La clasificación de imágenes es un método para clasificar las imágenes de forma en sus respectivas clases de categorías utilizando algunos métodos como:
- Entrenando una red pequeña desde cero
- Ajuste fino de las capas superiores del modelo usando VGG16
Analicemos cómo entrenar el modelo desde cero y clasificar los datos que contienen automóviles y aviones.
- Datos del tren: los datos del tren contienen las 200 imágenes de cada automóvil y avión, es decir, en total, hay 400 imágenes en el conjunto de datos de entrenamiento
- Datos de prueba: Los datos de prueba contienen 50 imágenes de cada automóvil y avión, es decir, incluyen un total. Hay 100 imágenes en el conjunto de datos de prueba
Para descargar el conjunto de datos completo, haga clic aquí .
Prerequisite: Image Classifier using CNN
Descripción del modelo: antes de comenzar con el modelo, primero prepare el conjunto de datos y su disposición. Mira la siguiente imagen que se muestra a continuación:

Para alimentar las carpetas del conjunto de datos, deben crearse y proporcionarse solo en este formato. Entonces, ahora, comencemos con el modelo:
para entrenar el modelo no necesitamos una gran máquina de alta gama y GPU, también podemos trabajar con CPU. En primer lugar, en el código dado se incluyen las siguientes bibliotecas:
Python3
# Importing all necessary libraries from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Conv2D, MaxPooling2D from keras.layers import Activation, Dropout, Flatten, Dense from keras import backend as K img_width, img_height = 224, 224
Cada imagen en el conjunto de datos tiene un tamaño de 224*224.
Python3
train_data_dir = 'v_data/train' validation_data_dir = 'v_data/test' nb_train_samples =400 nb_validation_samples = 100 epochs = 10 batch_size = 16
Aquí, train_data_dir es el directorio del conjunto de datos del tren. validation_data_dir es el directorio para los datos de validación. nb_train_samples es el número total de muestras de trenes. nb_validation_samples es el número total de muestras de validación.
Comprobación del formato de la imagen:
Python3
if K.image_data_format() == 'channels_first': input_shape = (3, img_width, img_height) else: input_shape = (img_width, img_height, 3)
Esta parte es para verificar el formato de datos, es decir, el canal RGB viene primero o último, así que, sea lo que sea, el modelo verificará primero y luego la forma de entrada se alimentará en consecuencia.
Python3
model = Sequential()
model.add(Conv2D(32, (2, 2), input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (2, 2)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (2, 2)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
Sobre los siguientes términos utilizados anteriormente:
Conv2D es la capa para convolucionar la imagen en múltiples imágenes
La activación es la función de activación.
MaxPooling2D se usa para agrupar al máximo el valor de la array de tamaño dada y lo mismo se usa para las siguientes 2 capas. luego, Flatten se usa para aplanar las dimensiones de la imagen obtenida después de convolucionarla.
Dense se usa para hacer de este un modelo completamente conectado y es la capa oculta.
El abandono se utiliza para evitar el sobreajuste en el conjunto de datos.
Densa es la capa de salida que contiene solo una neurona que decide a qué categoría pertenece la imagen.
Función de compilación:
Python3
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
Aquí se utiliza la función de compilación que implica el uso de pérdida, optimizadores y métricas. Aquí la función de pérdida utilizada es binary_crossentropy, el optimizador utilizado es rmsprop .
Usando el generador de datos:
Python3
train_datagen = ImageDataGenerator( rescale=1. / 255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) test_datagen = ImageDataGenerator(rescale=1. / 255) train_generator = train_datagen.flow_from_directory( train_data_dir, target_size=(img_width, img_height), batch_size=batch_size, class_mode='binary') validation_generator = test_datagen.flow_from_directory( validation_data_dir, target_size=(img_width, img_height), batch_size=batch_size, class_mode='binary') model.fit_generator( train_generator, steps_per_epoch=nb_train_samples // batch_size, epochs=epochs, validation_data=validation_generator, validation_steps=nb_validation_samples // batch_size)
Ahora, la parte de dataGenerator entra en la figura. en el que hemos utilizado:
ImageDataGenerator que cambia la escala de la imagen, aplica corte en algún rango, hace zoom en la imagen y realiza un volteo horizontal con la imagen. Este ImageDataGenerator incluye todas las orientaciones posibles de la imagen.
train_datagen.flow_from_directory es la función que se usa para preparar datos del directorio train_dataset Target_size especifica el tamaño objetivo de la imagen.
test_datagen.flow_from_directory se usa para preparar datos de prueba para el modelo y todo es similar al anterior.
fit_generator se utiliza para ajustar los datos en el modelo creado anteriormente, otros factores utilizados son steps_per_epochs que nos informan sobre la cantidad de veces que se ejecutará el modelo para los datos de entrenamiento.
épocasnos dice la cantidad de veces que el modelo será entrenado en pase hacia adelante y hacia atrás.
Validation_data se utiliza para alimentar los datos de validación/prueba en el modelo.
validación_pasos indica el número de muestras de validación/prueba.
Python3
model.save_weights('model_saved.h5')
Por último, también podemos guardar el modelo.
Salida del modelo:
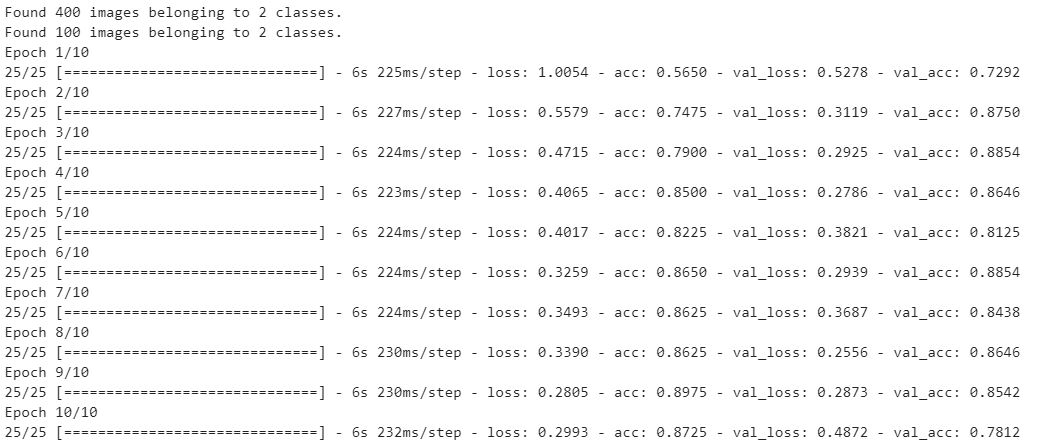
Carga y predicción
- Cargar modelo con «load_model»
- Convierta imágenes en arrays Numpy para pasar al modelo ML
- Imprima la salida predicha del modelo.
Python3
from keras.models import load_model
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.applications.vgg16 import preprocess_input
from keras.applications.vgg16 import decode_predictions
from keras.applications.vgg16 import VGG16
import numpy as np
from keras.models import load_model
model = load_model('model_saved.h5')
image = load_img('v_data/test/planes/5.jpg', target_size=(224, 224))
img = np.array(image)
img = img / 255.0
img = img.reshape(1,224,224,3)
label = model.predict(img)
print("Predicted Class (0 - Cars , 1- Planes): ", label[0][0])
Producción :
Clase prevista (0 – Coches, 1- Aviones): 1
Publicación traducida automáticamente
Artículo escrito por Nitish_Gangwar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA