Las colocaciones son dos o más palabras que tienden a aparecer juntas con frecuencia, por ejemplo, Estados Unidos . Hay muchas otras palabras que pueden venir después de United, como United Kingdom y United Airlines. Como ocurre con muchos aspectos del procesamiento del lenguaje natural, el contexto es muy importante. Y para las colocaciones, el contexto lo es todo.
En el caso de colocaciones, el contexto será un documento en forma de lista de palabras. Descubrir colocaciones en esta lista de palabras significa encontrar frases comunes que ocurren con frecuencia a lo largo del texto.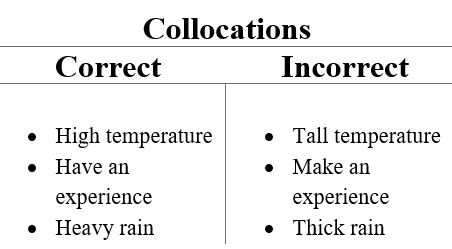
Enlace a DATA – Monty Python y el guión del Santo Grial
Código #1: Cargando Bibliotecas
from nltk.corpus import webtext # use to find bigrams, which are pairs of words from nltk.collocations import BigramCollocationFinder from nltk.metrics import BigramAssocMeasures
Código #2: Busquemos las colocaciones
# Loading the data words = [w.lower() for w in webtext.words( 'C:\\Geeksforgeeks\\python_and_grail.txt')] biagram_collocation = BigramCollocationFinder.from_words(words) biagram_collocation.nbest(BigramAssocMeasures.likelihood_ratio, 15)
Producción :
[("'", 's'),
('arthur', ':'),
('#', '1'),
("'", 't'),
('villager', '#'),
('#', '2'),
(']', '['),
('1', ':'),
('oh', ', '),
('black', 'knight'),
('ha', 'ha'),
(':', 'oh'),
("'", 're'),
('galahad', ':'),
('well', ', ')]
Como podemos ver en el código anterior, encontrar colocaciones de esta manera no es muy útil. Por lo tanto, el código a continuación es una versión refinada al agregar un filtro de palabras para eliminar la puntuación y las palabras vacías.
Código #3:
from nltk.corpus import stopwords
stopset = set(stopwords.words('english'))
filter_stops = lambda w: len(w) < 3 or w in stopset
biagram_collocation.apply_word_filter(filter_stops)
biagram_collocation.nbest(BigramAssocMeasures.likelihood_ratio, 15)
Producción :
[('black', 'knight'),
('clop', 'clop'),
('head', 'knight'),
('mumble', 'mumble'),
('squeak', 'squeak'),
('saw', 'saw'),
('holy', 'grail'),
('run', 'away'),
('french', 'guard'),
('cartoon', 'character'),
('iesu', 'domine'),
('pie', 'iesu'),
('round', 'table'),
('sir', 'robin'),
('clap', 'clap')]
¿Cómo funciona en el código?
- BigramCollocationFinder construye dos distribuciones de frecuencia:
- uno para cada palabra
- otra para bigramas.
- Una distribución de frecuencia es básicamente un diccionario de Python mejorado donde las claves son lo que se cuenta y los valores son los conteos.
- Cualquier función de filtrado reduce el tamaño al eliminar cualquier palabra que no pase el filtro
- El uso de una función de filtrado para eliminar todas las palabras que tienen uno o dos caracteres, y todas las palabras vacías en inglés, da como resultado un resultado mucho más limpio.
- Después de filtrar, el buscador de colocaciones está listo para buscar colocaciones.
Código #4: Trabajar en trillizos en lugar de parejas.
# Loading Libraries from nltk.collocations import TrigramCollocationFinder from nltk.metrics import TrigramAssocMeasures # Loading data - text file words = [w.lower() for w in webtext.words( 'C:\Geeksforgeeks\\python_and_grail.txt')] trigram_collocation = TrigramCollocationFinder.from_words(words) trigram_collocation.apply_word_filter(filter_stops) trigram_collocation.apply_freq_filter(3) trigram_collocation.nbest(TrigramAssocMeasures.likelihood_ratio, 15)
Producción :
[('clop', 'clop', 'clop'),
('mumble', 'mumble', 'mumble'),
('squeak', 'squeak', 'squeak'),
('saw', 'saw', 'saw'),
('pie', 'iesu', 'domine'),
('clap', 'clap', 'clap'),
('dona', 'eis', 'requiem'),
('brave', 'sir', 'robin'),
('heh', 'heh', 'heh'),
('king', 'arthur', 'music'),
('hee', 'hee', 'hee'),
('holy', 'hand', 'grenade'),
('boom', 'boom', 'boom'),
('...', 'dona', 'eis'),
('already', 'got', 'one')]
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA