La trampa de inicialización aleatoria es un problema que ocurre en el algoritmo K-means. En la trampa de inicialización aleatoria, cuando el usuario define explícitamente los centroides de los conglomerados que se van a generar, se pueden crear incoherencias y, en ocasiones, esto puede generar la generación de conglomerados incorrectos en el conjunto de datos. Por lo tanto, la trampa de inicialización aleatoria a veces puede evitar que desarrollemos los clústeres correctos.
Ejemplo:
suponga que tiene un conjunto de datos con los siguientes puntos que se muestran en la imagen y desea generar tres conglomerados en este conjunto de datos de acuerdo con sus atributos mediante la realización de conglomerados de K-means. De la figura, podemos intuir cuáles son los clústeres que se requieren generar. K-means realizará la agrupación en clústeres sobre la base de los centroides introducidos en el algoritmo y generará los clústeres requeridos de acuerdo con estos centroides.

Primera prueba
Supongamos que elegimos 3 conjuntos de centroides de acuerdo con la figura que se muestra a continuación. Los grupos que se generan correspondientes a estos centroides se muestran en la siguiente figura.
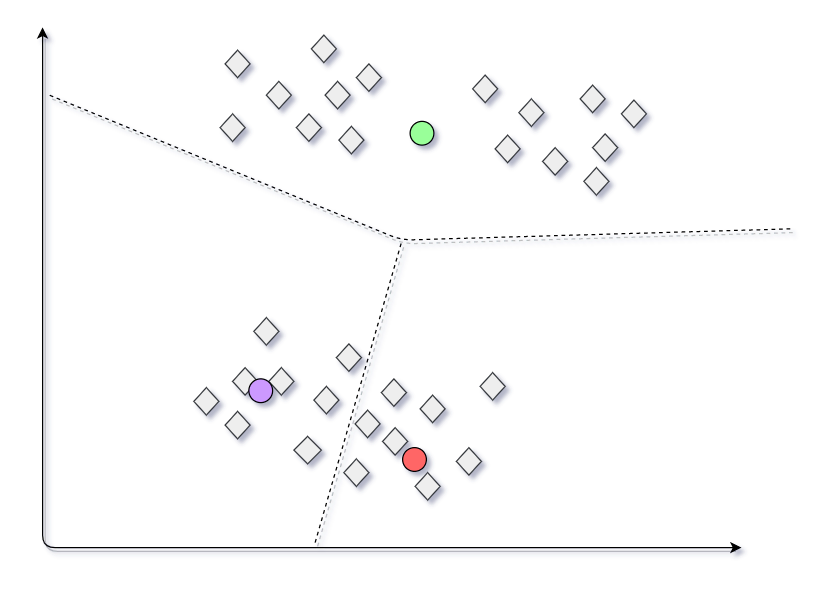
modelo definitivo

Segundo intento
Considere otro caso en el que elegimos otro conjunto de centroides para el conjunto de datos como se muestra. Ahora el conjunto de conglomerados generados será diferente a los conglomerados generados en la práctica anterior.
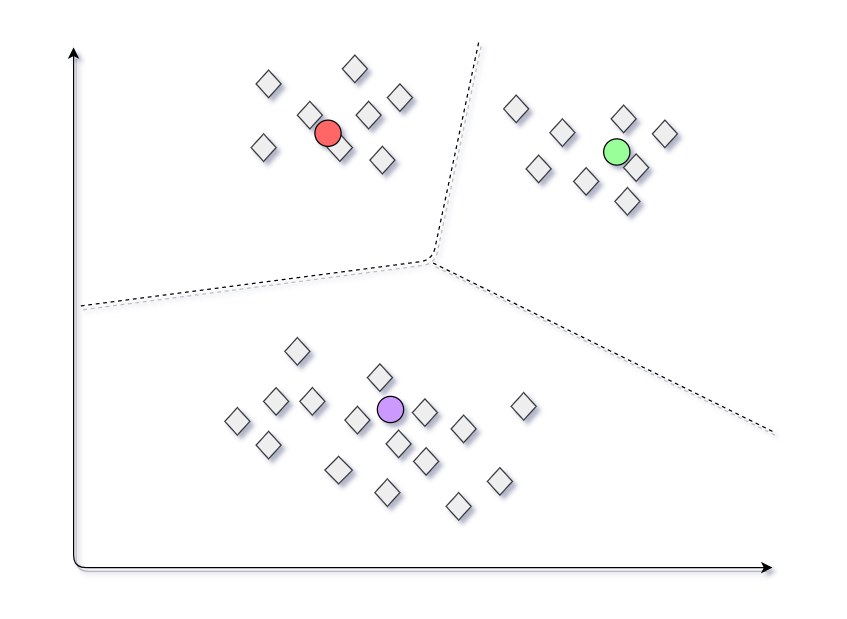
modelo definitivo
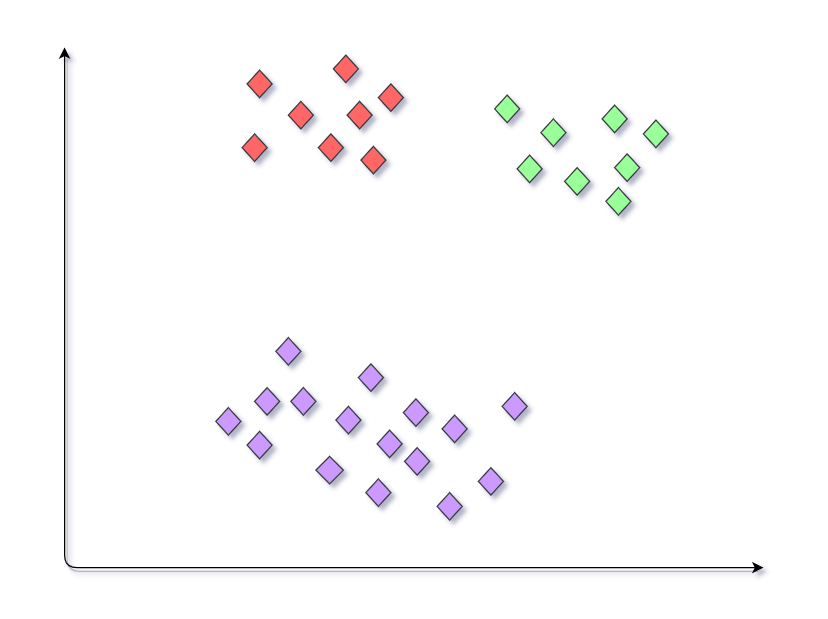
De manera similar, podemos obtener diferentes resultados del modelo en el mismo conjunto de datos. Esta condición en la que se genera un conjunto diferente de clústeres cuando se proporciona un conjunto diferente de centroides al algoritmo K-means, lo que lo hace inconsistente y poco confiable, se denomina trampa de inicialización aleatoria.
Publicación traducida automáticamente
Artículo escrito por KaranGupta5 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA