¿Qué son los trozos?
Los fragmentos se componen de palabras y los tipos de palabras se definen utilizando las etiquetas de parte del discurso. Incluso se puede definir un patrón o palabras que no pueden ser parte de chuck y esas palabras se conocen como grietas.
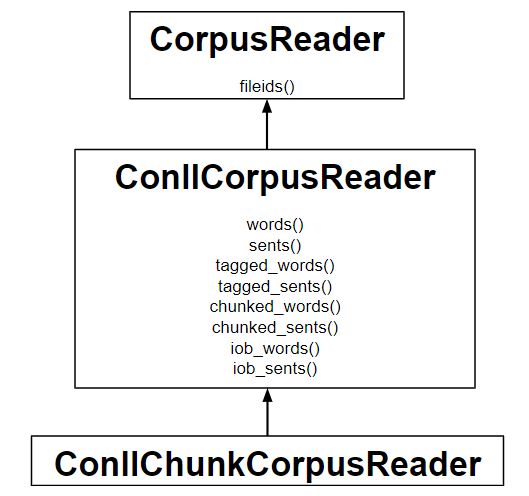
¿Qué son las etiquetas IOB?
Es un formato para trozos. Estas etiquetas son similares a las etiquetas de parte del discurso, pero pueden indicar el interior, el exterior y el comienzo de un fragmento. Aquí no solo se permiten frases nominales, sino múltiples tipos diferentes de frases sueltas.
Ejemplo: Es un extracto del corpus conll2000 . Cada palabra tiene una etiqueta de parte del discurso seguida de una etiqueta IOB en su propia línea:
Mr. NNP B-NP Meador NNP I-NP had VBD B-VP been VBN I-VP executive JJ B-NP vice NN I-NP president NN I-NP of IN B-PP Balcor NNP B-NP
¿Qué significa?
B-NP: el comienzo de una frase nominal
I-NP: describe que la palabra está dentro de la frase nominal actual.
O: final de la oración.
B-VP y I-VP: principio y dentro de una frase verbal.
Código n.º 1: cómo funciona: fragmentación de palabras con etiquetas IOB.
Python3
# Loading the libraries
from nltk.corpus.reader import ConllChunkCorpusReader
# Initializing
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_words()
reader.iob_words()
Producción :
[Tree('NP', [('Mr.', 'NNP'), ('Meador', 'NNP')]), Tree('VP', [('had', 'VBD'),
('been', 'VBN')]), ...]
[('Mr.', 'NNP', 'B-NP'), ('Meador', 'NNP', 'I-NP'), ...]
Código n.º 2: cómo funciona: fragmentación de oraciones con etiquetas IOB.
Python3
# Loading the libraries
from nltk.corpus.reader import ConllChunkCorpusReader
# Initializing
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_sents()
reader.iob_sents()
Producción :
[Tree('S', [Tree('NP', [('Mr.', 'NNP'), ('Meador', 'NNP')]),
Tree('VP', [('had', 'VBD'), ('been', 'VBN')]),
Tree('NP', [('executive', 'JJ'), ('vice', 'NN'), ('president', 'NN')]),
Tree('PP', [('of', 'IN')]), Tree('NP', [('Balcor', 'NNP')]), ('.', '.')])]
[[('Mr.', 'NNP', 'B-NP'), ('Meador', 'NNP', 'I-NP'), ('had', 'VBD', 'B-VP'),
('been', 'VBN', 'I-VP'), ('executive', 'JJ', 'B-NP'), ('vice', 'NN', 'I-NP'),
('president', 'NN', 'I-NP'), ('of', 'IN', 'B-PP'), ('Balcor', 'NNP', 'B-NP'),
('.', '.', 'O')]]
Entendamos el código anterior:
- Para la lectura del corpus con formato IOB se utiliza la clase ConllChunkCorpusReader.
- No hay separación de párrafos y cada oración está separada por una línea en blanco, por lo tanto, los métodos para_* no están disponibles.
- La tupla o lista que especifica los tipos de fragmentos en el archivo como (‘NP’, ‘VP’, ‘PP’) sirve como tercer argumento para ConllChunkCorpusReader.
- Los métodos iob_words() e iob_sents() devuelven listas de tres tuplas de (word, pos, iob)
Código #3: Hojas de árbol, es decir, las fichas etiquetadas
Python3
# Loading the libraries
from nltk.corpus.reader import ConllChunkCorpusReader
# Initializing
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_words()[0].leaves()
reader.chunked_sents()[0].leaves()
reader.chunked_paras()[0][0].leaves()
Producción :
[('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS')]
[('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS'),
('have', 'VBP'), ('trimmed', 'VBN'), ('about', 'IN'), ('300', 'CD'),
('jobs', 'NNS'), (', ', ', '), ('the', 'DT'), ('spokesman', 'NN'),
('said', 'VBD'), ('.', '.')]
[('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS'),
('have', 'VBP'), ('trimmed', 'VBN'), ('about', 'IN'), ('300', 'CD'),
('jobs', 'NNS'), (', ', ', '), ('the', 'DT'), ('spokesman', 'NN'),
('said', 'VBD'), ('.', '.')]
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA