Desde los albores de la IPL en 2008, ha atraído a espectadores de todo el mundo. Un alto nivel de incertidumbre y morderse las uñas en el último momento ha instado a los fanáticos a ver los partidos. En poco tiempo, la IPL se ha convertido en la liga de cricket que más ingresos genera. En un partido de cricket, a menudo vemos que el marcador muestra la probabilidad de que el equipo gane en función de la situación actual del partido. Esta predicción generalmente se realiza con la ayuda de Data Analytics. Antes, cuando no había avances en el aprendizaje automático, la predicción generalmente se basaba en intuiciones o en algunos algoritmos básicos. La imagen de arriba le dice claramente qué tan malo es tomar la tasa de carrera como un factor único para predecir el puntaje final en un partido de cricket de overs limitados.

Siendo un fanático del cricket, visualizar las estadísticas del cricket es fascinante. Revisamos varios blogs y descubrimos patrones que podrían usarse para predecir el puntaje de las coincidencias de IPL de antemano.
¿Por qué aprendizaje profundo?
Los humanos no podemos identificar fácilmente patrones a partir de grandes cantidades de datos y, por lo tanto, aquí entran en juego el aprendizaje automático y el aprendizaje profundo. Aprende cómo los jugadores y los equipos se han desempeñado previamente contra el equipo contrario y entrena al modelo en consecuencia. Usar solo un algoritmo de aprendizaje automático brinda una precisión moderada, por lo tanto, usamos aprendizaje profundo que brinda un rendimiento mucho mejor que nuestro modelo anterior y considera los atributos que pueden brindar resultados precisos.
Herramientas utilizadas:
- Jupyter Notebook / Google colab
- Estudio visual
Tecnología utilizada:
- Aprendizaje automático.
- Aprendizaje profundo
- Frasco (integración de front-end).
- Bueno, para que el proyecto funcione sin problemas, hemos usado algunas bibliotecas como NumPy, Pandas, Scikit-learn, TensorFlow y Matplotlib.
La arquitectura del modelo.
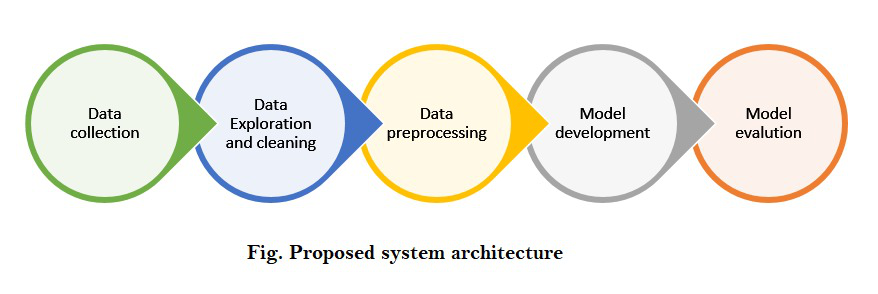
Implementación paso a paso:
Primero, importemos todas las bibliotecas necesarias:
Python3
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn import preprocessing
Paso 1: ¡Comprender el conjunto de datos!
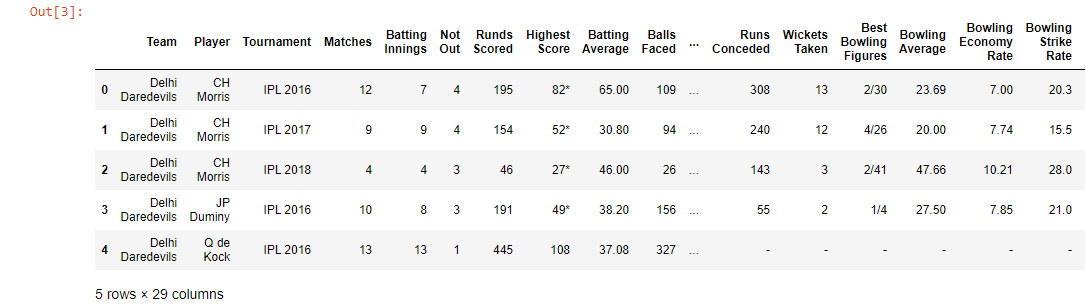
Cuando se trata de datos de cricket, Cricsheet se considera una plataforma adecuada para recopilar datos y, por lo tanto, tomamos los datos de https://cricsheet.org/downloads/ipl.zip . Contiene datos del año 2007 al 2021. Para una mejor precisión de nuestro modelo, usamos las estadísticas de los jugadores de IPL para analizar su rendimiento desde aquí . Este conjunto de datos contiene detalles de cada jugador de IPL desde el año 2016 hasta 2019.
Paso 2: limpieza y formateo de datos
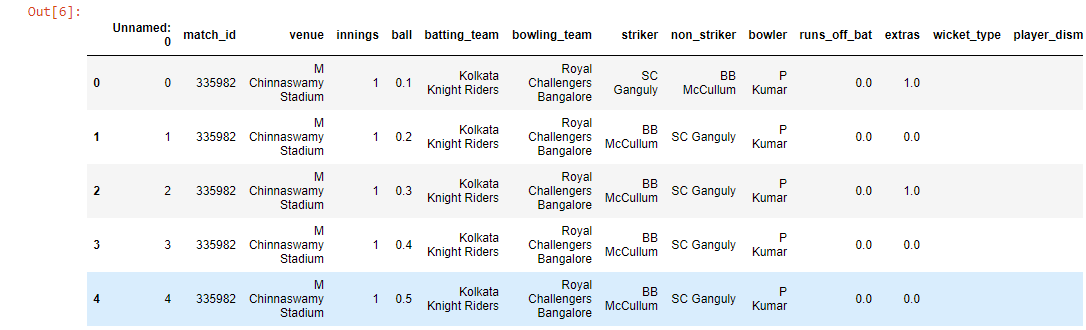
Importamos ambos conjuntos de datos usando el método .read_csv() en un marco de datos usando pandas y mostramos las primeras 5 filas de cada conjunto de datos. Hicimos algunos cambios en nuestro conjunto de datos, como agregar una nueva columna llamada «y» que tenía las carreras anotadas en los primeros 6 overs de esa entrada en particular.
Python3
ipl = pd.read_csv('ipl_dataset.csv')
ipl.head()
Python3
data = pd.read_csv('IPL Player Stats - 2016 till 2019.csv')
data.head()
Ahora, fusionaremos ambos conjuntos de datos.
Python3
ipl= ipl.drop(['Unnamed: 0','extras','match_id', 'runs_off_bat'],axis = 1) new_ipl = pd.merge(ipl,data,left_on='striker',right_on='Player',how='left') new_ipl.drop(['wicket_type', 'player_dismissed'],axis=1,inplace=True) new_ipl.columns
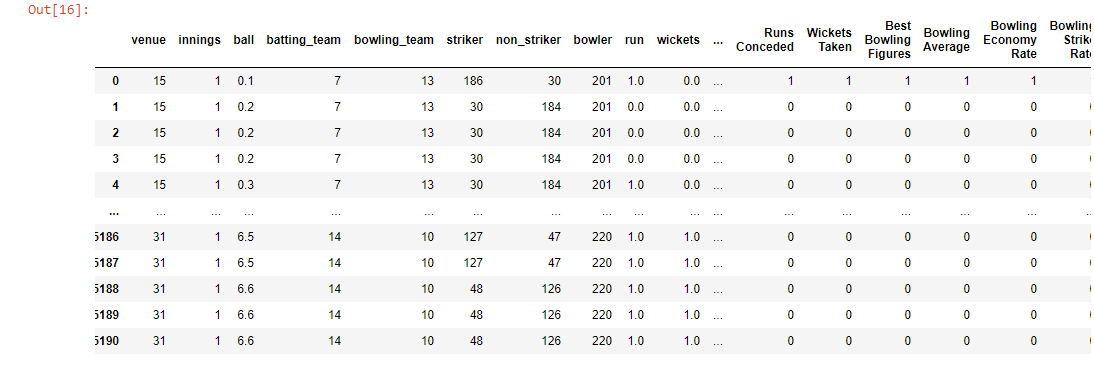
Después de fusionar las columnas y eliminar nuevas columnas no deseadas, nos quedan las siguientes columnas. Aquí está el conjunto de datos modificado .

Hay varias formas de completar valores nulos en nuestro conjunto de datos. Aquí simplemente estoy reemplazando los valores categóricos que son nan con ‘.’
Python3
str_cols = new_ipl.columns[new_ipl.dtypes==object]
new_ipl[str_cols] = new_ipl[str_cols].fillna('.')
Paso 3: Codificación de los datos categóricos a valores numéricos.
Para que las columnas puedan ayudar al modelo en la predicción, los valores deben tener algún sentido para las computadoras. Dado que (todavía) no tienen la capacidad de comprender y sacar inferencias del texto, necesitamos codificar las strings en valores categóricos numéricos. Si bien podemos elegir hacer el proceso manualmente, la biblioteca Scikit-learn nos brinda la opción de usar LabelEncoder.
Python3
listf = [] for c in new_ipl.columns: if new_ipl.dtype==object: print(c,"->" ,new_ipl.dtype) listf.append(c)

Python3
a1 = new_ipl['venue'].unique()
a2 = new_ipl['batting_team'].unique()
a3 = new_ipl['bowling_team'].unique()
a4 = new_ipl['striker'].unique()
a5 = new_ipl['bowler'].unique()
def labelEncoding(data):
dataset = pd.DataFrame(new_ipl)
feature_dict ={}
for feature in dataset:
if dataset[feature].dtype==object:
le = preprocessing.LabelEncoder()
fs = dataset[feature].unique()
le.fit(fs)
dataset[feature] = le.transform(dataset[feature])
feature_dict[feature] = le
return dataset
labelEncoding(new_ipl)
Python3
ip_dataset = new_ipl[['venue','innings', 'batting_team',
'bowling_team', 'striker', 'non_striker',
'bowler']]
b1 = ip_dataset['venue'].unique()
b2 = ip_dataset['batting_team'].unique()
b3 = ip_dataset['bowling_team'].unique()
b4 = ip_dataset['striker'].unique()
b5 = ip_dataset['bowler'].unique()
new_ipl.fillna(0,inplace=True)
features={}
for i in range(len(a1)):
features[a1[i]]=b1[i]
for i in range(len(a2)):
features[a2[i]]=b2[i]
for i in range(len(a3)):
features[a3[i]]=b3[i]
for i in range(len(a4)):
features[a4[i]]=b4[i]
for i in range(len(a5)):
features[a5[i]]=b5[i]
features
Paso 4: Ingeniería y selección de características
Nuestro conjunto de datos contiene varias columnas, pero no podemos tomar tantas entradas de los usuarios, por lo que hemos tomado la cantidad seleccionada de funciones como entrada y las dividimos en X e Y. Luego dividiremos nuestros datos en conjuntos de trenes y conjuntos de prueba antes de usar un algoritmo de aprendizaje automático.
Python3
X = new_ipl[['venue', 'innings','batting_team', 'bowling_team', 'striker','bowler']].values y = new_ipl['y'].values from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.33, random_state=42)
Comparar estos grandes valores numéricos con nuestro modelo será difícil, por lo que siempre es una mejor opción escalar los datos antes de procesarlos. Aquí estamos usando MinMaxScaler de sklearn.preprocessing, que se recomienda cuando se trata de aprendizaje profundo.
Python3
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test)
Nota: No podemos ajustar X_test ya que son los datos que se van a predecir.
Paso 5: Construcción, entrenamiento y prueba del modelo
Aquí viene la parte más emocionante de nuestro proyecto, ¡Construir nuestro modelo! En primer lugar, importaremos Sequential desde tensorflow.keras.models . Además, importaremos Dense & Dropout desde tensorflow.keras.layers , ya que usaremos varias capas.
Python3
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense,Dropout from tensorflow.keras.callbacks import EarlyStopping
EarlyStopping se utiliza para evitar el sobreajuste. Lo que hace básicamente la detención anticipada es que deja de calcular las pérdidas cuando ‘val_loss’ aumenta más que ‘loss’. La curva Val_loss siempre debe estar por debajo de la curva val. Cuando se encuentra que la diferencia entre ‘val_loss’ y ‘loss’ se vuelve constante, se detiene el entrenamiento.
Python3
model = Sequential() model.add(Dense(43, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(22, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(11, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(1)) model.compile(optimizer='adam', loss='mse')
Aquí, creamos 2 capas ocultas y redujimos la cantidad de neuronas, ya que queremos que el resultado final sea 1. Luego, al compilar nuestro modelo, usamos el optimizador Adam y la pérdida como error cuadrático medio. Ahora, comencemos a entrenar nuestro modelo con epochs=400.
Python3
model.fit(x=X_train, y=y_train, epochs=400, validation_data=(X_test,y_test), callbacks=[early_stop] )
Tomará algún tiempo debido a la gran cantidad de muestras y épocas y generará la ‘pérdida’ y la ‘pérdida de valor’ de cada muestra como se muestra a continuación.
Después de completar el entrenamiento, visualicemos las pérdidas de nuestro modelo.
Python3
model_losses = pd.DataFrame(model.history.history) model_losses.plot()
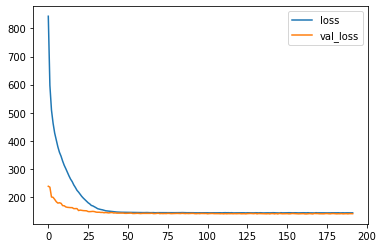
¡Como podemos ver, nuestro modelo está teniendo un comportamiento absolutamente perfecto!
Paso 6: ¡Predicciones!
Aquí llegamos a la parte final de nuestro proyecto donde estaremos prediciendo nuestro X_test. Luego, crearemos un marco de datos que nos muestre los valores reales y los valores predichos.
Python3
predictions = model.predict(X_test) sample = pd.DataFrame(predictions,columns=['Predict']) sample['Actual']=y_test sample.head(10)
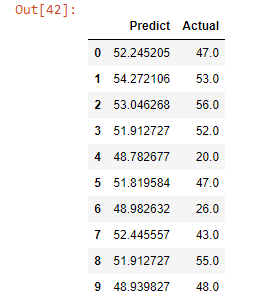
Como podemos ver, nuestro modelo predice bastante bien. Nos está dando puntuaciones casi similares. Para averiguar con mayor precisión la diferencia entre las puntuaciones reales y las predichas, las métricas de rendimiento nos mostrarán la tasa de error usando mean_absolute_error y mean_squared_error de sklearn.metrics
Echa un vistazo a nuestro front-end:
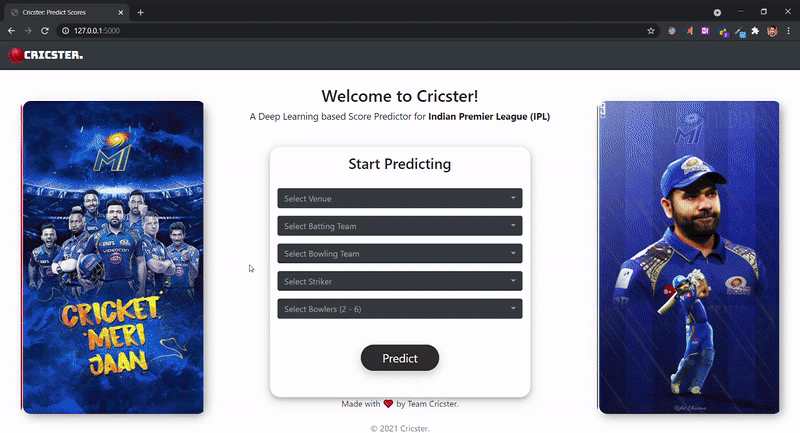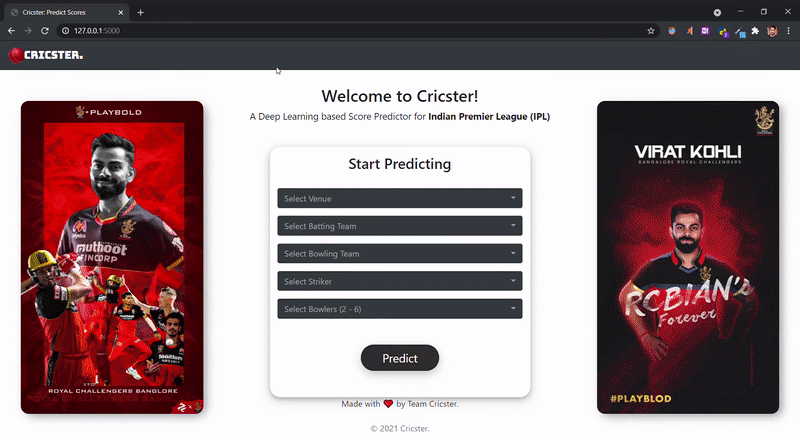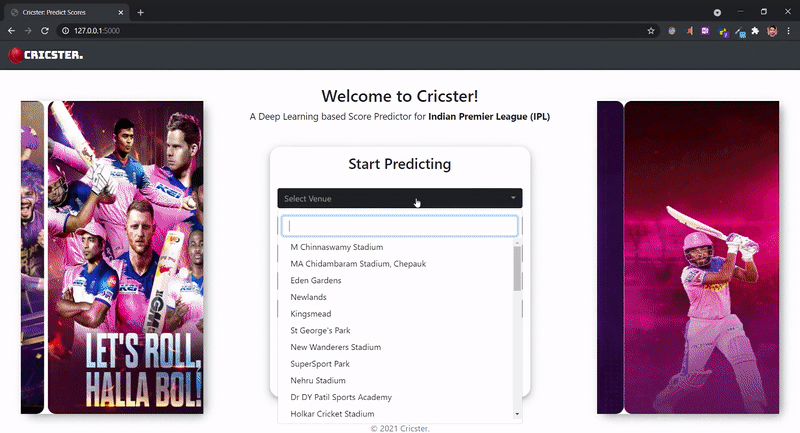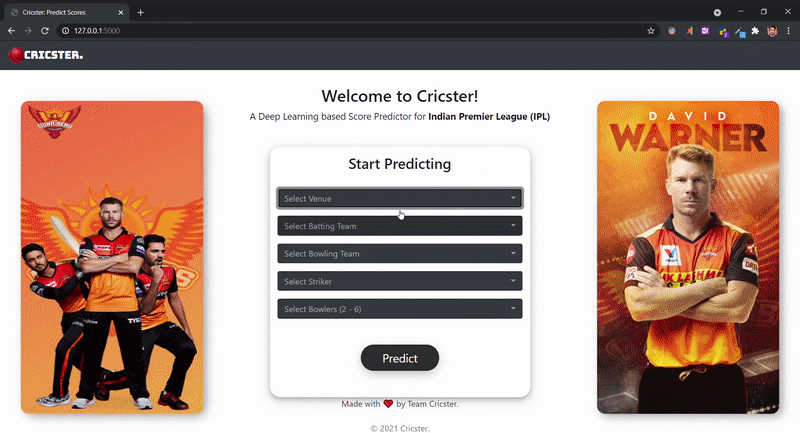
cricster.com
¡Métricas de rendimiento!
Python3
from sklearn.metrics import mean_absolute_error,mean_squared_error mean_absolute_error(y_test,predictions)
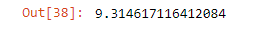
Python3
np.sqrt(mean_squared_error(y_test,predictions))
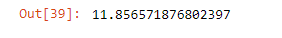
¡Echemos un vistazo a nuestro modelo! 🙂
Miembro del equipo:
- Shravani Rajgurú
- Col rizada de Hrushabh
- Pruthviraj Jadhav
Enlace Github: https://github.com/hrush25/IPL_score_prediction.git
Publicación traducida automáticamente
Artículo escrito por shravanirajguru y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA