La Organización Mundial de la Salud ha estimado que cuatro de cada cinco muertes por enfermedades cardiovasculares (ECV) se deben a ataques cardíacos. Toda esta investigación tiene la intención de identificar la proporción de pacientes que tienen una buena probabilidad de verse afectados por ECV y también de predecir el riesgo general utilizando la regresión logística.
¿Qué es la regresión logística?
La regresión logística es una técnica estadística y de aprendizaje automático que clasifica los registros de un conjunto de datos en función de los valores de los campos de entrada. Predice una variable dependiente basada en uno o más conjuntos de variables independientes para predecir resultados. Se puede utilizar tanto para la clasificación binaria como para la clasificación multiclase. Para saber más al respecto, haz clic aquí.
Código: Cargando las bibliotecas.
Python3
import pandas as pd import pylab as pl import numpy as np import scipy.optimize as opt import statsmodels.api as sm from sklearn import preprocessing 'exec(% matplotlib inline)' import matplotlib.pyplot as plt import matplotlib.mlab as mlab import seaborn as sn
Preparación de datos:
el conjunto de datos está disponible públicamente en el sitio web de Kaggle y proviene de un estudio cardiovascular en curso en los residentes de la ciudad de Framingham, Massachusetts. El objetivo de la clasificación es predecir si el paciente tiene un riesgo de 10 años de enfermedad coronaria (CHD) en el futuro. El conjunto de datos proporciona la información de los pacientes. Incluye más de 4.000 registros y 15 atributos .
Cargando el conjunto de datos.
Python3
# dataset
disease_df = pd.read_csv("../input / framingham.csv")
disease_df.drop(['education'], inplace = True, axis = 1)
disease_df.rename(columns ={'male':'Sex_male'}, inplace = True)
# removing NaN / NULL values
disease_df.dropna(axis = 0, inplace = True)
print(disease_df.head(), disease_df.shape)
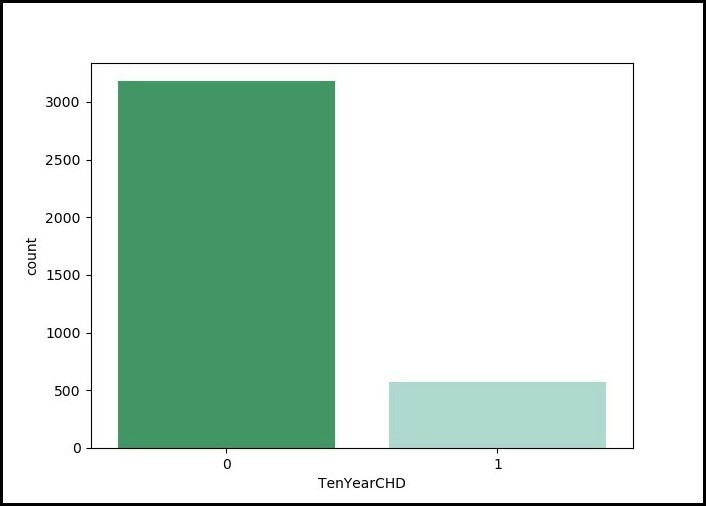
print(disease_df.TenYearCHD.value_counts())
Producción :
Sex_male age currentSmoker ... heartRate glucose TenYearCHD 0 1 39 0 ... 80.0 77.0 0 1 0 46 0 ... 95.0 76.0 0 2 1 48 1 ... 75.0 70.0 0 3 0 61 1 ... 65.0 103.0 1 4 0 46 1 ... 85.0 85.0 0 [5 rows x 15 columns] (3751, 15) 0 3179 1 572 Name: TenYearCHD, dtype: int64
Código: CHD de diez años Registro de todos los pacientes disponibles en el conjunto de datos:
Python3
# counting no. of patients affected with CHD plt.figure(figsize = (7, 5)) sn.countplot(x ='TenYearCHD', data = disease_df, palette ="BuGn_r" ) plt.show()
Salida: Pantalla gráfica:
Código: Contando el número de pacientes afectados por CHD donde (0= No Afectado; 1= Afectado) :
Python3
laste = disease_df['TenYearCHD'].plot() plt.show(laste)
Salida: Visualización gráfica:
Código: Conjuntos de entrenamiento y prueba: División de datos | Normalización del conjunto de datos
Python3
X = np.asarray(disease_df[['age', 'Sex_male', 'cigsPerDay',
'totChol', 'sysBP', 'glucose']])
y = np.asarray(disease_df['TenYearCHD'])
# normalization of the dataset
X = preprocessing.StandardScaler().fit(X).transform(X)
# Train-and-Test -Split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3, random_state = 4)
print ('Train set:', X_train.shape, y_train.shape)
print ('Test set:', X_test.shape, y_test.shape)
Producción :
Train Set : (2625, 6) (2625, ) Test Set : (1126, 6) (1126, )
Código: Modelado del Dataset | Evaluación y precisión:
Python3
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
# Evaluation and accuracy
from sklearn.metrics import jaccard_similarity_score
print('')
print('Accuracy of the model in jaccard similarity score is = ',
jaccard_similarity_score(y_test, y_pred))
Producción :
Accuracy of the model in jaccard similarity score is = 0.8490230905861457
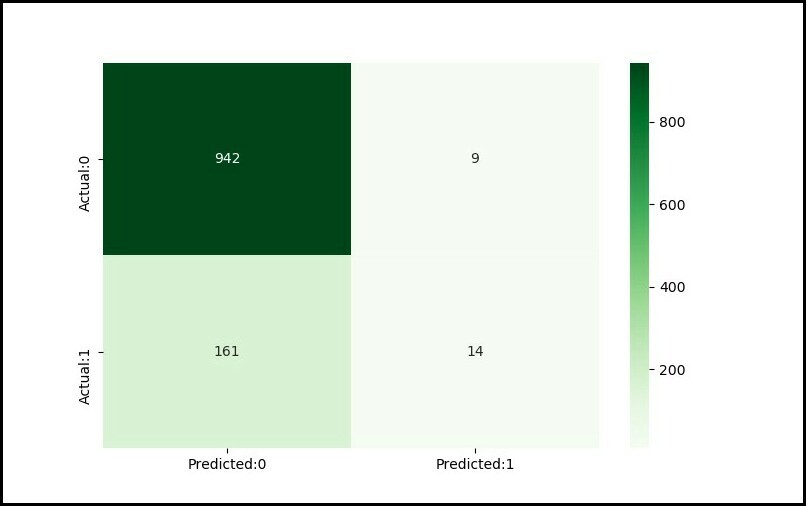
Código: uso de la array de confusión para encontrar la precisión del modelo:
Python3
# Confusion matrix
from sklearn.metrics import confusion_matrix, classification_report
cm = confusion_matrix(y_test, y_pred)
conf_matrix = pd.DataFrame(data = cm,
columns = ['Predicted:0', 'Predicted:1'],
index =['Actual:0', 'Actual:1'])
plt.figure(figsize = (8, 5))
sn.heatmap(conf_matrix, annot = True, fmt = 'd', cmap = "Greens")
plt.show()
print('The details for confusion matrix is =')
print (classification_report(y_test, y_pred))
# This code is contributed by parna_28 .
Producción :
The details for confusion matrix is =
precision recall f1-score support
0 0.85 0.99 0.92 951
1 0.61 0.08 0.14 175
accuracy 0.85 1126
macro avg 0.73 0.54 0.53 1126
weighted avg 0.82 0.85 0.80 1126
Array de confusión :