Inception net logró un hito en los clasificadores CNN cuando los modelos anteriores solo profundizaban para mejorar el rendimiento y la precisión, pero comprometían el costo computacional. La red Inception, por otro lado, está fuertemente diseñada. Utiliza muchos trucos para impulsar el rendimiento, tanto en términos de velocidad como de precisión. Es el ganador del Concurso de reconocimiento visual a gran escala ImageNet en 2014, un concurso de clasificación de imágenes, que tiene una mejora significativa con respecto a ZFNet (El ganador en 2013), AlexNet (El ganador en 2012) y tiene una tasa de error relativamente más baja en comparación con el VGGNet (primer finalista en 2014).
Los principales problemas que enfrentaron los modelos más profundos de CNN, como VGGNet, fueron:
- Aunque las redes anteriores, como VGG, lograron una precisión notable en el conjunto de datos de ImageNet, la implementación de este tipo de modelos es altamente costosa desde el punto de vista computacional debido a la arquitectura profunda.
- Las redes muy profundas son susceptibles de sobreajuste. También es difícil pasar actualizaciones de gradiente a través de toda la red.
Antes de profundizar en el modelo Inception Net, es esencial conocer un concepto importante que se utiliza en la red Inception:
Convolución 1 X 1: una convolución 1 × 1 simplemente asigna un píxel de entrada con todos sus canales respectivos a un píxel de salida. La convolución 1 × 1 se utiliza como un módulo de reducción de dimensionalidad para reducir el cálculo hasta cierto punto.
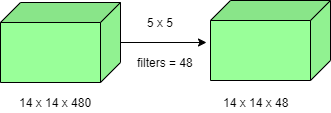
El número de operaciones involucradas aquí es (14×14×48) × (5×5×480) = 112.9M
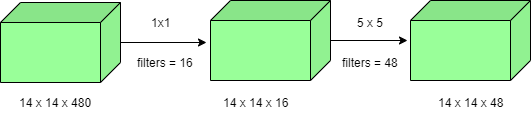
Número de operaciones para convolución 1×1 = (14×14×16) × (1×1×480) = 1,5M
Número de operaciones para convolución 5×5 = (14×14×48) × (5×5×16) ) = 3,8M
Después de la suma obtenemos, 1,5M + 3,8M = 5,3M
¡Lo cual es inmensamente más pequeño que 112.9M! Por lo tanto, la convolución 1 × 1 puede ayudar a reducir el tamaño del modelo, lo que también puede ayudar de alguna manera a reducir el problema de sobreajuste.
Modelo de inicio con reducciones de dimensión: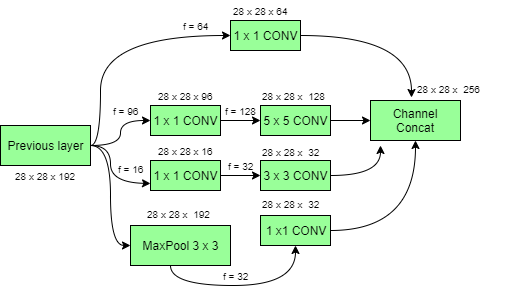
Las redes convolucionales profundas son computacionalmente costosas. Sin embargo, los costos computacionales se pueden reducir drásticamente al introducir una convolución de 1 x 1 . Aquí, el número de canales de entrada está limitado al agregar una convolución adicional de 1×1 antes de las convoluciones de 3×3 y 5×5 . Aunque agregar una operación adicional puede parecer contrario a la intuición, las circunvoluciones 1×1 son mucho más baratas que las circunvoluciones 5×5 . Tenga en cuenta que la convolución 1 × 1 se introduce después de la capa de agrupación máxima, en lugar de antes. Por último, todos los canales de la red se concatenan juntos, es decir , (28 x 28 x (64 + 128 + 32 + 32)) = 28 x 28 x 256.
Arquitectura GoogLeNet de Inception Network:
¡ Esta arquitectura tiene 22 capas en total! Usando el módulo de inicio de dimensiones reducidas, se construye una arquitectura de red neuronal. Esto se conoce popularmente como GoogLeNet (Inception v1) . GoogLeNet tiene 9 módulos iniciales de este tipo instalados linealmente. Tiene 22 capas de profundidad ( 27 , incluidas las capas de agrupación). Al final de la arquitectura, las capas totalmente conectadas fueron reemplazadas por una agrupación promedio global que calcula el promedio de cada mapa de características. De hecho, esto reduce drásticamente el número total de parámetros.
Por lo tanto, Inception Net es una victoria sobre las versiones anteriores de los modelos CNN. Alcanza una precisión de los 5 primeros en ImageNet, reduce el costo computacional en gran medida sin comprometer la velocidad y la precisión.
Publicación traducida automáticamente
Artículo escrito por Dolly_Vaishnav y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA