¿Qué es el etiquetado de parte del discurso (POS)?
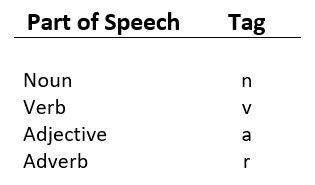
Es un proceso de convertir una oración en formas: lista de palabras, lista de tuplas (donde cada tupla tiene una forma (palabra, etiqueta)). La etiqueta en caso de es una etiqueta de parte del discurso e indica si la palabra es un sustantivo, un adjetivo, un verbo, etc.
Ejemplo de corpus etiquetado como parte del discurso (POS)
The/at-tl expense/nn and/cc time/nn involved/vbn are/ber astronomical/jj ./.
El formato de un corpus etiquetado tiene la forma palabra/etiqueta . Cada palabra tiene una etiqueta que indica su POS. Por ejemplo, nn se refiere a un sustantivo, vb es un verbo.
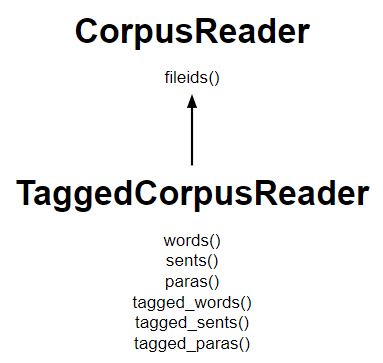
Código #1: Creando un TaggedCorpusReader. para palabras
Python3
# Using TaggedCorpusReader
from nltk.corpus.reader import TaggedCorpusReader
# initializing
x = TaggedCorpusReader('.', r'.*\.pos')
words = x.words()
print ("Words : \n", words)
tag_words = x.tagged_words()
print ("\ntag_words : \n", tag_words)
Producción :
Words :
['The', 'expense', 'and', 'time', 'involved', 'are', ...]
tag_words :
[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ...]
Código #2: Para oración
Python3
tagged_sent = x.tagged_sents()
print ("tagged_sent : \n", tagged_sent)
Producción :
tagged_sent :
[[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ('time', 'NN'),
('involved', 'VBN'), ('are', 'BER'), ('astronomical', 'JJ'), ('.', '.')]]
Código #3: Para párrafos
Python3
para = x.para()
print ("para : \n", para)
tagged_para = x.tagged_paras()
print ("\ntagged_paras : \n", tagged_paras)
Producción :
para:
[[['The', 'expense', 'and', 'time', 'involved', 'are', 'astronomical', '.']]]
tagged_paras :
[[[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ('time', 'NN'),
('involved', 'VBN'), ('are', 'BER'), ('astronomical', 'JJ'), ('.', '.')]]]
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA