Esta es la regresión lineal de mínimos cuadrados ordinarios de sklearn.linear_module.
Sintaxis:
sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1):
Parámetros:
fit_intercept : [boolean, Default is True] Si se calcula la intersección para el modelo.
normalizar: [booleano, el valor predeterminado es falso] Normalización antes de la regresión.
copy_X: [booleano, el valor predeterminado es verdadero] Si es verdadero, se sobrescribe una copia de X.
n_jobs: [int, el valor predeterminado es 1] Si -1 se utilizan todas las CPU. Esto acelerará el trabajo para procesar grandes conjuntos de datos.
En el conjunto de datos dado, el gasto en I+D, el costo de administración y el gasto en marketing de 50 empresas se dan junto con las ganancias obtenidas. El objetivo es preparar un modelo ML que pueda predecir el valor de las ganancias de una empresa si se proporciona el valor de su gasto en I + D, costo de administración y gasto en marketing. 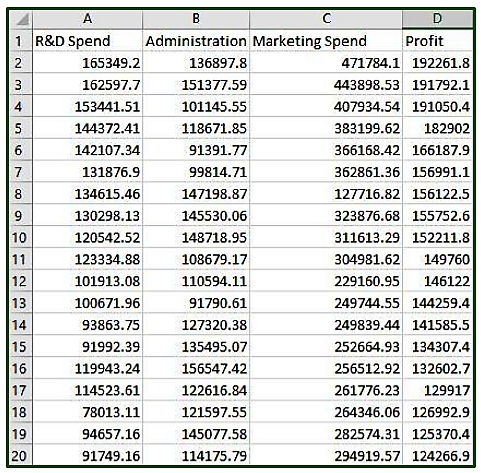
Para descargar el conjunto de datos, haga clic aquí .
Código: Uso de Regresión Lineal para Predecir el Beneficio de las Empresas
# Importing the libraries
import numpy as np
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('https://media.geeksforgeeks.org/wp-content/uploads/50_Startups.csv')
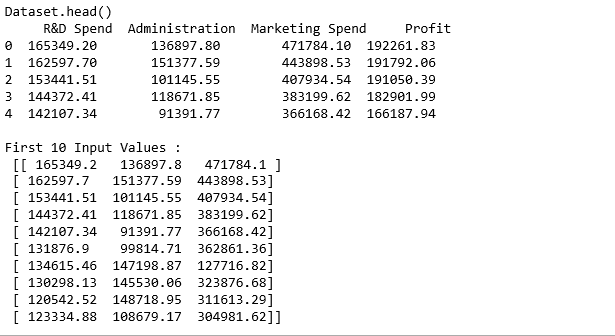
print ("Dataset.head() \n ", dataset.head())
# Input values
x = dataset.iloc[:, :-1].values
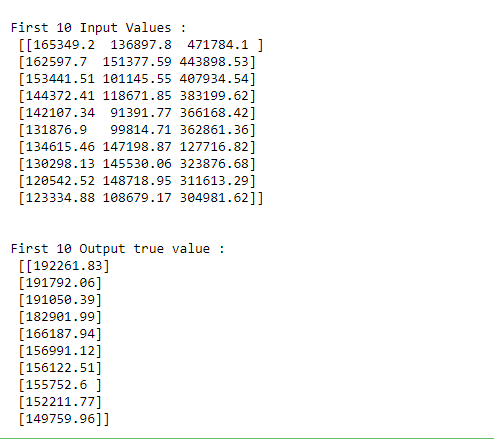
print("\nFirst 10 Input Values : \n", x[0:10, :])
print ("Dataset Info : \n")
print (dataset.info())

# Input values
x = dataset.iloc[:, :-1].values
print("\nFirst 10 Input Values : \n", x[0:10, :])
# Output values
y = dataset.iloc[:, 3].values
y1 = y
y1 = y1.reshape(-1, 1)
print("\n\nFirst 10 Output true value : \n", y1[0:10, :])
# Dividing input and output data to train and test data
# Training : Testing = 80 : 20
from sklearn.cross_validation import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size = 0.2,
random_state = 0)
# Feature Scaling
# Multilinear regression takes care of Feature Scaling
# So we need not do it manually
# Fitting Multi Linear regression model to training model
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(xtrain, ytrain)
# predicting the test set results
y_pred = regressor.predict(xtest)
y_pred1 = y_pred
y_pred1 = y_pred1.reshape(-1,1)
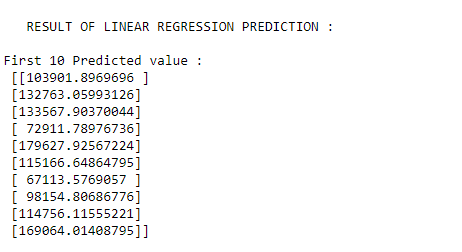
print("\n RESULT OF LINEAR REGRESSION PREDICTION : ")
print ("\nFirst 10 Predicted value : \n", y_pred1[0:10, :])
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA