Prerrequisito: probabilidades de registro , regresión logística
NOTA: Se recomienda revisar los temas de requisitos previos para tener una comprensión clara de este artículo.
Las probabilidades logarítmicas juegan un papel importante en la regresión logística, ya que convierte el modelo LR de un modelo basado en probabilidad a un modelo basado en probabilidad. Tanto la probabilidad como las probabilidades logarítmicas tienen su propio conjunto de propiedades; sin embargo, las probabilidades logarítmicas facilitan la interpretación del resultado. Por lo tanto, usar probabilidades logarítmicas es un poco más ventajoso que la probabilidad.
Antes de entrar en los detalles de la regresión logística, comprendamos brevemente qué son las probabilidades.
Probabilidades: En pocas palabras, las probabilidades son las posibilidades de éxito divididas por las posibilidades de fracaso. Se representa en forma de razón. (Como se muestra en la ecuación dada a continuación)

where, p -> success odds 1-p -> failure odds
Regresión logística con probabilidades de registro
Ahora, entremos en las matemáticas detrás de la participación de las probabilidades logarítmicas en la regresión logística. En la regresión logística, la probabilidad de que la variable independiente corresponda a un éxito está dada por:

where, p -> odds of success β0, β1 -> assigned weights x -> independent variable
Entonces, las probabilidades de falla en este caso estarán dadas por:

Por lo tanto, la razón de probabilidades se define como:

Ahora, como se discutió en el artículo de probabilidades de registro, tomamos el registro de la razón de probabilidades para obtener simetría en los resultados. Por lo tanto, tomando log en ambos lados da:

que es la ecuación general de la regresión logística. Ahora, en el modelo logístico, LHS contiene el logaritmo de la razón de probabilidades que proporciona el RHS que involucra una combinación lineal de pesos y variables independientes.
Intuición gráfica
i. Problema con salida basada en probabilidad en regresión logística
Consideremos un ejemplo. Digamos que construimos un modelo de regresión logística para determinar la probabilidad de que una persona padezca diabetes en función de su nivel de azúcar. La trama para esto se vería así: (Ver Fig. 1)
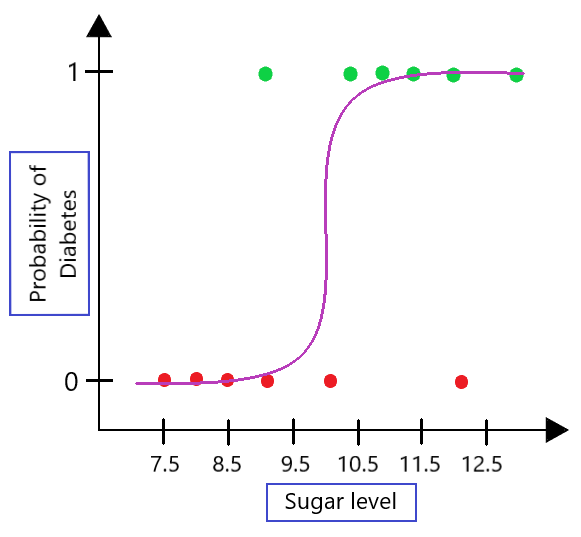
Fig. 1: diagrama del modelo LR
El problema sigue siendo que la salida del modelo es solo binaria según el gráfico anterior. Para abordar este problema, utilizamos el concepto de probabilidades logarítmicas presente en la regresión logística.
ii. Solución: Transformar la salida
Para resolver el problema discutido anteriormente, convertimos la salida basada en probabilidades en una salida basada en probabilidades logarítmicas. (Como se muestra en la ecuación dada a continuación)

Supongamos valores aleatorios de p y veamos cómo se transforma el eje y.
una. Valores límite


Entonces, el dominio del eje y es: (-∞, ∞)
b. Valor medio

Entonces, en p = 0.5 -> log (probabilidades) = y = 0 .
C. A valores aleatorios


Entonces, en p > 0.5 -> obtenemos el valor de log(odds) en el rango (0, ∞)
y en p < 0.5 -> obtenemos el valor de log(odds) en el rango (-∞, 0)
Si mapeamos estos valores en una gráfica transformada, se vería así: (Como se muestra en la Fig. 2)
Fig. 2: gráfico LR transformado
Según el valor de la pendiente (m) y la intersección (c), podemos interpretar fácilmente el modelo y obtener resultados deterministas no binarios. Este es el poder de las probabilidades logarítmicas en la regresión logística.
Las probabilidades de registro, comúnmente conocidas como función Logit, se utilizan en los modelos de regresión logística cuando buscamos una salida no binaria. Así es como la regresión logística puede funcionar tanto como modelo de regresión como de clasificación. Para cualquier duda/consulta, comenta abajo.
Publicación traducida automáticamente
Artículo escrito por prakharr0y y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA