CAP popularmente llamado el ‘perfil de precisión acumulativa’ se utiliza en la evaluación del rendimiento del modelo de clasificación. Nos ayuda a comprender y concluir sobre la robustez del modelo de clasificación. Para visualizar esto, se trazan tres curvas distintas en nuestro diagrama:
- Una trama al azar
- Un gráfico obtenido mediante el uso de un clasificador SVM o un clasificador de bosque aleatorio
- Una trama perfecta (una línea ideal)
Estamos trabajando los DATOS para entender el concepto.
Código: Cargando conjunto de datos.
Python3
# importing libraries
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# loading dataset
data = pd.read_csv('C:\\Users\\DELL\\Desktop\\Social_Network_Ads.csv')
print ("Data Head : \n\n", data.head())
Producción :
Data Head :
User ID Gender Age EstimatedSalary Purchased
0 15624510 Male 19 19000 0
1 15810944 Male 35 20000 0
2 15668575 Female 26 43000 0
3 15603246 Female 27 57000 0
4 15804002 Male 19 76000 0
Código: Salida de entrada de datos.
Python3
# Input and Output
x = data.iloc[:, 2:4]
y = data.iloc[:, 4]
print ("Input : \n", x.iloc[0:10, :])
Producción :
Input :
Age EstimatedSalary
0 19 19000
1 35 20000
2 26 43000
3 27 57000
4 19 76000
5 27 58000
6 27 84000
7 32 150000
8 25 33000
9 35 65000
Código: división de conjuntos de datos para entrenamiento y pruebas.
Python3
# splitting data from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split( x, y, test_size = 0.3, random_state = 0)
Código: clasificador de bosque aleatorio
Python3
# classifier from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(n_estimators = 400) # training classifier.fit(x_train, y_train) # predicting pred = classifier.predict(x_test)
Código: encontrar la precisión del clasificador.
Python3
# Model Performance
from sklearn.metrics import accuracy_score
print("Accuracy : ", accuracy_score(y_test, pred) * 100)
Producción :
Accuracy : 91.66666666666666
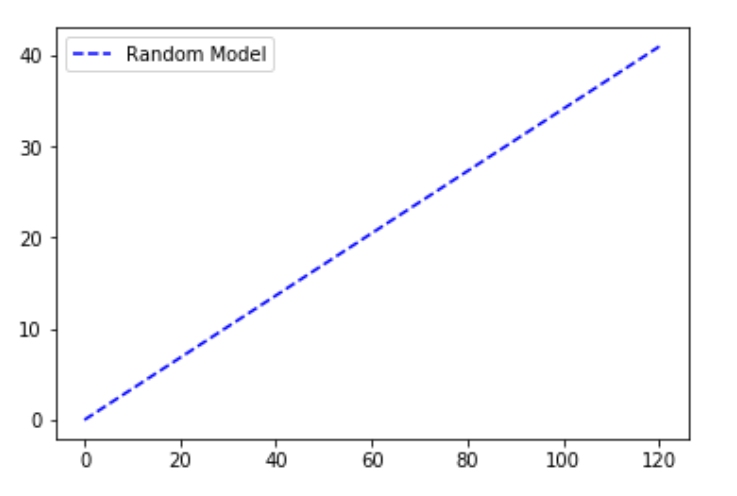
Modelo aleatorio
El gráfico aleatorio se realiza bajo el supuesto de que hemos trazado el número total de puntos que van desde 0 hasta el número total de puntos de datos en el conjunto de datos. El eje y se ha mantenido como el número total de puntos para los que la variable dependiente de nuestro conjunto de datos tiene un resultado de 1. La gráfica aleatoria puede entenderse como una relación linealmente creciente. Un ejemplo es un modelo que predice si un producto es comprado (resultado positivo) por cada individuo de un grupo de personas (parámetro de clasificación) basado en factores como su género, edad, ingresos, etc. Si los miembros del grupo fueran contactados al azar, el número acumulado de productos vendidos aumentaría linealmente hacia un valor máximo correspondiente al número total de compradores dentro del grupo. Esta distribución se denomina CAP “aleatoria” .
Código: modelo aleatorio
Python3
# code for the random plot import matplotlib.pyplot as plt import numpy as np # length of the test data total = len(y_test) # Counting '1' labels in test data one_count = np.sum(y_test) # counting '0' labels in test data zero_count = total - one_count plt.figure(figsize = (10, 6)) # x-axis ranges from 0 to total people contacted # y-axis ranges from 0 to the total positive outcomes. plt.plot([0, total], [0, one_count], c = 'b', linestyle = '--', label = 'Random Model') plt.legend()
Producción :
Línea clasificadora de bosque aleatorio
Código: el algoritmo de clasificación aleatoria de bosques se aplica al conjunto de datos para el gráfico de líneas del clasificador aleatorio .
Python3
lm = [y for _, y in sorted(zip(pred, y_test), reverse = True)] x = np.arange(0, total + 1) y = np.append([0], np.cumsum(lm)) plt.plot(x, y, c = 'b', label = 'Random classifier', linewidth = 2)
Producción :
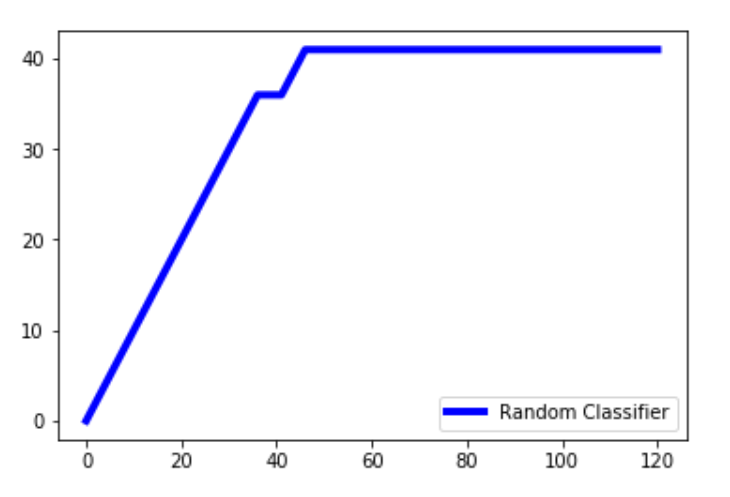
Explicación: pred es la predicción realizada por el clasificador aleatorio. Comprimimos los valores de predicción y prueba y los ordenamos en orden inverso para que los valores más altos aparezcan primero y luego los valores más bajos. Extraemos solo los valores de y_test en una array y los almacenamos en lm . np.cumsum() crea una array de valores mientras agrega acumulativamente todos los valores anteriores en la array al valor actual. Los valores de x oscilarán entre 0 y el total + 1. Agregamos uno al total porque arange() no incluye uno en la array y queremos que el eje x oscile entre 0 y el total.
modelo perfecto
Luego trazamos la trama perfecta (o la línea ideal). Una predicción perfecta determina exactamente qué miembros del grupo comprarán el producto, de modo que el número máximo de productos vendidos se alcance con un número mínimo de llamadas. Esto produce una línea pronunciada en la curva CAP que permanece plana una vez que se alcanza el máximo (contactar a todos los demás miembros del grupo no generará más productos vendidos), que es el CAP «perfecto» .
Python3
plt.plot([0, one_count, total], [0, one_count, one_count], c = 'grey', linewidth = 2, label = 'Perfect Model')
Producción :
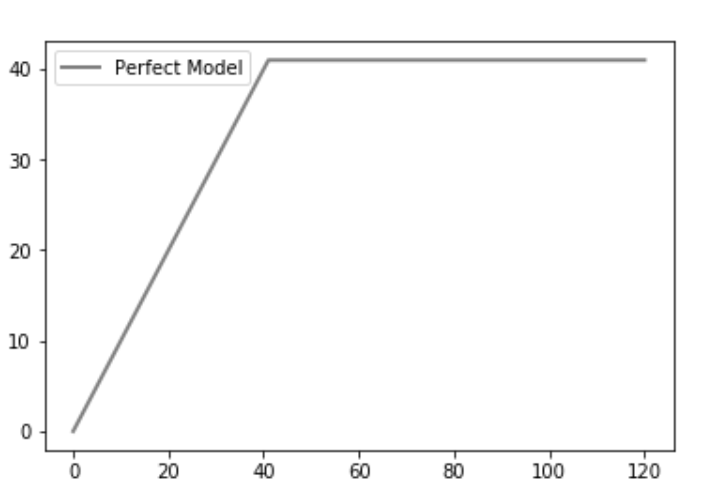
Explicación: un modelo perfecto encuentra resultados positivos en el mismo número de intentos que el número de resultados positivos. Tenemos un total de 41 resultados positivos en nuestro conjunto de datos y, por lo tanto, con exactamente 41, se logra el máximo.
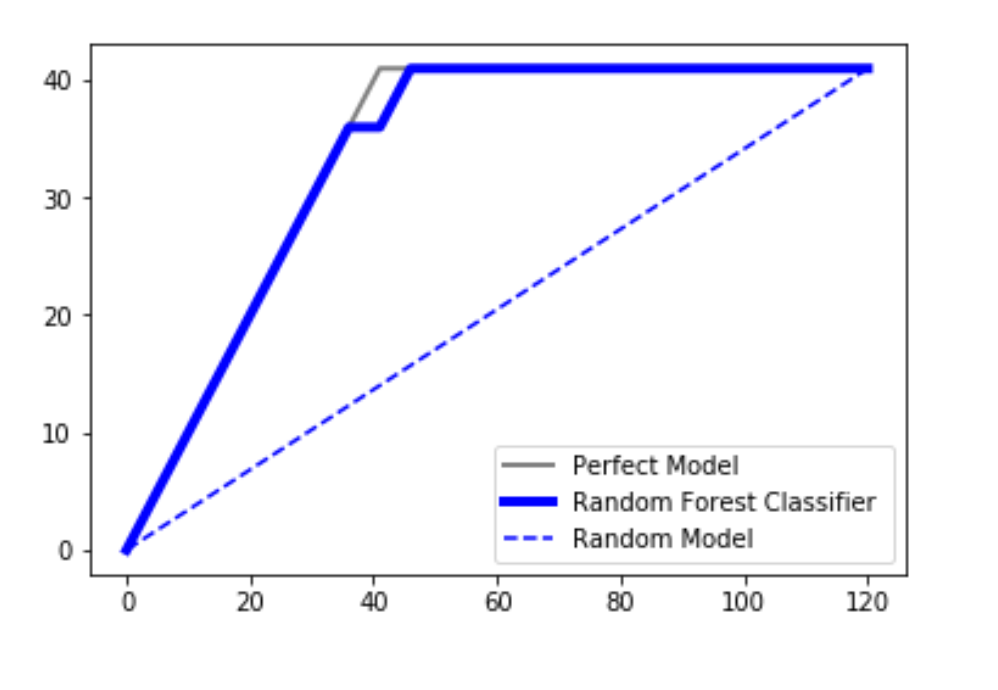
ANÁLISIS FINAL:
En cualquier caso, nuestro algoritmo clasificador no debería producir una línea que se encuentre debajo de la línea aleatoria. Se considera que es un modelo realmente malo en ese caso. Dado que la línea clasificadora trazada está cerca de la línea ideal, podemos decir que nuestro modelo se ajusta realmente bien. Tome el área debajo de la parcela perfecta y llámela aP. Tome el área bajo el modelo de predicción y llámela aR . Luego tome la relación como aR/aP . Esta relación se denomina Tasa de precisión . Cuanto más cerca esté el valor de 1, mejor será el modelo. Esta es una forma de analizarlo.
Otra forma de analizarlo sería proyectar una línea desde aproximadamente el 50 % del eje en el modelo de predicción y proyectarla en el eje y. Digamos que obtenemos el valor de proyección como X%.
-> 60% : it is a really bad model -> 60%<X<70% : it is still a bad model but better than the first case obviously -> 70%<X<80% : it is a good model -> 80%<X<90% : it is a very good model -> 90%<X<100% : it is extraordinarily good and might be one of the overfitting cases.
Entonces, de acuerdo con este análisis, podemos determinar qué tan preciso es nuestro modelo.
Referencia: – wikipedia.org
Publicación traducida automáticamente
Artículo escrito por Choco_Chips y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA