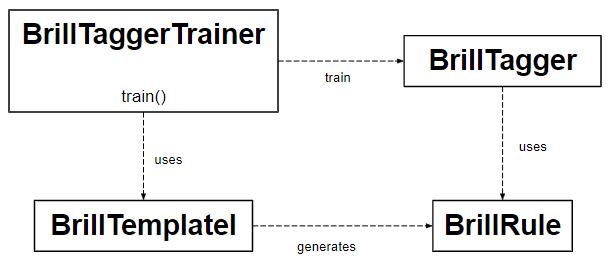
- La clase BrillTagger es un etiquetador basado en transformación . No es una subclase de SequentialBackoffTagger.
- Además, utiliza una serie de reglas para corregir los resultados de un etiquetador inicial.
- Estas reglas que sigue se basan en la puntuación. Esta puntuación es igual a la no. de errores que corrigen menos el no. de los nuevos errores que producen.
Código #1: Entrenamiento de una clase BrillTagger
# Loading Libraries from nltk.tag import brill, brill_trainer def train_brill_tagger(initial_tagger, train_sents, **kwargs): templates = [ brill.Template(brill.Pos([-1])), brill.Template(brill.Pos([1])), brill.Template(brill.Pos([-2])), brill.Template(brill.Pos([2])), brill.Template(brill.Pos([-2, -1])), brill.Template(brill.Pos([1, 2])), brill.Template(brill.Pos([-3, -2, -1])), brill.Template(brill.Pos([1, 2, 3])), brill.Template(brill.Pos([-1]), brill.Pos([1])), brill.Template(brill.Word([-1])), brill.Template(brill.Word([1])), brill.Template(brill.Word([-2])), brill.Template(brill.Word([2])), brill.Template(brill.Word([-2, -1])), brill.Template(brill.Word([1, 2])), brill.Template(brill.Word([-3, -2, -1])), brill.Template(brill.Word([1, 2, 3])), brill.Template(brill.Word([-1]), brill.Word([1])), ] # Using BrillTaggerTrainer to train trainer = brill_trainer.BrillTaggerTrainer( initial_tagger, templates, deterministic = True) return trainer.train(train_sents, **kwargs)
Código #2: Usemos el BrillTagger entrenado
from nltk.tag import brill, brill_trainer
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
from tag_util import train_brill_tagger
# Initializing
default_tag = DefaultTagger('NN')
# initializing training and testing set
train_data = treebank.tagged_sents()[:3000]
test_data = treebank.tagged_sents()[3000:]
initial_tag = backoff_tagger(
train_data, [UnigramTagger, BigramTagger,
TrigramTagger], backoff = default_tagger)
a = initial_tag.evaluate(test_data)
print ("Accuracy of Initial Tag : ", a)
Producción :
Accuracy of Initial Tag : 0.8806820634578028
Código #3:
brill_tag = train_brill_tagger(initial_tag, train_data)
b = brill_tag.evaluate(test_data)
print ("Accuracy of brill_tag : ", b)
Producción :
Accuracy of brill_tag : 0.8827541549751781
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA