Requisito previo: Algoritmo de vecinos más cercanos K
K-Nearest Neighbors es uno de los algoritmos de clasificación más básicos pero esenciales en Machine Learning. Pertenece al dominio de aprendizaje supervisado y encuentra una intensa aplicación en el reconocimiento de patrones, minería de datos y detección de intrusos. Es ampliamente disponible en escenarios de la vida real ya que no es paramétrico, lo que significa que no hace suposiciones subyacentes sobre la distribución de datos (a diferencia de otros algoritmos como GMM, que asume una distribución gaussiana de los datos dados) .
Este artículo demostrará cómo implementar el algoritmo clasificador de vecinos K-Nearest utilizando la biblioteca Sklearn de Python.
Paso 1: Importación de las bibliotecas requeridas
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier import matplotlib.pyplot as plt import seaborn as sns
Paso 2: Lectura del conjunto de datos
cd C:\Users\Dev\Desktop\Kaggle\Breast_Cancer
# Changing the read file location to the location of the file
df = pd.read_csv('data.csv')
y = df['diagnosis']
X = df.drop('diagnosis', axis = 1)
X = X.drop('Unnamed: 32', axis = 1)
X = X.drop('id', axis = 1)
# Separating the dependent and independent variable
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3, random_state = 0)
# Splitting the data into training and testing data
Paso 3: Entrenamiento del modelo
K = []
training = []
test = []
scores = {}
for k in range(2, 21):
clf = KNeighborsClassifier(n_neighbors = k)
clf.fit(X_train, y_train)
training_score = clf.score(X_train, y_train)
test_score = clf.score(X_test, y_test)
K.append(k)
training.append(training_score)
test.append(test_score)
scores[k] = [training_score, test_score]
Paso 4: Evaluación del modelo
for keys, values in scores.items(): print(keys, ':', values)

We now try to find the optimum value for ‘k’ ie the number of nearest neighbors.
Paso 5: Trazar el gráfico de puntajes de entrenamiento y prueba
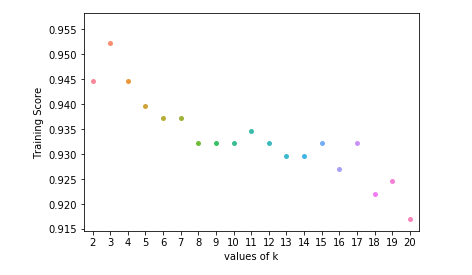
ax = sns.stripplot(K, training); ax.set(xlabel ='values of k', ylabel ='Training Score') plt.show() # function to show plot
ax = sns.stripplot(K, test); ax.set(xlabel ='values of k', ylabel ='Test Score') plt.show()

plt.scatter(K, training, color ='k') plt.scatter(K, test, color ='g') plt.show() # For overlapping scatter plots
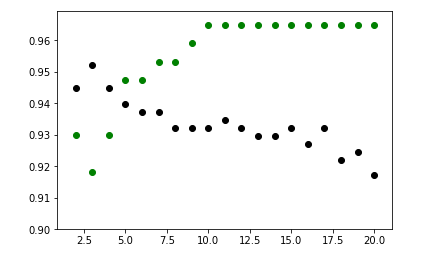
From the above scatter plot, we can come to the conclusion that the optimum value of k will be around 5.
Publicación traducida automáticamente
Artículo escrito por AlindGupta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA