Este artículo demostrará cómo crear un generador de texto mediante la creación de una red de unidades recurrentes cerradas . El procedimiento conceptual de entrenamiento de la red es primero alimentar a la red con un mapeo de cada carácter presente en el texto en el que la red está entrenando a un número único. Luego, cada carácter se codifica en caliente en un vector que es el formato requerido para la red.
Los datos para el procedimiento descrito son una colección de poemas cortos y famosos de poetas famosos y están en formato .txt. Se puede descargar desde aquí .
Paso 1: Importación de las bibliotecas requeridas
Python3
from __future__ import absolute_import, division, print_function, unicode_literals import numpy as np import tensorflow as tf from keras.models import Sequential from keras.layers import Dense, Activation from keras.layers import LSTM from keras.optimizers import RMSprop from keras.callbacks import LambdaCallback from keras.callbacks import ModelCheckpoint from keras.callbacks import ReduceLROnPlateau import random import sys
Paso 2: cargando los datos en una string
Python3
# Changing the working location to the location of the text file
cd C:\Users\Dev\Desktop\Kaggle\Poems
# Reading the text file into a string
with open('poems.txt', 'r') as file:
text = file.read()
# A preview of the text file
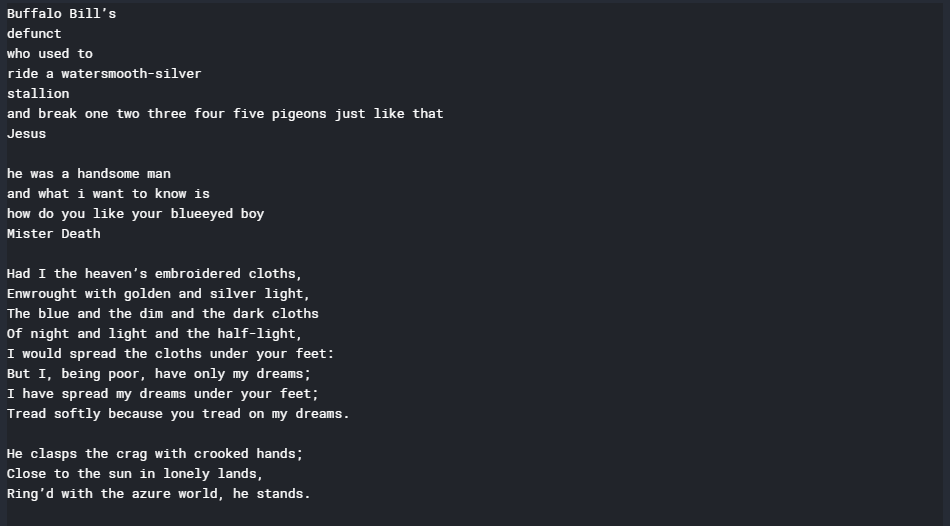
print(text)
Paso 3: crear una asignación de cada carácter único en el texto a un número único
Python3
# Storing all the unique characters present in the text vocabulary = sorted(list(set(text))) # Creating dictionaries to map each character to an index char_to_indices = dict((c, i) for i, c in enumerate(vocabulary)) indices_to_char = dict((i, c) for i, c in enumerate(vocabulary)) print(vocabulary)

Paso 4: preprocesamiento de los datos
Python3
# Dividing the text into subsequences of length max_length # So that at each time step the next max_length characters # are fed into the network max_length = 100 steps = 5 sentences = [] next_chars = [] for i in range(0, len(text) - max_length, steps): sentences.append(text[i: i + max_length]) next_chars.append(text[i + max_length]) # Hot encoding each character into a boolean vector # Initializing a matrix of boolean vectors with each column representing # the hot encoded representation of the character X = np.zeros((len(sentences), max_length, len(vocabulary)), dtype = np.bool) y = np.zeros((len(sentences), len(vocabulary)), dtype = np.bool) # Placing the value 1 at the appropriate position for each vector # to complete the hot-encoding process for i, sentence in enumerate(sentences): for t, char in enumerate(sentence): X[i, t, char_to_indices[char]] = 1 y[i, char_to_indices[next_chars[i]]] = 1
Paso 5: Construcción de la red GRU
Python3
# Initializing the LSTM network
model = Sequential()
# Defining the cell type
model.add(GRU(128, input_shape =(max_length, len(vocabulary))))
# Defining the densely connected Neural Network layer
model.add(Dense(len(vocabulary)))
# Defining the activation function for the cell
model.add(Activation('softmax'))
# Defining the optimizing function
optimizer = RMSprop(lr = 0.01)
# Configuring the model for training
model.compile(loss ='categorical_crossentropy', optimizer = optimizer)
Paso 6: Definición de algunas funciones auxiliares que se utilizarán durante el entrenamiento de la red.
Tenga en cuenta que las dos primeras funciones que se indican a continuación se han extraído de la documentación del ejemplo de generación de texto oficial del equipo de Keras .
a) Función auxiliar para muestrear el siguiente carácter:
Python3
# Helper function to sample an index from a probability array
def sample_index(preds, temperature = 1.0):
# temperature determines the freedom the function has when generating text
# Converting the predictions vector into a numpy array
preds = np.asarray(preds).astype('float64')
# Normalizing the predictions array
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
# The main sampling step. Creates an array of probabilities signifying
# the probability of each character to be the next character in the
# generated text
probas = np.random.multinomial(1, preds, 1)
# Returning the character with maximum probability to be the next character
# in the generated text
return np.argmax(probas)
b) Función auxiliar para generar texto después de cada época .
Python3
# Helper function to generate text after the end of each epoch
def on_epoch_end(epoch, logs):
print()
print('----- Generating text after Epoch: % d' % epoch)
# Choosing a random starting index for the text generation
start_index = random.randint(0, len(text) - max_length - 1)
# Sampling for different values of diversity
for diversity in [0.2, 0.5, 1.0, 1.2]:
print('----- diversity:', diversity)
generated = ''
# Seed sentence
sentence = text[start_index: start_index + max_length]
generated += sentence
print('----- Generating with seed: "' + sentence + '"')
sys.stdout.write(generated)
for i in range(400):
# Initializing the predictions vector
x_pred = np.zeros((1, max_length, len(vocabulary)))
for t, char in enumerate(sentence):
x_pred[0, t, char_to_indices[char]] = 1.
# Making the predictions for the next character
preds = model.predict(x_pred, verbose = 0)[0]
# Getting the index of the most probable next character
next_index = sample_index(preds, diversity)
# Getting the most probable next character using the mapping built
next_char = indices_to_char[next_index]
# Building the generated text
generated += next_char
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
print()
# Defining a custom callback function to
# describe the internal states of the network
print_callback = LambdaCallback(on_epoch_end = on_epoch_end)
c) Función auxiliar para guardar el modelo después de cada época en la que disminuye la pérdida
Python3
# Defining a helper function to save the model after each epoch # in which the loss decreases filepath = "weights.hdf5" checkpoint = ModelCheckpoint(filepath, monitor ='loss', verbose = 1, save_best_only = True, mode ='min')
d) Función auxiliar para reducir la tasa de aprendizaje cada vez que el aprendizaje se estanca
Python3
# Defining a helper function to reduce the learning rate each time # the learning plateaus reduce_alpha = ReduceLROnPlateau(monitor ='loss', factor = 0.2, patience = 1, min_lr = 0.001) callbacks = [print_callback, checkpoint, reduce_alpha]
Paso 7: Entrenamiento del modelo GRU
Python3
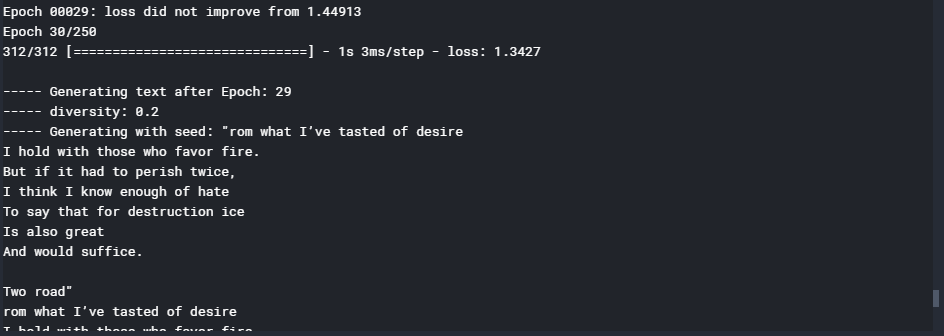
# Training the GRU model model.fit(X, y, batch_size = 128, epochs = 30, callbacks = callbacks)
Paso 8: Generación de texto nuevo y aleatorio
Python3
def generate_text(length, diversity): # Get random starting text start_index = random.randint(0, len(text) - max_length - 1) # Defining the generated text generated = '' sentence = text[start_index: start_index + max_length] generated += sentence # Generating new text of given length for i in range(length): # Initializing the prediction vector x_pred = np.zeros((1, max_length, len(vocabulary))) for t, char in enumerate(sentence): x_pred[0, t, char_to_indices[char]] = 1. # Making the predictions preds = model.predict(x_pred, verbose = 0)[0] # Getting the index of the next most probable index next_index = sample_index(preds, diversity) # Getting the most probable next character using the mapping built next_char = indices_to_char[next_index] # Generating new text generated += next_char sentence = sentence[1:] + next_char return generated print(generate_text(500, 0.2))
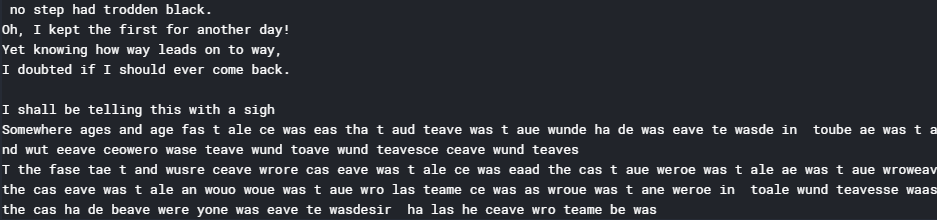
Nota: Aunque la salida no tiene mucho sentido ahora, la salida se puede mejorar significativamente entrenando el modelo para más épocas.
Publicación traducida automáticamente
Artículo escrito por AlindGupta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA