En este artículo, aprenderemos a predecir las posibilidades de supervivencia de los pasajeros del Titanic utilizando la información proporcionada sobre su sexo, edad, etc. Como se trata de una tarea de clasificación, utilizaremos bosques aleatorios.
Habrá tres pasos principales en este experimento:
- Ingeniería de funciones
- imputación
- Entrenamiento y Predicción
conjunto de datos
El conjunto de datos para este experimento está disponible gratuitamente en el sitio web de Kaggle. Descargue el conjunto de datos desde este enlace https://www.kaggle.com/competitions/titanic/data?select=train.csv. Una vez que se descarga el conjunto de datos, se divide en tres archivos CSV.
Importación de bibliotecas y configuración inicial
Python3
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
%matplotlib inline
warnings.filterwarnings('ignore')
Ahora leamos los datos de entrenamiento y prueba usando el marco de datos pandas.
Python3
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# To know number of columns and rows
train.shape
# (891, 12)
Para conocer la información sobre cada columna, como el tipo de datos, etc., usamos la función df.info().
Python3
train.info()
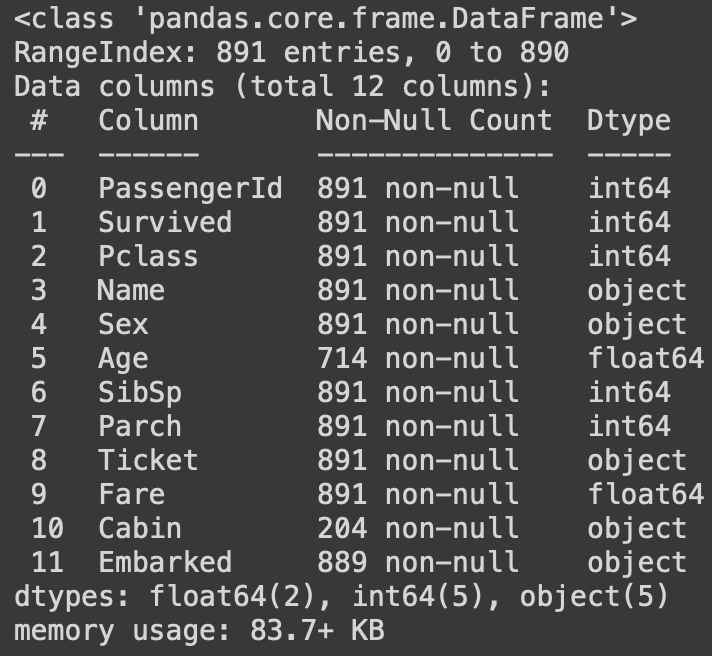
Ahora veamos si hay valores NULL presentes en el conjunto de datos. Esto se puede verificar usando la función isnull(). Produce la siguiente salida.
Python3
train.isnull().sum()
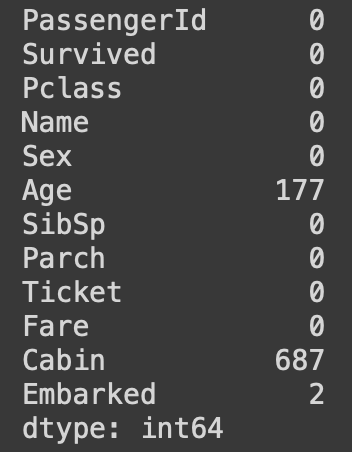
Visualización
Ahora visualicemos los datos usando algunos gráficos circulares e histogramas para obtener una comprensión adecuada de los datos.
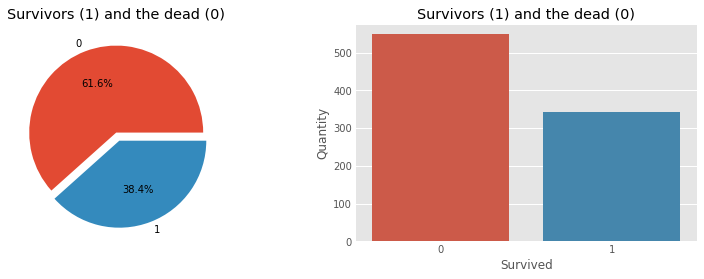
Primero visualicemos el número de sobrevivientes y recuentos de muertes.
Python3
f, ax = plt.subplots(1, 2, figsize=(12, 4))
train['Survived'].value_counts().plot.pie(
explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=False)
ax[0].set_title('Survivors (1) and the dead (0)')
ax[0].set_ylabel('')
sns.countplot('Survived', data=train, ax=ax[1])
ax[1].set_ylabel('Quantity')
ax[1].set_title('Survivors (1) and the dead (0)')
plt.show()
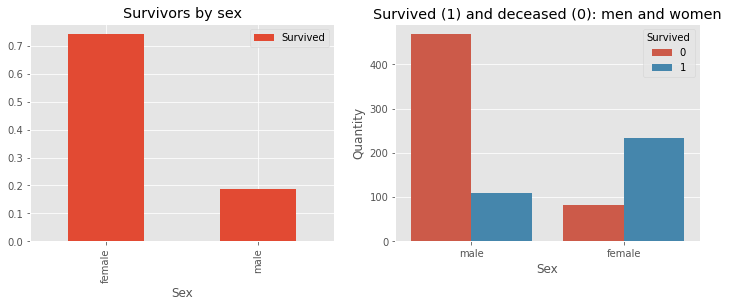
Característica sexual
Python3
f, ax = plt.subplots(1, 2, figsize=(12, 4))
train[['Sex', 'Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survivors by sex')
sns.countplot('Sex', hue='Survived', data=train, ax=ax[1])
ax[1].set_ylabel('Quantity')
ax[1].set_title('Survived (1) and deceased (0): men and women')
plt.show()
Ingeniería de funciones
Ahora veamos qué columnas debemos eliminar y/o modificar para que el modelo prediga los datos de prueba. Las tareas principales en este paso son eliminar funciones innecesarias y convertir datos de strings en la categoría numérica para facilitar el entrenamiento.
Comenzaremos eliminando la función Cabina, ya que no se puede extraer mucha más información útil de ella. Pero haremos una nueva columna a partir de la columna Cabañas para ver si había información de cabina asignada o no.
Python3
# Create a new column cabinbool indicating
# if the cabin value was given or was NaN
train["CabinBool"] = (train["Cabin"].notnull().astype('int'))
test["CabinBool"] = (test["Cabin"].notnull().astype('int'))
# Delete the column 'Cabin' from test
# and train dataset
train = train.drop(['Cabin'], axis=1)
test = test.drop(['Cabin'], axis=1)
También podemos descartar la función Ticket, ya que es poco probable que brinde información útil.
Python3
train = train.drop(['Ticket'], axis=1) test = test.drop(['Ticket'], axis=1)
Faltan valores en la función Embarcado. Para eso, reemplazaremos los valores NULL con ‘S’ ya que el número de Embarques para ‘S’ es mayor que los otros dos.
Python3
# replacing the missing values in
# the Embarked feature with S
train = train.fillna({"Embarked": "S"})
Ahora ordenaremos la edad en grupos. Combinaremos los grupos de edad de las personas y los clasificaremos en los mismos grupos. AL hacerlo, tendremos menos categorías y tendremos una mejor predicción, ya que será un conjunto de datos categóricos.
Python3
# sort the ages into logical categories train["Age"] = train["Age"].fillna(-0.5) test["Age"] = test["Age"].fillna(-0.5) bins = [-1, 0, 5, 12, 18, 24, 35, 60, np.inf] labels = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Senior'] train['AgeGroup'] = pd.cut(train["Age"], bins, labels=labels) test['AgeGroup'] = pd.cut(test["Age"], bins, labels=labels)
En la columna ‘título’ tanto para la prueba como para el conjunto de trenes, los clasificaremos en el mismo número de clases. Luego, asignaremos valores numéricos al título para facilitar el entrenamiento del modelo.
Python3
# create a combined group of both datasets
combine = [train, test]
# extract a title for each Name in the
# train and test datasets
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train['Title'], train['Sex'])
# replace various titles with more common names
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Capt', 'Col',
'Don', 'Dr', 'Major',
'Rev', 'Jonkheer', 'Dona'],
'Rare')
dataset['Title'] = dataset['Title'].replace(
['Countess', 'Lady', 'Sir'], 'Royal')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()
# map each of the title groups to a numerical value
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3,
"Master": 4, "Royal": 5, "Rare": 6}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
Ahora, utilizando la información del título, podemos completar los valores de edad que faltan.
Python3
mr_age = train[train["Title"] == 1]["AgeGroup"].mode() # Young Adult
miss_age = train[train["Title"] == 2]["AgeGroup"].mode() # Student
mrs_age = train[train["Title"] == 3]["AgeGroup"].mode() # Adult
master_age = train[train["Title"] == 4]["AgeGroup"].mode() # Baby
royal_age = train[train["Title"] == 5]["AgeGroup"].mode() # Adult
rare_age = train[train["Title"] == 6]["AgeGroup"].mode() # Adult
age_title_mapping = {1: "Young Adult", 2: "Student",
3: "Adult", 4: "Baby", 5: "Adult", 6: "Adult"}
for x in range(len(train["AgeGroup"])):
if train["AgeGroup"][x] == "Unknown":
train["AgeGroup"][x] = age_title_mapping[train["Title"][x]]
for x in range(len(test["AgeGroup"])):
if test["AgeGroup"][x] == "Unknown":
test["AgeGroup"][x] = age_title_mapping[test["Title"][x]]
Ahora asigne un valor numérico a cada categoría de edad. Una vez que hemos mapeado la edad en diferentes categorías, no necesitamos la función de edad. Por lo tanto, déjalo
Python3
# map each Age value to a numerical value
age_mapping = {'Baby': 1, 'Child': 2, 'Teenager': 3,
'Student': 4, 'Young Adult': 5, 'Adult': 6,
'Senior': 7}
train['AgeGroup'] = train['AgeGroup'].map(age_mapping)
test['AgeGroup'] = test['AgeGroup'].map(age_mapping)
train.head()
# dropping the Age feature for now, might change
train = train.drop(['Age'], axis=1)
test = test.drop(['Age'], axis=1)
Descarte la función de nombre ya que no contiene más información útil.
Python3
train = train.drop(['Name'], axis=1) test = test.drop(['Name'], axis=1)
Asigne valores numéricos a las categorías de sexo y embarque\
Python3
sex_mapping = {"male": 0, "female": 1}
train['Sex'] = train['Sex'].map(sex_mapping)
test['Sex'] = test['Sex'].map(sex_mapping)
embarked_mapping = {"S": 1, "C": 2, "Q": 3}
train['Embarked'] = train['Embarked'].map(embarked_mapping)
test['Embarked'] = test['Embarked'].map(embarked_mapping)
Complete el valor de la tarifa que falta en el conjunto de prueba en función de la tarifa media para esa clase P
Python3
for x in range(len(test["Fare"])): if pd.isnull(test["Fare"][x]): pclass = test["Pclass"][x] # Pclass = 3 test["Fare"][x] = round( train[train["Pclass"] == pclass]["Fare"].mean(), 4) # map Fare values into groups of # numerical values train['FareBand'] = pd.qcut(train['Fare'], 4, labels=[1, 2, 3, 4]) test['FareBand'] = pd.qcut(test['Fare'], 4, labels=[1, 2, 3, 4]) # drop Fare values train = train.drop(['Fare'], axis=1) test = test.drop(['Fare'], axis=1)
Ahora hemos terminado con la ingeniería de funciones.
Entrenamiento modelo
Usaremos Random Forest como el algoritmo de elección para realizar el entrenamiento del modelo. Antes de eso, dividiremos los datos en una proporción de 80:20 como una división de prueba de tren. Para eso, usaremos train_test_split() de la biblioteca sklearn.
Python3
from sklearn.model_selection import train_test_split # Drop the Survived and PassengerId # column from the trainset predictors = train.drop(['Survived', 'PassengerId'], axis=1) target = train["Survived"] x_train, x_val, y_train, y_val = train_test_split( predictors, target, test_size=0.2, random_state=0)
Ahora importe la función de bosque aleatorio desde el módulo de conjunto de sklearn y active el conjunto de entrenamiento.
Python3
from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score randomforest = RandomForestClassifier() # Fit the training data along with its output randomforest.fit(x_train, y_train) y_pred = randomforest.predict(x_val) # Find the accuracy score of the model acc_randomforest = round(accuracy_score(y_pred, y_val) * 100, 2) print(acc_randomforest)
Con esto, obtuvimos una precisión del 83,25%
Predicción
Se nos proporciona el conjunto de datos de prueba sobre el que tenemos que realizar la predicción. Para predecir, pasaremos el conjunto de datos de prueba a nuestro modelo entrenado y lo guardaremos en un archivo CSV que contenga la información, el ID del pasajero y la supervivencia. PassengerId será el ID de pasajero de los pasajeros en los datos de prueba y la columna de supervivencia será 0 o 1.
Python3
ids = test['PassengerId']
predictions = randomforest.predict(test.drop('PassengerId', axis=1))
# set the output as a dataframe and convert
# to csv file named resultfile.csv
output = pd.DataFrame({'PassengerId': ids, 'Survived': predictions})
output.to_csv('resultfile.csv', index=False)
Esto creará un archivo de resultados.csv que se ve así

Publicación traducida automáticamente
Artículo escrito por sahilgangurde08 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA