La mayoría de los algoritmos de aprendizaje automático no pueden funcionar con datos categóricos y deben convertirse en datos numéricos. A veces, en los conjuntos de datos, encontramos columnas que contienen características categóricas (valores de string), por ejemplo, el parámetro Sexo tendrá parámetros categóricos como Hombre , Mujer . Estas etiquetas no tienen un orden de preferencia específico y, dado que los datos son etiquetas de string, los modelos de aprendizaje automático malinterpretaron que hay algún tipo de jerarquía en ellos.

Un enfoque para resolver este problema puede ser la codificación de etiquetas, en la que asignaremos un valor numérico a estas etiquetas, por ejemplo , Male y Female asignados a 0 y 1 . Pero esto puede agregar un sesgo en nuestro modelo, ya que comenzará a dar mayor preferencia al parámetro Femenino como 1>0 e, idealmente, ambas etiquetas son igualmente importantes en el conjunto de datos. Para solucionar este problema, utilizaremos la técnica One Hot Encoding.
Una codificación en caliente:
En esta técnica, los parámetros categóricos prepararán columnas separadas para las etiquetas de Hombre y Mujer. Entonces, donde haya Hombre, el valor será 1 en la columna Hombre y 0 en la columna Mujer, y viceversa. Entendamos con un ejemplo: Consideremos los datos donde se dan las frutas y sus correspondientes valores categóricos y precios.
| Fruta | Valor categórico de la fruta. | Precio |
|---|---|---|
| manzana | 1 | 5 |
| mango | 2 | 10 |
| manzana | 1 | 15 |
| naranja | 3 | 20 |
La salida después de la codificación one-hot de los datos se da de la siguiente manera,
| manzana | mango | naranja | precio |
|---|---|---|---|
| 1 | 0 | 0 | 5 |
| 0 | 1 | 0 | 10 |
| 1 | 0 | 0 | 15 |
| 0 | 0 | 1 | 20 |
Código: implementación de código Python de la técnica de codificación manual One-Hot Carga de datos
Python3
# Program for demonstration of one hot encoding
# import libraries
import numpy as np
import pandas as pd
# import the data required
data = pd.read_csv("employee_data.csv")
print(data.head())
Producción: 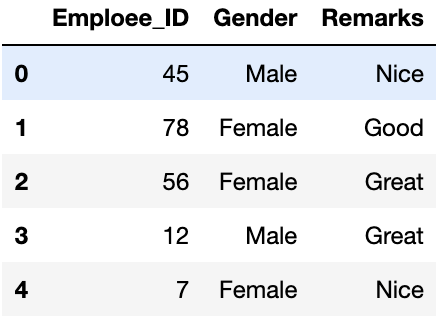
Comprobación de las etiquetas en los parámetros categóricos
Python3
print(data['Gender'].unique()) print(data['Remarks'].unique())
Producción:
array(['Male', 'Female'], dtype=object) array(['Nice', 'Good', 'Great'], dtype=object)
Comprobación de los recuentos de etiquetas en los parámetros categóricos
Python3
data['Gender'].value_counts() data['Remarks'].value_counts()
Producción:
Female 7 Male 5 Name: Gender, dtype: int64 Nice 5 Great 4 Good 3 Name: Remarks, dtype: int64
Codificación One-Hot de los parámetros categóricos usando get_dummies()
Python3
one_hot_encoded_data = pd.get_dummies(data, columns = ['Remarks', 'Gender']) print(one_hot_encoded_data)
Producción: 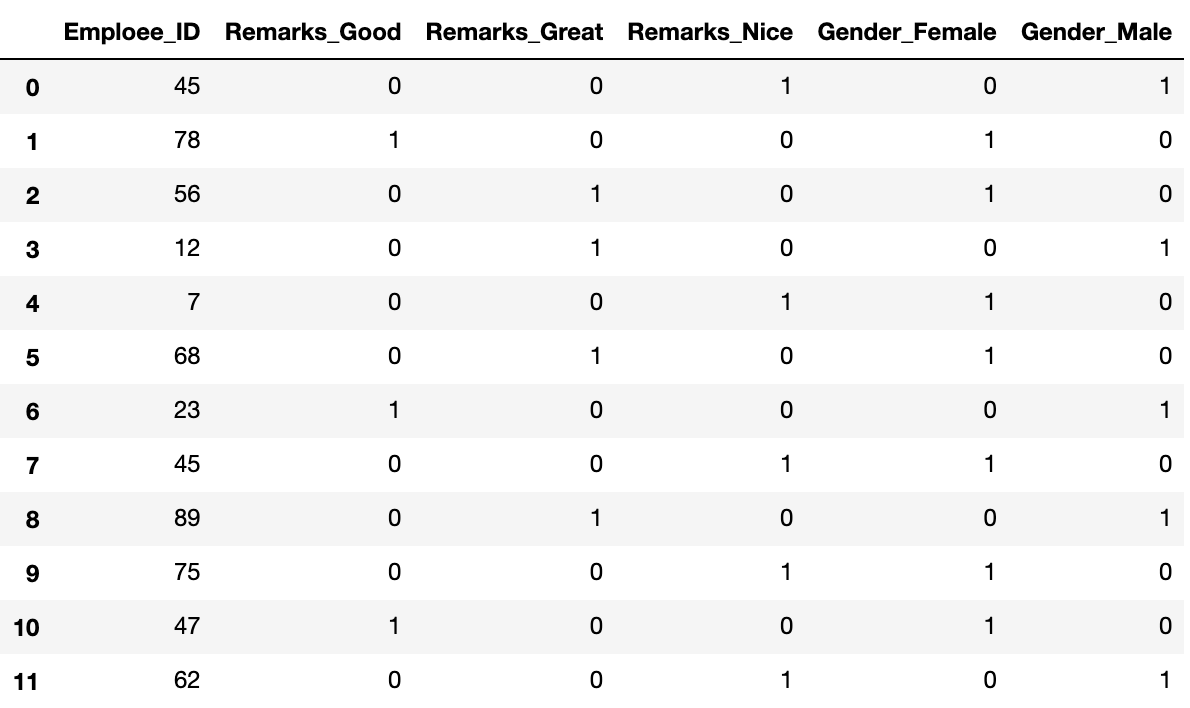
Podemos observar que tenemos 3 comentarios y 2 columnas de género en los datos. Sin embargo, puede usar n-1 columnas para definir parámetros si tiene n etiquetas únicas. Por ejemplo, si solo mantenemos la columna Género_Femenino y soltamos la columna Género_Masculino , entonces también podemos transmitir toda la información como cuando la etiqueta es 1, significa femenino y cuando la etiqueta es 0 significa masculino. De esta forma podemos codificar los datos categóricos y reducir también el número de parámetros.
Una codificación en caliente usando la biblioteca de aprendizaje de Sci-kit:
Un algoritmo de codificación en caliente es un sistema de codificación de la biblioteca de aprendizaje Sci-kit. One Hot Encoding se utiliza para convertir variables categóricas numéricas en vectores binarios. Antes de implementar este algoritmo. Asegúrese de que los valores categóricos deben estar codificados con etiquetas, ya que una codificación activa solo toma valores categóricos numéricos.
Python3
#importing libraries
import pandas as pd
import numpy as np
from sklearn.preprocessing import OneHotEncoder
#Retrieving data
data = pd.read_csv('Employee_data.csv')
# Converting type of columns to category
data['Gender']=data['Gender'].astype('category')
data['Remarks']=data['Remarks'].astype('category')
#Assigning numerical values and storing it in another columns
data['Gen_new']=data['Gender'].cat.codes
data['Rem_new']=data['Remarks'].cat.codes
#Create an instance of One-hot-encoder
enc=OneHotEncoder()
#Passing encoded columns
'''
NOTE: we have converted the enc.fit_transform() method to array because the fit_transform method
of OneHotEncoder returns SpiPy sparse matrix this enables us to save space when we
have huge number of categorical variables
'''
enc_data=pd.DataFrame(enc.fit_transform(data[['Gen_new','Rem_new']]).toarray())
#Merge with main
New_df=data.join(enc_data)
print(New_df)
Producción:
Employee_Id Gender Remarks Gen_new Rem_new 0 1 2 3 4 0 45 Male Nice 1 2 0.0 1.0 0.0 0.0 1.0 1 78 Female Good 0 0 1.0 0.0 1.0 0.0 0.0 2 56 Female Great 0 1 1.0 0.0 0.0 1.0 0.0 3 12 Male Great 1 1 0.0 1.0 0.0 1.0 0.0 4 7 Female Nice 0 2 1.0 0.0 0.0 0.0 1.0 5 68 Female Great 0 1 1.0 0.0 0.0 1.0 0.0 6 23 Male Good 1 0 0.0 1.0 1.0 0.0 0.0 7 45 Female Nice 0 2 1.0 0.0 0.0 0.0 1.0 8 89 Male Great 1 1 0.0 1.0 0.0 1.0 0.0 9 75 Female Nice 0 2 1.0 0.0 0.0 0.0 1.0 10 47 Female Good 0 0 1.0 0.0 1.0 0.0 0.0 11 62 Male Nice 1 2 0.0 1.0 0.0 0.0 1.0
Usando el enfoque get_dummies:
Python3
one_hot_encoded_data = pd.get_dummies(data, columns = ['Gender','Remarks']) print(one_hot_encoded_data)
Employee_Id Gen_new Rem_new Gender_Female Gender_Male Remarks_Good Remarks_Great Remarks_Nice 0 45 1 2 0 1 0 0 1 1 78 0 0 1 0 1 0 0 2 56 0 1 1 0 0 1 0 3 12 1 1 0 1 0 1 0 4 7 0 2 1 0 0 0 1 5 68 0 1 1 0 0 1 0 6 23 1 0 0 1 1 0 0 7 45 0 2 1 0 0 0 1 8 89 1 1 0 1 0 1 0 9 75 0 2 1 0 0 0 1 10 47 0 0 1 0 1 0 0 11 62 1 2 0 1 0 0 1
Publicación traducida automáticamente
Artículo escrito por Lekhana_Ganji y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA