Requisito previo: Aprendizaje por refuerzo
El aprendizaje por refuerzo es brevemente un paradigma del proceso de aprendizaje en el que un agente de aprendizaje aprende, con el tiempo, a comportarse de manera óptima en un determinado entorno interactuando continuamente en el entorno. El agente durante su curso de aprendizaje experimenta varias situaciones diferentes en el entorno en el que se encuentra. Estos se denominan estados . El agente, mientras se encuentra en ese estado, puede elegir entre un conjunto de acciones permitidas que pueden obtener diferentes recompensas (o penalizaciones). El agente de aprendizaje aprende con el tiempo a maximizar estas recompensas para comportarse de manera óptima en cualquier estado en el que se encuentre.
Q-Learning es una forma básica de aprendizaje por refuerzo que utiliza valores Q (también llamados valores de acción) para mejorar iterativamente el comportamiento del agente de aprendizaje.
- Valores Q o valores de acción: los valores Q se definen para estados y acciones.
 es una estimación de qué tan bueno es tomar la acción
es una estimación de qué tan bueno es tomar la acción  en el estado
en el estado  . Esta estimación de se calculará iterativamente utilizando la regla TD-Update que veremos en las próximas secciones.
. Esta estimación de se calculará iterativamente utilizando la regla TD-Update que veremos en las próximas secciones. - Recompensas y episodios: un agente a lo largo de su vida comienza desde un estado inicial, realiza una serie de transiciones desde su estado actual al siguiente estado en función de su elección de acción y también del entorno en el que interactúa el agente. En cada paso de transición, el agente de un estado realiza una acción, observa una recompensa del entorno y luego transita a otro estado. Si en algún momento el agente termina en uno de los estados de terminación, significa que no hay más transición posible. Se dice que esto es la finalización de un episodio.
- Diferencia Temporal o TD-Update:
La regla de diferencia temporal o actualización de TD se puede representar de la siguiente manera:
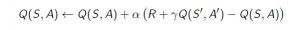
Esta regla de actualización para estimar el valor de Q se aplica en cada paso de tiempo de la interacción de los agentes con el medio ambiente. Los términos utilizados se explican a continuación. :
- : Estado actual del agente.
- : Acción actual Seleccionada de acuerdo con alguna política.
 : Siguiente Estado donde acaba el agente.
: Siguiente Estado donde acaba el agente. : Siguiente mejor acción que se elegirá utilizando la estimación del valor Q actual, es decir, seleccionar la acción con el valor Q máximo en el siguiente estado.
: Siguiente mejor acción que se elegirá utilizando la estimación del valor Q actual, es decir, seleccionar la acción con el valor Q máximo en el siguiente estado. : Recompensa actual observada desde el entorno en respuesta a la acción actual.
: Recompensa actual observada desde el entorno en respuesta a la acción actual. (>0 y <=1) : Factor de descuento para recompensas futuras. Las recompensas futuras son menos valiosas que las recompensas actuales, por lo que deben descontarse. Dado que el valor Q es una estimación de las recompensas esperadas de un estado, aquí también se aplica la regla de descuento.
(>0 y <=1) : Factor de descuento para recompensas futuras. Las recompensas futuras son menos valiosas que las recompensas actuales, por lo que deben descontarse. Dado que el valor Q es una estimación de las recompensas esperadas de un estado, aquí también se aplica la regla de descuento. : Longitud del paso tomado para actualizar la estimación de Q(S, A).
: Longitud del paso tomado para actualizar la estimación de Q(S, A).
- Elección de la acción a realizar mediante
 la directiva -greedy:
-La política codiciosa de es una política muy simple de elegir acciones utilizando las estimaciones actuales del valor Q. Va de la siguiente manera:
la directiva -greedy:
-La política codiciosa de es una política muy simple de elegir acciones utilizando las estimaciones actuales del valor Q. Va de la siguiente manera:- Elija con probabilidad
 la acción que tenga el valor Q más alto.
la acción que tenga el valor Q más alto. - Con probabilidad
 elige cualquier acción al azar.
elige cualquier acción al azar.
- Elija con probabilidad
Ahora, con toda la teoría requerida en la mano, tomemos un ejemplo. Usaremos el entorno de gimnasio de OpenAI para entrenar nuestro modelo Q-Learning.
Comando para instalar gym –
pip install gym
Antes de comenzar con el ejemplo, necesitará algún código de ayuda para visualizar el funcionamiento de los algoritmos. Habrá dos archivos de ayuda que deben descargarse en el directorio de trabajo. Uno puede encontrar los archivos aquí .
Paso #1: Importe las bibliotecas requeridas.
import gymimport itertoolsimport matplotlibimport matplotlib.styleimport numpy as npimport pandas as pdimport sys from collections import defaultdictfrom windy_gridworld import WindyGridworldEnvimport plotting matplotlib.style.use('ggplot') |
Paso #2: Crea un ambiente de gimnasio.
env = WindyGridworldEnv() |
Paso n.º 3: Haga la política codiciosa.
def createEpsilonGreedyPolicy(Q, epsilon, num_actions): """ Creates an epsilon-greedy policy based on a given Q-function and epsilon. Returns a function that takes the state as an input and returns the probabilities for each action in the form of a numpy array of length of the action space(set of possible actions). """ def policyFunction(state): Action_probabilities = np.ones(num_actions, dtype = float) * epsilon / num_actions best_action = np.argmax(Q[state]) Action_probabilities[best_action] += (1.0 - epsilon) return Action_probabilities return policyFunction |
Paso n.º 4: Construya el modelo Q-Learning.
def qLearning(env, num_episodes, discount_factor = 1.0, alpha = 0.6, epsilon = 0.1): """ Q-Learning algorithm: Off-policy TD control. Finds the optimal greedy policy while improving following an epsilon-greedy policy""" # Action value function # A nested dictionary that maps # state -> (action -> action-value). Q = defaultdict(lambda: np.zeros(env.action_space.n)) # Keeps track of useful statistics stats = plotting.EpisodeStats( episode_lengths = np.zeros(num_episodes), episode_rewards = np.zeros(num_episodes)) # Create an epsilon greedy policy function # appropriately for environment action space policy = createEpsilonGreedyPolicy(Q, epsilon, env.action_space.n) # For every episode for ith_episode in range(num_episodes): # Reset the environment and pick the first action state = env.reset() for t in itertools.count(): # get probabilities of all actions from current state action_probabilities = policy(state) # choose action according to # the probability distribution action = np.random.choice(np.arange( len(action_probabilities)), p = action_probabilities) # take action and get reward, transit to next state next_state, reward, done, _ = env.step(action) # Update statistics stats.episode_rewards[ith_episode] += reward stats.episode_lengths[ith_episode] = t # TD Update best_next_action = np.argmax(Q[next_state]) td_target = reward + discount_factor * Q[next_state][best_next_action] td_delta = td_target - Q[state][action] Q[state][action] += alpha * td_delta # done is True if episode terminated if done: break state = next_state return Q, stats |
Paso #5: Entrene al modelo.
Q, stats = qLearning(env, 1000) |
Paso #6: Trace estadísticas importantes.
plotting.plot_episode_stats(stats) |
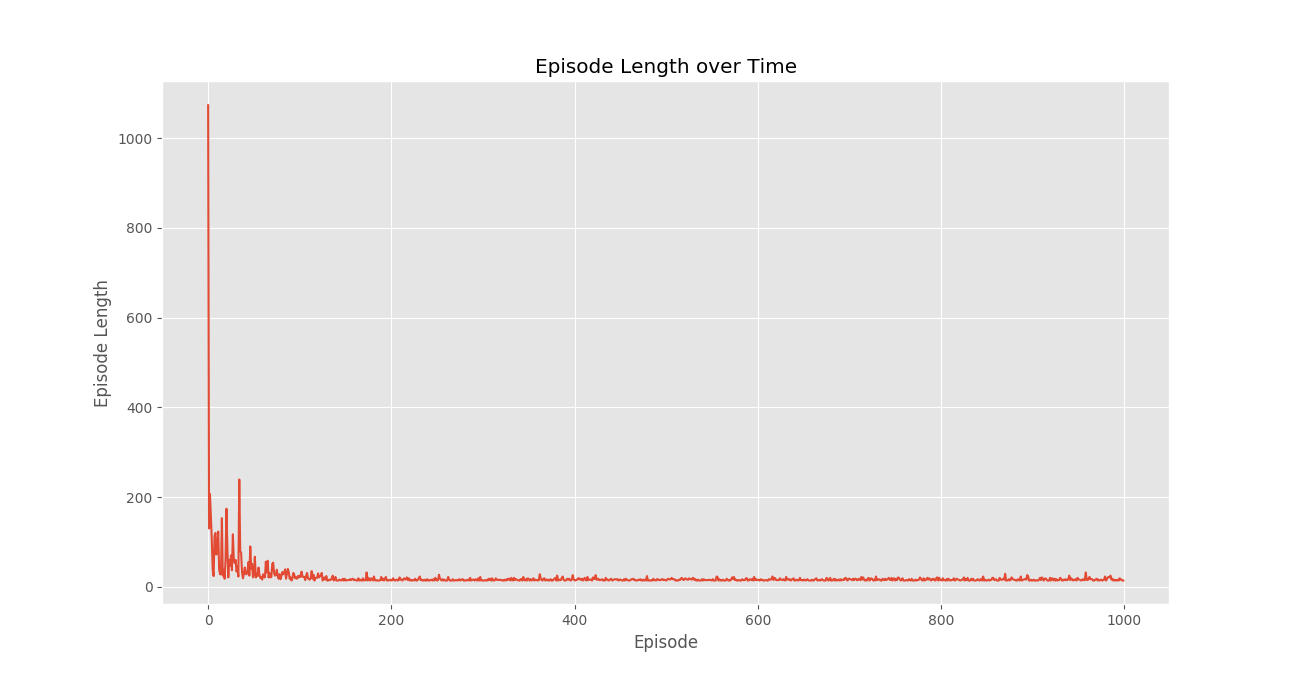
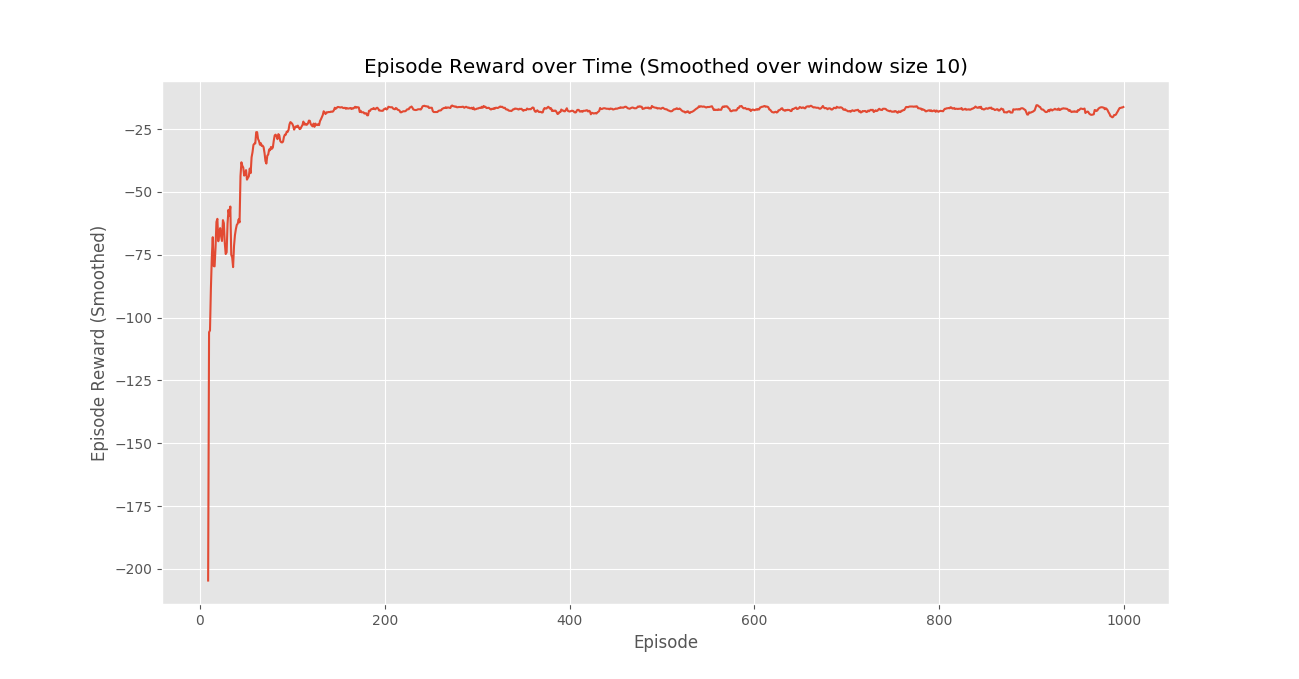
Conclusión:
Vemos que en el gráfico Recompensa del episodio a lo largo del tiempo, las recompensas del episodio aumentan progresivamente con el tiempo y, en última instancia , se nivelan en un valor alto de recompensa por episodio, lo que indica que el agente ha aprendido a maximizar su recompensa total obtenida en un episodio al comportarse de manera óptima. en cada estado.
Publicación traducida automáticamente
Artículo escrito por Kaustav kumar Chanda y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA