La biblioteca Sklearn de Python proporciona un excelente generador de conjuntos de datos de muestra que lo ayudará a crear su propio conjunto de datos personalizado. Es rápido y muy fácil de usar. Los siguientes son los tipos de muestras que proporciona.
Para todos los métodos anteriores, debe importar sklearn.datasets.samples_generator .
Python3
# importing libraries from sklearn.datasets import make_blobs # matplotlib for ploting from matplotlib import pyplot as plt from matplotlib import style
sklearn.datasets.make_blobs
Python3
# Creating Test DataSets using sklearn.datasets.make_blobs
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
from matplotlib import style
style.use("fivethirtyeight")
X, y = make_blobs(n_samples = 100, centers = 3,
cluster_std = 1, n_features = 2)
plt.scatter(X[:, 0], X[:, 1], s = 40, color = 'g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()
Producción:
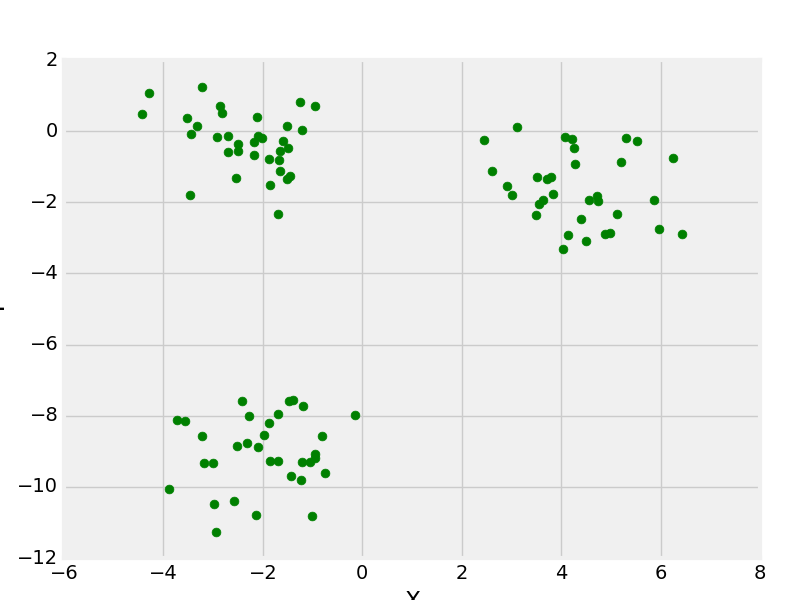
make_blobs con 3 centros
sklearn.conjuntos de datos.make_moon
Python3
# Creating Test DataSets using sklearn.datasets.make_moon
from sklearn.datasets import make_moons
from matplotlib import pyplot as plt
from matplotlib import style
X, y = make_moons(n_samples = 1000, noise = 0.1)
plt.scatter(X[:, 0], X[:, 1], s = 40, color ='g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()
Producción:
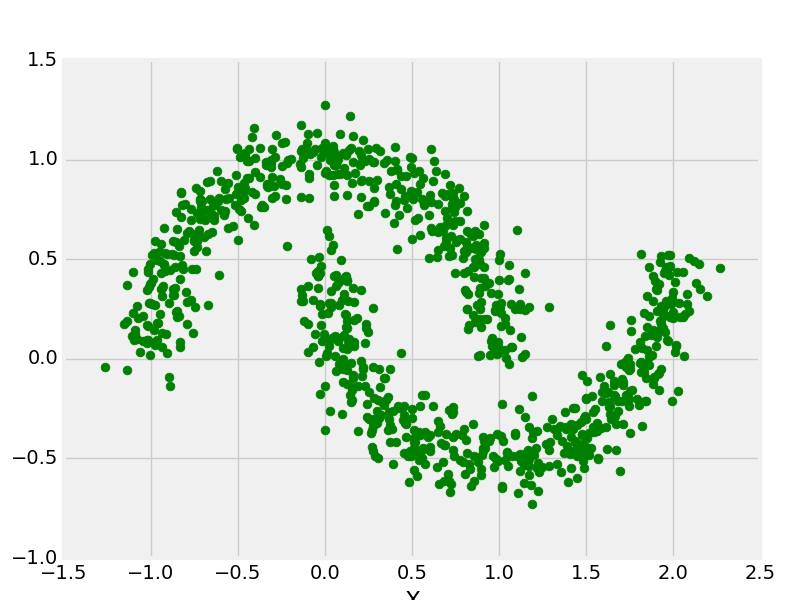
make_moons con 1000 puntos de datos
sklearn.datasets.make_circle
Python3
# Creating Test DataSets using sklearn.datasets.make_circles
from sklearn.datasets import make_circles
from matplotlib import pyplot as plt
from matplotlib import style
style.use("fivethirtyeight")
X, y = make_circles(n_samples = 100, noise = 0.02)
plt.scatter(X[:, 0], X[:, 1], s = 40, color ='g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()
Producción:
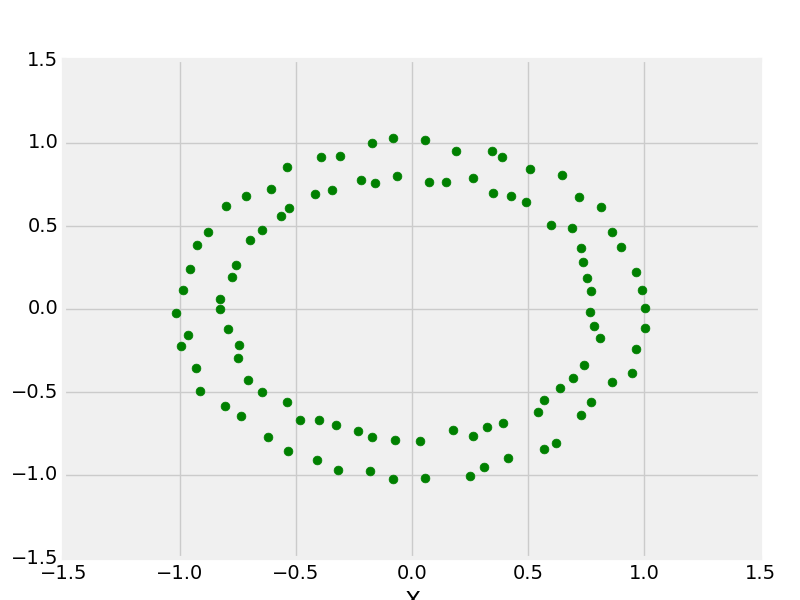
hacer _circle con 100 puntos de datos
Publicación traducida automáticamente
Artículo escrito por Praveen Sinha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA