Base de datos de usuarios: este conjunto de datos contiene información sobre los usuarios de la base de datos de una empresa. Contiene información sobre ID de usuario, sexo, edad, salario estimado y compra. Estamos utilizando este conjunto de datos para predecir si un usuario comprará o no el producto recién lanzado por la empresa.
Prerrequisito: comprensión de la regresión logística
Consulte la siguiente tabla desde donde se obtienen los datos del conjunto de datos.
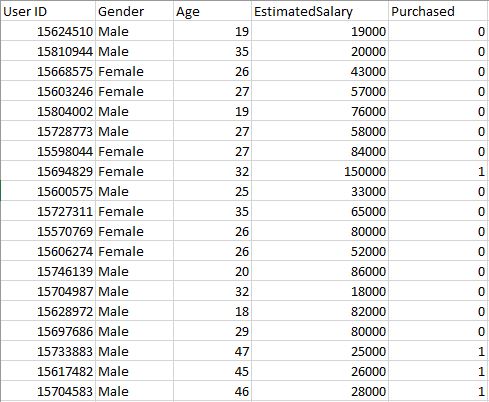
Hagamos el modelo de Regresión Logística, prediciendo si un usuario comprará el producto o no.
Introducción de bibliotecas.
Importar bibliotecas
import pandas as pd import numpy as np import matplotlib.pyplot as plt
Leer y explorar los datos
Python3
dataset = pd.read_csv("User_Data.csv")
Ahora, para predecir si un usuario comprará el producto o no, es necesario averiguar la relación entre la edad y el salario estimado. Aquí el ID de usuario y el género no son factores importantes para averiguarlo.
Python3
# input x = dataset.iloc[:, [2, 3]].values # output y = dataset.iloc[:, 4].values
Dividir el conjunto de datos: entrenar y probar el conjunto de datos
Dividir el conjunto de datos para entrenar y probar. El 75 % de los datos se utiliza para entrenar el modelo y el 25 % se utiliza para probar el rendimiento de nuestro modelo.
Python3
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state = 0)
Ahora, es muy importante realizar escalado de características aquí porque los valores de Edad y Salario estimado se encuentran en diferentes rangos. Si no escalamos las funciones, la función Salario estimado dominará la función Edad cuando el modelo encuentre el vecino más cercano a un punto de datos en el espacio de datos.
Python3
from sklearn.preprocessing import StandardScaler sc_x = StandardScaler() xtrain = sc_x.fit_transform(xtrain) xtest = sc_x.transform(xtest) print (xtrain[0:10, :])
Producción:
[[ 0.58164944 -0.88670699] [-0.60673761 1.46173768] [-0.01254409 -0.5677824 ] [-0.60673761 1.89663484] [ 1.37390747 -1.40858358] [ 1.47293972 0.99784738] [ 0.08648817 -0.79972756] [-0.01254409 -0.24885782] [-0.21060859 -0.5677824 ] [-0.21060859 -0.19087153]]
Aquí una vez que vea que los valores de las características Edad y Salario estimado están escalados y ahora están en -1 a 1. Por lo tanto, cada característica contribuirá igualmente a la toma de decisiones, es decir, finalizar la hipótesis.
Finalmente, estamos entrenando nuestro modelo de Regresión Logística.
entrenar el modelo
Python3
from sklearn.linear_model import LogisticRegression classifier = LogisticRegression(random_state = 0) classifier.fit(xtrain, ytrain)
Después de entrenar el modelo, es hora de usarlo para hacer predicciones sobre los datos de prueba.
Python3
y_pred = classifier.predict(xtest)
Probemos el desempeño de nuestro modelo – Confusion Matrix
Métricas de evaluación
Las métricas se utilizan para verificar el rendimiento del modelo en valores predichos y valores reales.
Python3
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(ytest, y_pred)
print ("Confusion Matrix : \n", cm)
Producción:
Confusion Matrix : [[65 3] [ 8 24]]
De 100:
Verdadero positivo + Verdadero negativo = 65 + 24
Falso positivo + Falso negativo = 3 + 8
Medida de rendimiento: precisión
Ejemplo
Python3
from sklearn.metrics import accuracy_score
print ("Accuracy : ", accuracy_score(ytest, y_pred))
Producción:
Accuracy : 0.89
Visualizando el rendimiento de nuestro modelo.
Python3
from matplotlib.colors import ListedColormap
X_set, y_set = xtest, ytest
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(
np.array([X1.ravel(), X2.ravel()]).T).reshape(
X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Classifier (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
Producción:
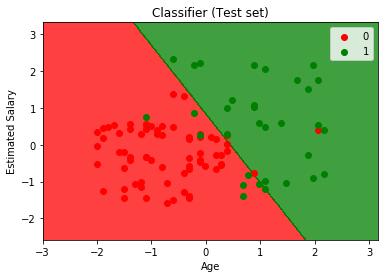
Al analizar las medidas de rendimiento: la array de precisión y confusión y el gráfico, podemos decir claramente que nuestro modelo está funcionando muy bien.
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA