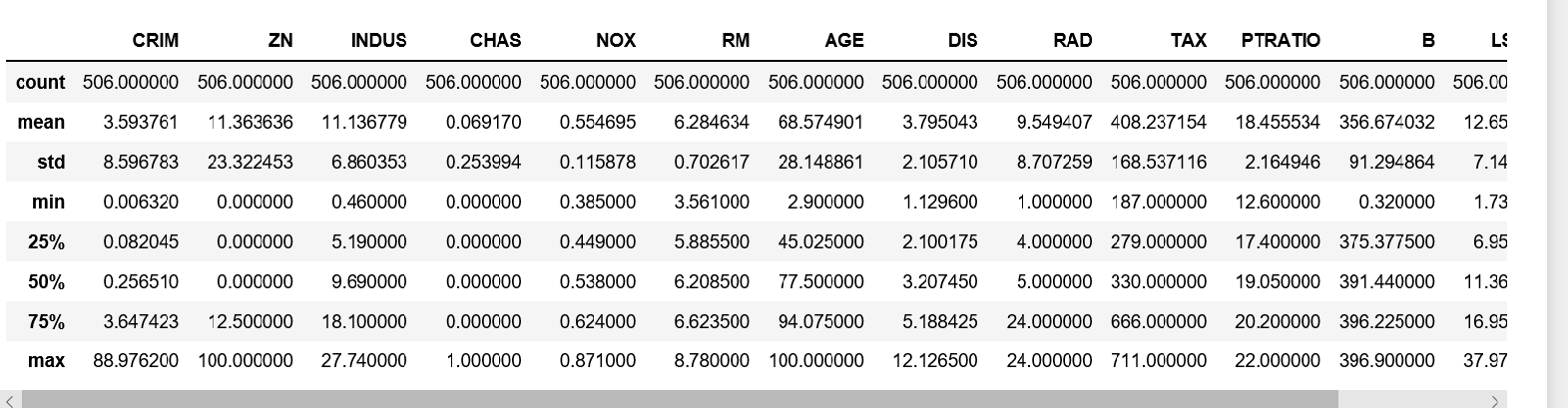
Información del conjunto de datos de Boston
Python3
data.info()
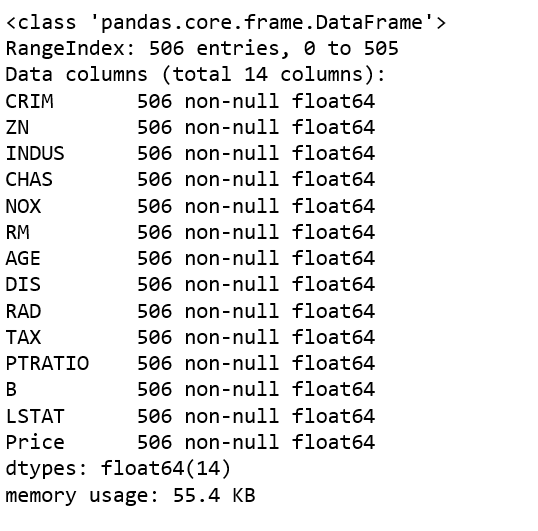
Obtener datos de entrada y salida y dividir aún más los datos para entrenar y probar el conjunto de datos.
Python3
# Input Data
x = boston.data
# Output Data
y = boston.target
# splitting data to training and testing dataset.
#from sklearn.cross_validation import train_test_split
#the submodule cross_validation is renamed and reprecated to model_selection
from sklearn.model_selection import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size =0.2,
random_state = 0)
print("xtrain shape : ", xtrain.shape)
print("xtest shape : ", xtest.shape)
print("ytrain shape : ", ytrain.shape)
print("ytest shape : ", ytest.shape)

Aplicar el modelo de regresión lineal al conjunto de datos y predecir los precios.
Python3
# Fitting Multi Linear regression model to training model from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(xtrain, ytrain) # predicting the test set results y_pred = regressor.predict(xtest)
Trazado del gráfico de dispersión para mostrar los resultados de la predicción: valor ‘y_true’ frente al valor ‘y_pred’.
Python3
# Plotting Scatter graph to show the prediction
# results - 'ytrue' value vs 'y_pred' value
plt.scatter(ytest, y_pred, c = 'green')
plt.xlabel("Price: in $1000's")
plt.ylabel("Predicted value")
plt.title("True value vs predicted value : Linear Regression")
plt.show()
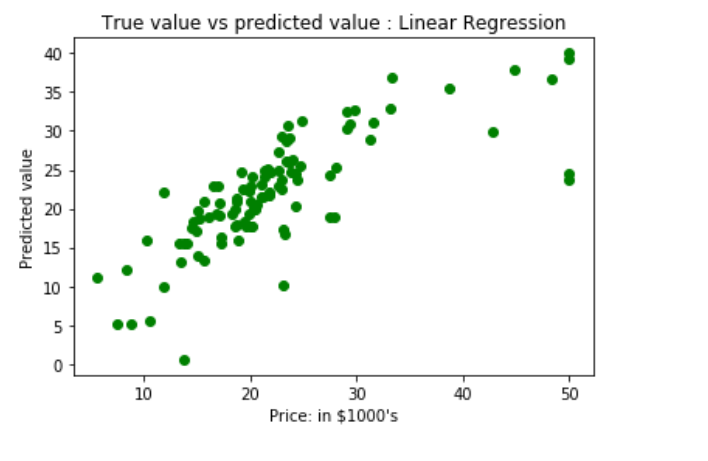
Resultados de la regresión lineal, es decir, error cuadrático medio y error absoluto medio.
Python3
from sklearn.metrics import mean_squared_error, mean_absolute_error
mse = mean_squared_error(ytest, y_pred)
mae = mean_absolute_error(ytest,y_pred)
print("Mean Square Error : ", mse)
print("Mean Absolute Error : ", mae)
Mean Square Error : 33.448979997676496 Mean Absolute Error : 3.8429092204444966
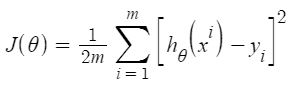
Según el resultado, nuestro modelo solo tiene una precisión del 66,55 %. Entonces, el modelo preparado no es muy bueno para predecir los precios de la vivienda. Se pueden mejorar los resultados de la predicción utilizando muchos otros posibles algoritmos y técnicas de aprendizaje automático.
Aquí hay algunos pasos adicionales sobre cómo puede mejorar su modelo.
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA