Vamos a implementar un proyecto de extremo a extremo utilizando máquinas de vectores de soporte para operar en vivo para nosotros. Probablemente debe haber oído hablar del término mercado de valores que se sabe que hizo la vida de miles y destruyó la vida de millones. Si no está familiarizado con el mercado de valores, puede navegar por algunas cosas básicas sobre los mercados.
Herramientas y tecnologías utilizadas:
- Python
- Clasificador de vectores de soporte Sklearn
- Yahoo Finanzas
- Cuaderno Jupyter
- Cambio azúl
Implementación paso a paso
Paso 1: Importar las bibliotecas
Python3
# Machine learning
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# For data manipulation
import pandas as pd
import numpy as np
# To plot
import matplotlib.pyplot as plt
plt.style.use('seaborn-darkgrid')
# To ignore warnings
import warnings
warnings.filterwarnings("ignore")
Paso 2: Leer datos de existencias
Leeremos los datos de acciones descargados del sitio web de Yahoo Finance. Los datos se almacenan en formato OHLC (Open, High, Low, Close) en un archivo CSV. Para leer un archivo CSV, puede usar el método read_csv() de pandas.
Sintaxis:
pd.read_csv(filename, index_col)
Nota: Hemos descargado los datos del último año de Reliance Industries Trading In NSE del sitio web de Yahoo Finance.
Archivo utilizado:
Python3
# Read the csv file using read_csv
# method of pandas
df = pd.read_csv('RELIANCE.csv')
df
Producción:
Paso 3: Preparación de datos
Los datos debían procesarse antes de su uso, de modo que la columna de fecha debería actuar como un índice para hacerlo.
Python3
# Changes The Date column as index columns df.index = pd.to_datetime(df['Date']) df # drop The original date column df = df.drop(['Date'], axis='columns') df
Producción:
Paso 4: Definir las variables explicativas
Las variables explicativas o independientes se utilizan para predecir la variable de respuesta de valor. La X es un conjunto de datos que contiene las variables que se utilizan para la predicción. La X consta de variables como ‘Abrir – Cerrar’ y ‘Alto – Bajo’. Estos pueden entenderse como indicadores basados en los cuales el algoritmo predecirá la tendencia de mañana. Siéntase libre de agregar más indicadores y ver el rendimiento
Python3
# Create predictor variables df['Open-Close'] = df.Open - df.Close df['High-Low'] = df.High - df.Low # Store all predictor variables in a variable X X = df[['Open-Close', 'High-Low']] X.head()
Producción:
Paso 5: Definir la variable objetivo
La variable objetivo es el resultado que el modelo de aprendizaje automático predecirá en función de las variables explicativas. y es un conjunto de datos de destino que almacena la señal comercial correcta que el algoritmo de aprendizaje automático intentará predecir. Si el precio de mañana es mayor que el precio de hoy, compraremos la acción en particular, de lo contrario no tendremos ninguna posición en la. Guardaremos +1 para una señal de compra y 0 para una posición nula en y. Usaremos la función where() de NumPy para hacer esto.
Sintaxis:
np.where(condition,value_if_true,value_if_false)
Python3
# Target variables y = np.where(df['Close'].shift(-1) > df['Close'], 1, 0) y
Producción:

Paso 6: dividir los datos en entrenar y probar
Dividiremos los datos en conjuntos de datos de entrenamiento y de prueba. Esto se hace para que podamos evaluar la eficacia del modelo en el conjunto de datos de prueba.
Python3
split_percentage = 0.8 split = int(split_percentage*len(df)) # Train data set X_train = X[:split] y_train = y[:split] # Test data set X_test = X[split:] y_test = y[split:]
Paso 7: Clasificador de vectores de soporte (SVC)
Usaremos la función SVC() de la biblioteca sklearn.svm.SVC para crear nuestro modelo clasificador usando el método fit() en el conjunto de datos de entrenamiento.
Python3
# Support vector classifier cls = SVC().fit(X_train, y_train)
Paso 8: Precisión del clasificador
Calcularemos la precisión del algoritmo en el tren y probaremos el conjunto de datos comparando los valores reales de la señal con los valores previstos de la señal. La función precision_score() se utilizará para calcular la precisión.

Una precisión de más del 50% en los datos de prueba sugiere que el modelo clasificador es efectivo.
Paso 9: Implementación de la estrategia
Predeciremos la señal (compra o venta) usando la función cls.predict().
Python3
df['Predicted_Signal'] = cls.predict(X)
Calcular devoluciones diarias
Python3
# Calculate daily returns df['Return'] = df.Close.pct_change()
Calcular la rentabilidad de la estrategia
Python3
# Calculate strategy returns df['Strategy_Return'] = df.Return *df.Predicted_Signal.shift(1)
Calcular rendimientos acumulativos
Python3
# Calculate Cumulutive returns df['Cum_Ret'] = df['Return'].cumsum() df
Calcular la rentabilidad acumulada de la estrategia
Python3
# Plot Strategy Cumulative returns df['Cum_Strategy'] = df['Strategy_Return'].cumsum() df
Devoluciones de la estrategia de trama frente a las devoluciones originales
Python3
import matplotlib.pyplot as plt %matplotlib inline plt.plot(Df['Cum_Ret'],color='red') plt.plot(Df['Cum_Strategy'],color='blue')
Producción:
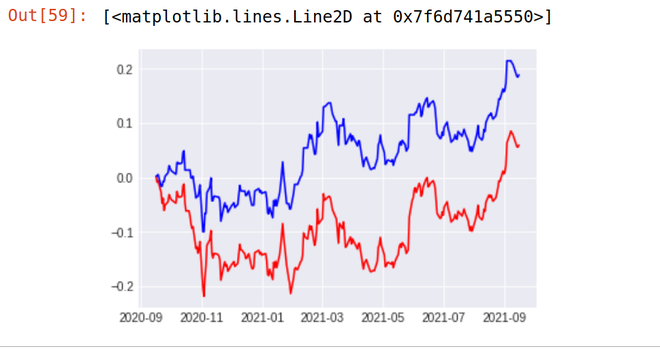
Como puede ver, nuestra estrategia parece estar superando totalmente el rendimiento de las acciones de Reliance. Nuestra estrategia (línea azul) proporcionó un rendimiento del 18,87 % en el último año, mientras que las acciones de Reliance Industries (línea roja) proporcionan un rendimiento de solo el 5,97 % en el último año.
Resultado de la prueba retrospectiva
1. TCS
Stock Return Over Last 1 year - 48% Strategy result - 48.9 %
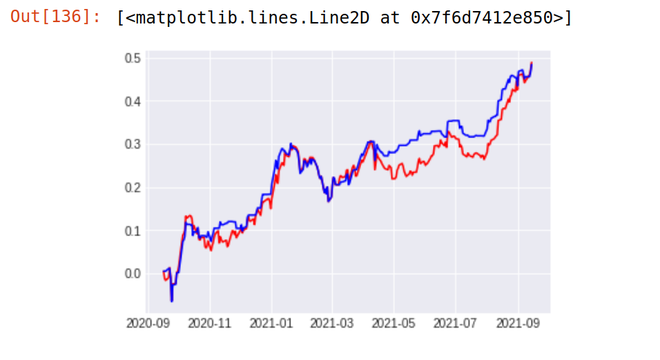
2. BANCO ICICI
Stock Return Over Last 1 year - 48% Strategy result - 48.9 %
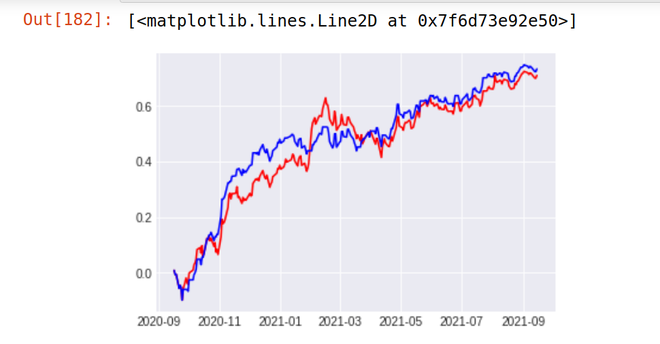
Implementación de la estrategia en el mercado en vivo
La estrategia codificada se puede implementar fácilmente en el mercado en vivo y también se puede realizar una prueba retrospectiva en cualquier cantidad de datos a lo largo de los intercambios. La implementación se puede realizar fácilmente con la plataforma BlueShift. Es una plataforma interactiva con alimentación de datos en vivo y conexiones a través de varios corredores. Puede realizar pruebas retroactivas en la plataforma BlueShift durante cualquier cantidad de tiempo con datos de varios intercambios.
Conclusión
- El proveedor de estrategia que promete rendimientos durante el mercado en vivo. Actualmente, acabo de entrenar el modelo en función de los niveles del día anterior; sin embargo, para aumentar la precisión del modelo, también agregamos varios indicadores técnicos para entrenar el modelo, como RSI, ADX, ATR, MACD, estocástico y muchos más.
- Para obtener más precisión en el mercado en vivo El aprendizaje profundo demostró ser muy efectivo en el comercio en un mercado en vivo. Podemos automatizar nuestras operaciones mediante el aprendizaje por refuerzo y también mediante el LSTM apilado, que proporciona un aumento exponencial de los rendimientos de nuestra estrategia.
Nota: el dinero real no debe implementarse hasta que se complete la prueba retrospectiva de la estrategia y sin retornos prometedores por parte de la estrategia durante el comercio de papel
Publicación traducida automáticamente
Artículo escrito por nirvikarnayan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA