Prerrequisitos: comprensión de la regresión logística , regresión logística con Python
En este artículo, analizaremos cómo predecir el estado de ubicación de un estudiante en función de varios atributos del estudiante utilizando el algoritmo de regresión logística.
Las prácticas tienen una gran importancia para los estudiantes y las instituciones educativas. Ayuda a un estudiante a construir una base sólida para la carrera profesional que tiene por delante, así como un buen registro de colocación le da una ventaja competitiva a una universidad en el mercado educativo.
Este estudio se enfoca en un sistema que predice si un estudiante sería colocado o no en base a las calificaciones, datos históricos y experiencia del estudiante. Este predictor utiliza un algoritmo de aprendizaje automático para dar el resultado.
El algoritmo utilizado es la regresión logística. La regresión logística es básicamente un algoritmo de clasificación supervisado. En un problema de clasificación, la variable de destino (o salida), y, puede tomar solo valores discretos para un conjunto dado de características (o entradas), X. Hablando sobre el conjunto de datos, contiene el porcentaje de escuela secundaria, porcentaje de escuela secundaria superior, grado porcentaje, grado y experiencia laboral de los estudiantes. Después de predecir el resultado, su eficiencia también se calcula en función del conjunto de datos. El conjunto de datos utilizado aquí está en formato .csv .
A continuación se muestra el enfoque paso a paso:
Paso 1: Importe los módulos requeridos.
Python
# import modules import pandas as pd import numpy as np import matplotlib.pyplot as plt
Paso 2: ahora para leer el conjunto de datos que vamos a usar para el análisis y luego verificar el conjunto de datos.
Python
# reading the file
dataset = pd.read_csv('Placement_Data_Full_Class.csv')
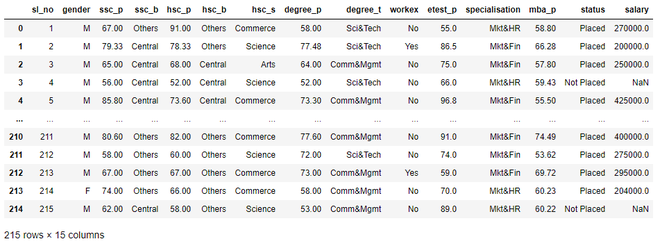
dataset
Producción:
Paso 3: Ahora soltaremos las columnas que no sean necesarias.
Python
# dropping the serial no and salary col
dataset = dataset.drop('sl_no', axis=1)
dataset = dataset.drop('salary', axis=1)
Paso 4: ahora, antes de seguir adelante, debemos preprocesar y transformar nuestros datos. Para eso, usaremos el método astype() en algunas columnas y cambiaremos el tipo de datos a categoría .
Python
# catgorising col for further labelling
dataset["gender"] = dataset["gender"].astype('category')
dataset["ssc_b"] = dataset["ssc_b"].astype('category')
dataset["hsc_b"] = dataset["hsc_b"].astype('category')
dataset["degree_t"] = dataset["degree_t"].astype('category')
dataset["workex"] = dataset["workex"].astype('category')
dataset["specialisation"] = dataset["specialisation"].astype('category')
dataset["status"] = dataset["status"].astype('category')
dataset["hsc_s"] = dataset["hsc_s"].astype('category')
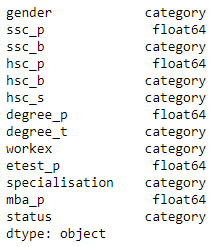
dataset.dtypes
Producción:
Paso 5: ahora aplicaremos códigos en algunas de estas columnas para convertir sus valores de texto en valores numéricos.
Python
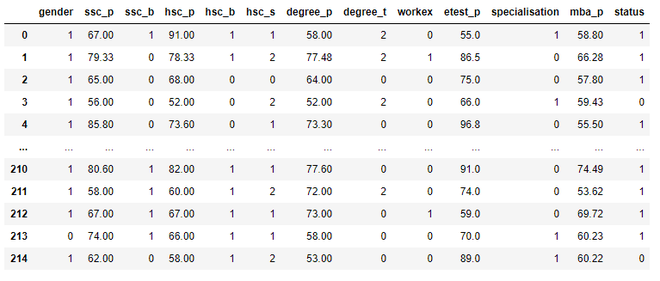
# labelling the columns dataset["gender"] = dataset["gender"].cat.codes dataset["ssc_b"] = dataset["ssc_b"].cat.codes dataset["hsc_b"] = dataset["hsc_b"].cat.codes dataset["degree_t"] = dataset["degree_t"].cat.codes dataset["workex"] = dataset["workex"].cat.codes dataset["specialisation"] = dataset["specialisation"].cat.codes dataset["status"] = dataset["status"].cat.codes dataset["hsc_s"] = dataset["hsc_s"].cat.codes # display dataset dataset
Producción:
Paso 6: Ahora, para dividir el conjunto de datos en características y valores usando la función iloc() :
Python
# selecting the features and labels X = dataset.iloc[:, :-1].values Y = dataset.iloc[:, -1].values # display dependent variables Y
Producción:
Paso 7: ahora dividiremos el conjunto de datos en datos de entrenamiento y prueba que se usarán para verificar la eficiencia más adelante.
Python
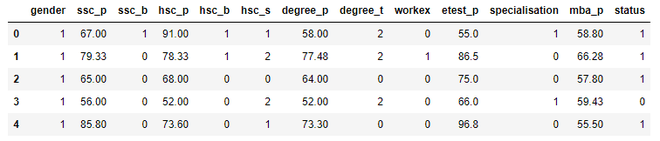
# dividing the data into train and test from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2) # display dataset dataset.head()
Producción:
Paso 8: Ahora necesitamos entrenar nuestro modelo para lo cual necesitaremos importar un archivo, y luego crearemos un clasificador usando el módulo sklearn . Luego comprobaremos la precisión del modelo.
Python
# creating a classifier using sklearn from sklearn.linear_model import LogisticRegression clf = LogisticRegression(random_state=0, solver='lbfgs', max_iter=1000).fit(X_train, Y_train) # printing the acc clf.score(X_test, Y_test)
Producción:
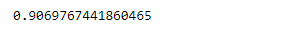
Paso 9: Una vez que hayamos entrenado el modelo, lo comprobaremos dando unos valores aleatorios:
Python
# predicting for random value clf.predict([[0, 87, 0, 95, 0, 2, 78, 2, 0, 0, 1, 0]])
Producción:
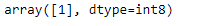
Paso 10: Para obtener una comprensión más matizada del rendimiento de nuestro modelo, necesitamos hacer una array de confusión. Una array de confusión es una tabla con dos filas y dos columnas que informa el número de falsos positivos, falsos negativos, verdaderos positivos y verdaderos negativos.
Para obtener la array de confusión, se necesitan dos argumentos: las etiquetas reales de su conjunto de prueba y_test y las etiquetas predichas. Las etiquetas pronosticadas del clasificador se almacenan en y_pred de la siguiente manera:
Python
# creating a Y_pred for test data Y_pred = clf.predict(X_test) # display predicted values Y_pred
Producción:

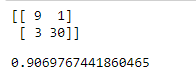
Paso 11: Finalmente, tenemos y_pred, por lo que podemos generar la array de confusión:
Python
# evaluation of the classifier from sklearn.metrics import confusion_matrix, accuracy_score # display confusion matrix print(confusion_matrix(Y_test, Y_pred)) # display accuracy print(accuracy_score(Y_test, Y_pred))
Producción:
Publicación traducida automáticamente
Artículo escrito por ghaishradha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA