El desafío es reconocer las transacciones fraudulentas con tarjetas de crédito para que a los clientes de las compañías de tarjetas de crédito no se les cobre por artículos que no compraron.
Los principales desafíos involucrados en la detección de fraudes con tarjetas de crédito son:
- Se procesan enormes cantidades de datos todos los días y la construcción del modelo debe ser lo suficientemente rápida para responder a la estafa a tiempo.
- Datos desequilibrados, es decir, la mayoría de las transacciones (99,8 %) no son fraudulentas, lo que dificulta mucho la detección de las fraudulentas.
- Disponibilidad de datos ya que los datos son en su mayoría privados.
- Los datos clasificados incorrectamente pueden ser otro problema importante, ya que no todas las transacciones fraudulentas se detectan y denuncian.
- Técnicas adaptativas utilizadas contra el modelo por los estafadores.
¿Cómo abordar estos desafíos?
- El modelo utilizado debe ser lo suficientemente simple y rápido para detectar la anomalía y clasificarla como una transacción fraudulenta lo más rápido posible.
- El desequilibrio se puede tratar utilizando adecuadamente algunos métodos de los que hablaremos en el siguiente párrafo.
- Para proteger la privacidad del usuario se puede reducir la dimensionalidad de los datos.
- Se debe tomar una fuente más confiable que verifique dos veces los datos, al menos para entrenar el modelo.
- Podemos hacer que el modelo sea simple e interpretable para que cuando el estafador se adapte a él con solo algunos ajustes, podamos tener un nuevo modelo en funcionamiento para implementar.
Antes de ir al código se pide trabajar en un cuaderno jupyter. Si no está instalado en su máquina, puede usar Google colab .
Puede descargar el conjunto de datos desde este enlace.
Si el enlace no funciona, vaya a este enlace e inicie sesión en Kaggle para descargar el conjunto de datos.
Código: Importación de todas las bibliotecas necesarias
# import the necessary packages import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from matplotlib import gridspec
Código: cargando los datos
# Load the dataset from the csv file using pandas
# best way is to mount the drive on colab and
# copy the path for the csv file
data = pd.read_csv("credit.csv")
Código: comprensión de los datos
# Grab a peek at the data data.head()

Código: descripción de los datos
# Print the shape of the data # data = data.sample(frac = 0.1, random_state = 48) print(data.shape) print(data.describe())
Producción :
(284807, 31)
Time V1 ... Amount Class
count 284807.000000 2.848070e+05 ... 284807.000000 284807.000000
mean 94813.859575 3.919560e-15 ... 88.349619 0.001727
std 47488.145955 1.958696e+00 ... 250.120109 0.041527
min 0.000000 -5.640751e+01 ... 0.000000 0.000000
25% 54201.500000 -9.203734e-01 ... 5.600000 0.000000
50% 84692.000000 1.810880e-02 ... 22.000000 0.000000
75% 139320.500000 1.315642e+00 ... 77.165000 0.000000
max 172792.000000 2.454930e+00 ... 25691.160000 1.000000
[8 rows x 31 columns]
Código: Desequilibrio en los datos
Momento de explicar los datos que estamos tratando.
# Determine number of fraud cases in dataset
fraud = data[data['Class'] == 1]
valid = data[data['Class'] == 0]
outlierFraction = len(fraud)/float(len(valid))
print(outlierFraction)
print('Fraud Cases: {}'.format(len(data[data['Class'] == 1])))
print('Valid Transactions: {}'.format(len(data[data['Class'] == 0])))
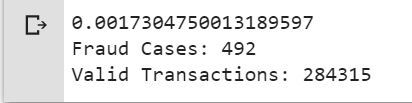
Only 0.17% fraudulent transaction out all the transactions. The data is highly Unbalanced. Lets first apply our models without balancing it and if we don’t get a good accuracy then we can find a way to balance this dataset. But first, let’s implement the model without it and will balance the data only if needed.
Código: Imprima los detalles de la cantidad para la Transacción Fraudulenta
print(“Amount details of the fraudulent transaction”) fraud.Amount.describe()
Producción :
Amount details of the fraudulent transaction count 492.000000 mean 122.211321 std 256.683288 min 0.000000 25% 1.000000 50% 9.250000 75% 105.890000 max 2125.870000 Name: Amount, dtype: float64
Código: Imprima los detalles de la cantidad para la transacción normal
print(“details of valid transaction”) valid.Amount.describe()
Producción :
Amount details of valid transaction count 284315.000000 mean 88.291022 std 250.105092 min 0.000000 25% 5.650000 50% 22.000000 75% 77.050000 max 25691.160000 Name: Amount, dtype: float64
Como podemos notar claramente de esto, la transacción de dinero promedio para los fraudulentos es más. Esto hace que este problema sea crucial para tratar.
Código: trazado de la array de
correlación La array de correlación nos da una idea gráfica de cómo las características se correlacionan entre sí y puede ayudarnos a predecir cuáles son las características que son más relevantes para la predicción.
# Correlation matrix corrmat = data.corr() fig = plt.figure(figsize = (12, 9)) sns.heatmap(corrmat, vmax = .8, square = True) plt.show()

In the HeatMap we can clearly see that most of the features do not correlate to other features but there are some features that either has a positive or a negative correlation with each other. For example, V2 and V5 are highly negatively correlated with the feature called Amount. We also see some correlation with V20 and Amount. This gives us a deeper understanding of the Data available to us.
Código: separación de los valores X e Y.
División de los datos en parámetros de entrada y formato de valor de salida.
# dividing the X and the Y from the dataset X = data.drop(['Class'], axis = 1) Y = data["Class"] print(X.shape) print(Y.shape) # getting just the values for the sake of processing # (its a numpy array with no columns) xData = X.values yData = Y.values
Producción :
(284807, 30) (284807, )
Bifurcación de datos de entrenamiento y prueba Dividiremos
el conjunto de datos en dos grupos principales. Uno para entrenar el modelo y el otro para probar el rendimiento de nuestro modelo entrenado.
# Using Skicit-learn to split data into training and testing sets from sklearn.model_selection import train_test_split # Split the data into training and testing sets xTrain, xTest, yTrain, yTest = train_test_split( xData, yData, test_size = 0.2, random_state = 42)
Código: Construcción de un modelo de bosque aleatorio usando skicit learn
# Building the Random Forest Classifier (RANDOM FOREST) from sklearn.ensemble import RandomForestClassifier # random forest model creation rfc = RandomForestClassifier() rfc.fit(xTrain, yTrain) # predictions yPred = rfc.predict(xTest)
Código: construcción de todo tipo de parámetros de evaluación
# Evaluating the classifier
# printing every score of the classifier
# scoring in anything
from sklearn.metrics import classification_report, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, matthews_corrcoef
from sklearn.metrics import confusion_matrix
n_outliers = len(fraud)
n_errors = (yPred != yTest).sum()
print("The model used is Random Forest classifier")
acc = accuracy_score(yTest, yPred)
print("The accuracy is {}".format(acc))
prec = precision_score(yTest, yPred)
print("The precision is {}".format(prec))
rec = recall_score(yTest, yPred)
print("The recall is {}".format(rec))
f1 = f1_score(yTest, yPred)
print("The F1-Score is {}".format(f1))
MCC = matthews_corrcoef(yTest, yPred)
print("The Matthews correlation coefficient is{}".format(MCC))
Producción :
The model used is Random Forest classifier The accuracy is 0.9995611109160493 The precision is 0.9866666666666667 The recall is 0.7551020408163265 The F1-Score is 0.8554913294797689 The Matthews correlation coefficient is0.8629589216367891
Código: visualización de la array de confusión
# printing the confusion matrix
LABELS = ['Normal', 'Fraud']
conf_matrix = confusion_matrix(yTest, yPred)
plt.figure(figsize =(12, 12))
sns.heatmap(conf_matrix, xticklabels = LABELS,
yticklabels = LABELS, annot = True, fmt ="d");
plt.title("Confusion matrix")
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.show()
Producción :

Comparación con otros algoritmos sin tratar el desequilibrio de los datos.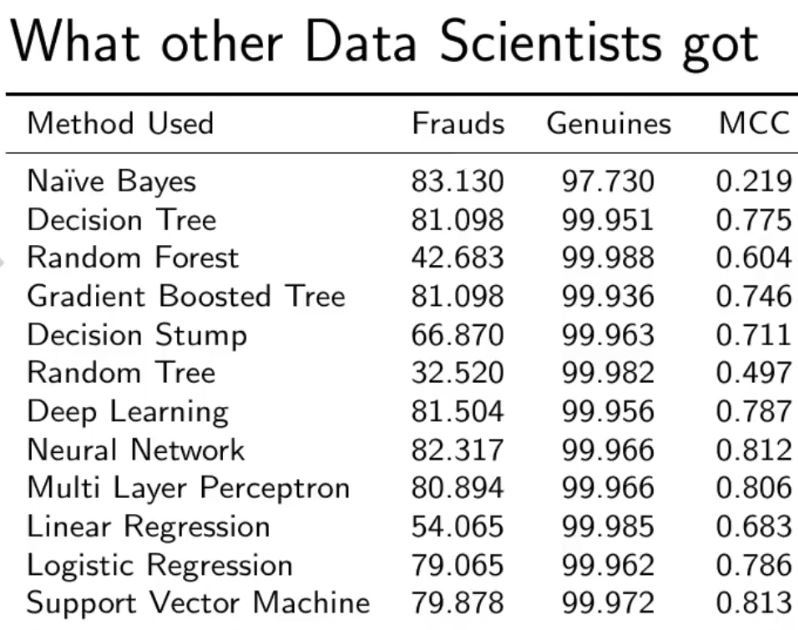
Como puede ver con nuestro modelo de bosque aleatorio, estamos obteniendo un mejor resultado incluso para la recuperación, que es la parte más complicada.
Publicación traducida automáticamente
Artículo escrito por amankrsharma3 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA