Preprocesamiento en minería de datos:
el preprocesamiento de datos es una técnica de minería de datos que se utiliza para transformar los datos sin procesar en un formato útil y eficiente.
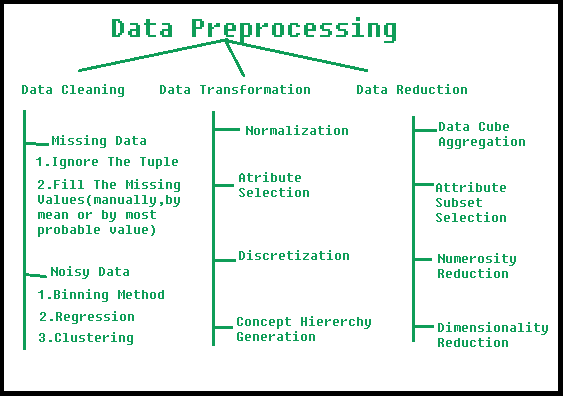
Pasos involucrados en el preprocesamiento de datos:
1. Limpieza de datos:
los datos pueden tener muchas partes irrelevantes y faltantes. Para manejar esta parte, se realiza la limpieza de datos. Implica el manejo de datos faltantes, datos ruidosos, etc.
- (a). Datos faltantes:
esta situación surge cuando faltan algunos datos en los datos. Se puede manejar de varias maneras.
Algunos de ellos son:- Ignorar las tuplas:
este enfoque es adecuado solo cuando el conjunto de datos que tenemos es bastante grande y faltan varios valores dentro de una tupla.
- Rellene los valores que faltan:
hay varias formas de realizar esta tarea. Puede optar por completar los valores faltantes manualmente, por la media del atributo o el valor más probable.
- Ignorar las tuplas:
- (b). Datos ruidosos:
los datos ruidosos son datos sin sentido que las máquinas no pueden interpretar. Se pueden generar debido a una recopilación de datos defectuosa, errores de ingreso de datos, etc. Se pueden manejar de las siguientes maneras:- Método de agrupamiento:
este método funciona en datos ordenados para suavizarlos. Todos los datos se dividen en segmentos de igual tamaño y luego se realizan varios métodos para completar la tarea. Cada segmento se maneja por separado. Se pueden reemplazar todos los datos en un segmento por su media o se pueden usar valores límite para completar la tarea.
- Regresión:
aquí los datos pueden suavizarse ajustándolos a una función de regresión. La regresión utilizada puede ser lineal (con una variable independiente) o múltiple (con múltiples variables independientes).
- Agrupamiento:
este enfoque agrupa los datos similares en un clúster. Los valores atípicos pueden pasar desapercibidos o caerán fuera de los grupos.
- Método de agrupamiento:
2. Transformación de datos:
este paso se toma para transformar los datos en formas apropiadas adecuadas para el proceso de minería. Esto implica las siguientes formas:
- Normalización:
se realiza para escalar los valores de datos en un rango específico (-1.0 a 1.0 o 0.0 a 1.0)
- Selección de atributos:
en esta estrategia, se construyen nuevos atributos a partir del conjunto dado de atributos para ayudar al proceso de minería.
- Discretización:
Esto se hace para reemplazar los valores brutos del atributo numérico por niveles de intervalo o niveles conceptuales.
- Generación de jerarquía de conceptos:
aquí los atributos se convierten de un nivel inferior a un nivel superior en la jerarquía. Por ejemplo: el atributo «ciudad» se puede convertir en «país».
3. Reducción de datos:
dado que la minería de datos es una técnica que se utiliza para manejar una gran cantidad de datos. Mientras trabajaba con un gran volumen de datos, el análisis se volvió más difícil en tales casos. Para deshacernos de esto, utilizamos la técnica de reducción de datos. Su objetivo es aumentar la eficiencia del almacenamiento y reducir los costos de almacenamiento y análisis de datos.
Los diversos pasos para la reducción de datos son:
- Agregación de cubo de datos:
la operación de agregación se aplica a los datos para la construcción del cubo de datos.
- Selección de subconjunto de atributos:
se deben usar los atributos altamente relevantes, el resto se puede descartar. Para realizar la selección de atributos, se puede usar el nivel de significancia y el valor p del atributo. El atributo que tiene un valor p mayor que el nivel de significancia puede descartarse.
- Reducción de Numerosidad:
Esto permite almacenar el modelo de datos en lugar de datos completos, por ejemplo: Modelos de Regresión.
- Reducción de dimensionalidad:
esto reduce el tamaño de los datos mediante mecanismos de codificación. Puede ser con pérdida o sin pérdida. Si después de la reconstrucción a partir de datos comprimidos, los datos originales se pueden recuperar, dicha reducción se denomina reducción sin pérdidas, de lo contrario, se denomina reducción con pérdidas. Los dos métodos efectivos de reducción de la dimensionalidad son: transformadas Wavelet y PCA (Análisis de Componentes Principales).
Publicación traducida automáticamente
Artículo escrito por deepak_jain y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA