Word Embedding es una técnica de modelado de lenguaje que se utiliza para asignar palabras a vectores de números reales. Representa palabras o frases en espacio vectorial con varias dimensiones. Las incrustaciones de palabras se pueden generar utilizando varios métodos, como redes neuronales, array de co-ocurrencia, modelos probabilísticos, etc. Word2Vec consta de modelos para generar incrustaciones de palabras. Estos modelos son redes neuronales superficiales de dos capas que tienen una capa de entrada, una capa oculta y una capa de salida. Word2Vec utiliza dos arquitecturas:
- CBOW (Bolsa continua de palabras): el modelo CBOW predice la palabra actual dadas las palabras de contexto dentro de una ventana específica. La capa de entrada contiene las palabras de contexto y la capa de salida contiene la palabra actual. La capa oculta contiene el número de dimensiones en las que queremos representar la palabra actual presente en la capa de salida.
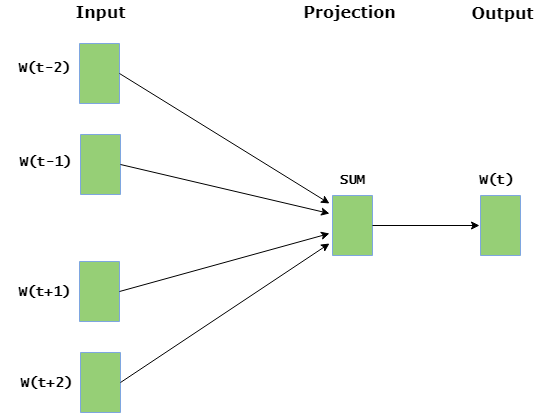
- Skip Gram: Skip gram predice las palabras de contexto circundantes
- dentro de una ventana específica dada la palabra actual. La capa de entrada contiene la palabra actual y la capa de salida contiene las palabras de contexto. La capa oculta contiene el número de dimensiones en las que queremos representar la palabra actual presente en la capa de entrada.
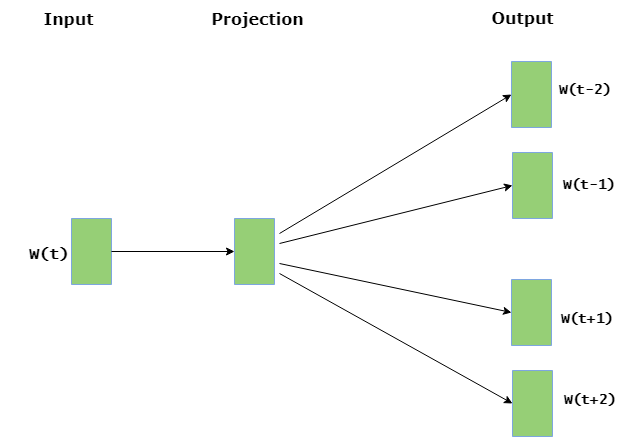
La idea básica de la incrustación de palabras es que las palabras que aparecen en un contexto similar tienden a estar más cerca unas de otras en el espacio vectorial. Para generar vectores de palabras en Python, los módulos necesarios son nltk y gensim . Ejecute estos comandos en la terminal para instalar nltk y gensim :
pip install nltk pip install gensim
Descargue el archivo de texto utilizado para generar vectores de palabras desde aquí . A continuación se muestra la implementación:
Python
# Python program to generate word vectors using Word2Vec
# importing all necessary modules
from nltk.tokenize import sent_tokenize, word_tokenize
import warnings
warnings.filterwarnings(action = 'ignore')
import gensim
from gensim.models import Word2Vec
# Reads ‘alice.txt’ file
sample = open("C:\\Users\\Admin\\Desktop\\alice.txt", "utf8")
s = sample.read()
# Replaces escape character with space
f = s.replace("\n", " ")
data = []
# iterate through each sentence in the file
for i in sent_tokenize(f):
temp = []
# tokenize the sentence into words
for j in word_tokenize(i):
temp.append(j.lower())
data.append(temp)
# Create CBOW model
model1 = gensim.models.Word2Vec(data, min_count = 1,
vector_size = 100, window = 5)
# Print results
print("Cosine similarity between 'alice' " +
"and 'wonderland' - CBOW : ",
model1.wv.similarity('alice', 'wonderland'))
print("Cosine similarity between 'alice' " +
"and 'machines' - CBOW : ",
model1.wv.similarity('alice', 'machines'))
# Create Skip Gram model
model2 = gensim.models.Word2Vec(data, min_count = 1, vector_size = 100,
window = 5, sg = 1)
# Print results
print("Cosine similarity between 'alice' " +
"and 'wonderland' - Skip Gram : ",
model2.wv.similarity('alice', 'wonderland'))
print("Cosine similarity between 'alice' " +
"and 'machines' - Skip Gram : ",
model2.wv.similarity('alice', 'machines'))
Producción :
Cosine similarity between 'alice' and 'wonderland' - CBOW : 0.999249298413 Cosine similarity between 'alice' and 'machines' - CBOW : 0.974911910445 Cosine similarity between 'alice' and 'wonderland' - Skip Gram : 0.885471373104 Cosine similarity between 'alice' and 'machines' - Skip Gram : 0.856892599521
La salida indica las similitudes de coseno entre los vectores de palabras ‘alicia’, ‘país de las maravillas’ y ‘máquinas’ para diferentes modelos. Una tarea interesante podría ser cambiar los valores de los parámetros de ‘tamaño’ y ‘ventana’ para observar las variaciones en las similitudes del coseno.
Applications of Word Embedding : >> Sentiment Analysis >> Speech Recognition >> Information Retrieval >> Question Answering
Referencias :
Publicación traducida automáticamente
Artículo escrito por SumedhKadam y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA