Escalado o estandarización de características : es un paso del preprocesamiento de datos que se aplica a variables independientes o características de los datos. Básicamente ayuda a normalizar los datos dentro de un rango particular. A veces, también ayuda a acelerar los cálculos en un algoritmo.
Paquete utilizado:
sklearn.preprocessing
Importar:
from sklearn.preprocessing import StandardScaler
La fórmula utilizada en
la estandarización de back-end reemplaza los valores con sus puntajes Z.
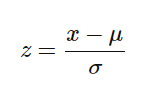
Principalmente, el método de ajuste se usa para el escalado de características
fit(X, y = None) Computes the mean and std to be used for later scaling.
Python
import pandas as pd
from sklearn.preprocessing import StandardScaler
# Read Data from CSV
data = read_csv('Geeksforgeeks.csv')
data.head()
# Initialise the Scaler
scaler = StandardScaler()
# To scale data
scaler.fit(data)
¿Por qué y dónde aplicar el escalado de características?
El conjunto de datos del mundo real contiene características que varían mucho en magnitudes, unidades y rango. La normalización debe realizarse cuando la escala de una característica es irrelevante o engañosa y no debe normalizarse cuando la escala es significativa.
Los algoritmos que utilizan medidas de distancia euclidiana son sensibles a las magnitudes. Aquí el escalado de funciones ayuda a sopesar todas las funciones por igual.
Formalmente, si una característica en el conjunto de datos es de gran escala en comparación con otras, en los algoritmos donde se mide la distancia euclidiana, esta característica de gran escala se vuelve dominante y debe normalizarse.
Ejemplos de algoritmos en los que el escalado de características es importante
1. K-Means utiliza la medida de distancia euclidiana aquí el escalado de características es importante.
2. K-Nearest-Neighbors también requiere escalado de características.
3. Análisis de componentes principales (PCA) : trata de obtener la función con la máxima variación, aquí también se requiere escalar la función.
4. Descenso de gradiente : la velocidad de cálculo aumenta a medida que el cálculo Theta se vuelve más rápido después de escalar características.
Nota: Los modelos Naive Bayes, Análisis Discriminante Lineal y Basado en Árbol no se ven afectados por la escala de características.
En resumen, cualquier algoritmo que no esté basado en la distancia no se ve afectado por el escalado de funciones.
Publicación traducida automáticamente
Artículo escrito por shaurya uppal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA