El análisis exploratorio de datos (EDA) es un enfoque para analizar los datos utilizando técnicas visuales. Se utiliza para descubrir tendencias, patrones o comprobar supuestos con la ayuda de representaciones gráficas y resumidas estadísticas.
Conjunto de datos utilizado
Para simplificar el artículo, utilizaremos un solo conjunto de datos. Usaremos los datos de los empleados para esto. Contiene 8 columnas, a saber: nombre, sexo, fecha de inicio, último inicio de sesión, salario, % de bonificación, alta dirección y equipo.
Conjunto de datos utilizado: Employees.csv
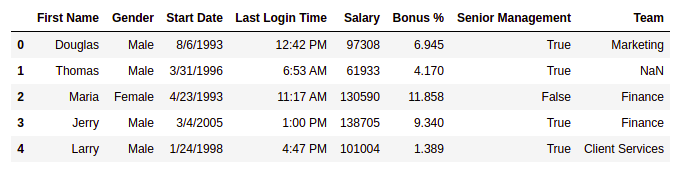
Leamos el conjunto de datos usando el módulo Pandas e imprimamos las primeras cinco filas. Para imprimir las primeras cinco filas usaremos la función head() .
Ejemplo:
Python3
import pandas as pd
import numpy as np
df = pd.read_csv('employees.csv')
df.head()
Producción:
Obtener información sobre el conjunto de datos
Veamos la forma de los datos usando la forma.
Ejemplo:
Python3
df.shape
Producción:
(1000, 8)
Esto significa que este conjunto de datos tiene 1000 filas y 8 columnas.
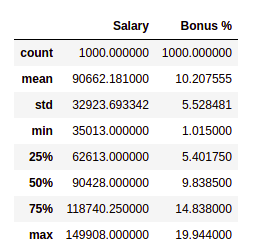
Obtengamos un resumen rápido del conjunto de datos usando el método describe() . La función describe() aplica cálculos estadísticos básicos en el conjunto de datos, como valores extremos, conteo de puntos de datos, desviación estándar, etc. Cualquier valor faltante o valor de NaN se omite automáticamente. describe() da una buena imagen de la distribución de datos.
Ejemplo:
Python3
df.describe()
Producción:
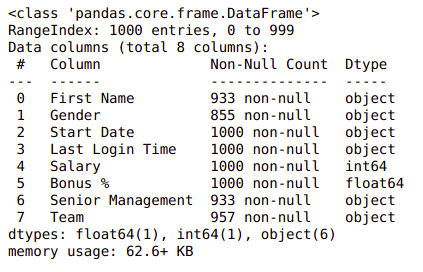
Ahora, veamos también las columnas y sus tipos de datos. Para ello, utilizaremos el método info() .
Python3
df.info()
Producción:
Hasta ahora tenemos una idea sobre el conjunto de datos utilizado. Ahora veamos si nuestro conjunto de datos contiene algún valor faltante o no.
Manejo de valores faltantes
Todos deben preguntarse por qué un conjunto de datos contendrá algún valor faltante. Puede ocurrir cuando no se proporciona información para uno o más artículos o para una unidad completa. Por ejemplo, suponga que diferentes usuarios encuestados pueden optar por no compartir sus ingresos, algunos usuarios pueden optar por no compartir la dirección de esta manera, muchos conjuntos de datos desaparecieron. La falta de datos es un problema muy grande en los escenarios de la vida real. Los datos faltantes también pueden referirse a valores NA (no disponibles) en pandas. Hay varias funciones útiles para detectar, eliminar y reemplazar valores nulos en Pandas DataFrame:
Ahora verifiquemos si faltan valores en nuestro conjunto de datos o no.
Ejemplo:
Python3
df.isnull().sum()
Producción:
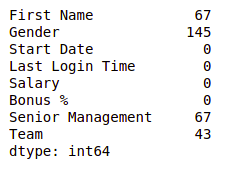
Podemos ver que cada columna tiene una cantidad diferente de valores faltantes. Al igual que Género como 145 valores faltantes y salario tiene 0. Ahora, para manejar estos valores faltantes, puede haber varios casos, como eliminar las filas que contienen NaN o reemplazar NaN con la media, la mediana, la moda o algún otro valor.
Ahora, intentemos completar los valores faltantes de género con la string «Sin género».
Ejemplo:
Python3
df["Gender"].fillna("No Gender", inplace = True)
df.isnull().sum()
Producción:
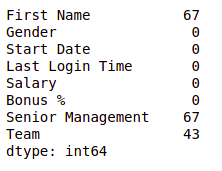
Podemos ver que ahora no hay un valor nulo para la columna de género. Ahora, llenemos la gerencia superior con el valor de modo.
Ejemplo:
Python3
mode = df['Senior Management'].mode().values[0] df['Senior Management']= df['Senior Management'].replace(np.nan, mode) df.isnull().sum()
Producción:
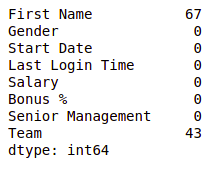
Ahora, para el nombre y el equipo, no podemos completar los valores faltantes con datos arbitrarios, así que eliminemos todas las filas que contienen estos valores faltantes.
Ejemplo:
Python3
df = df.dropna(axis = 0, how ='any') print(df.isnull().sum()) df.shape
Producción:
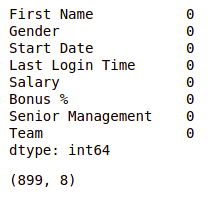
Podemos ver que nuestro conjunto de datos ahora está libre de todos los valores faltantes y, después de eliminar los datos, el número también se redujo de 1000 a 899.
Nota: Para obtener más información, consulte Trabajar con datos faltantes en Pandas .
Después de eliminar los datos que faltan, visualicemos nuestros datos.
Visualización de datos
La visualización de datos es el proceso de analizar datos en forma de gráficos o mapas, lo que facilita mucho la comprensión de las tendencias o patrones en los datos. Hay varios tipos de visualizaciones:
- Análisis univariante: este tipo de datos consta de una sola variable. El análisis de datos univariados es, por lo tanto, la forma más simple de análisis, ya que la información se ocupa de una sola cantidad que cambia. No se ocupa de causas o relaciones y el objetivo principal del análisis es describir los datos y encontrar patrones que existen dentro de ellos.
- Análisis bivariante: este tipo de datos involucra dos variables diferentes. El análisis de este tipo de datos se ocupa de las causas y las relaciones y el análisis se realiza para averiguar la relación entre las dos variables.
- Análisis multivariado: cuando los datos involucran tres o más variables, se clasifican como multivariados.
Veamos algunos gráficos de uso común:
Nota: Usaremos Matplotlib y la biblioteca Seaborn para la visualización de datos. Si desea conocer estos módulos, consulte los artículos:
Histograma
Se puede utilizar para análisis uni y bivariado.
Ejemplo:
Python3
# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.histplot(x='Salary', data=df, ) plt.show()
Producción:
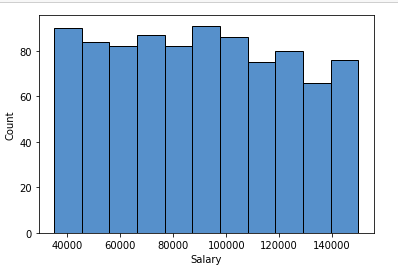
diagrama de caja
También se puede utilizar para análisis univariados y bivariados.
Ejemplo:
Python3
# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.boxplot( x="Salary", y='Team', data=df, ) plt.show()
Producción:
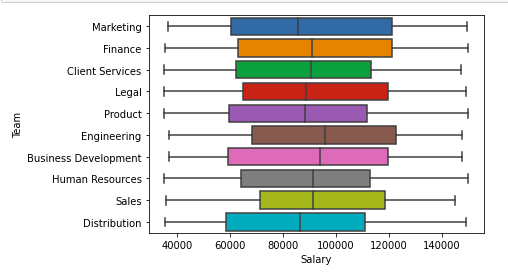
Gráfico de dispersión
Se puede utilizar para análisis bivariados.
Ejemplo:
Python3
# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.scatterplot( x="Salary", y='Team', data=df, hue='Gender', size='Bonus %') # Placing Legend outside the Figure plt.legend(bbox_to_anchor=(1, 1), loc=2) plt.show()
Producción:
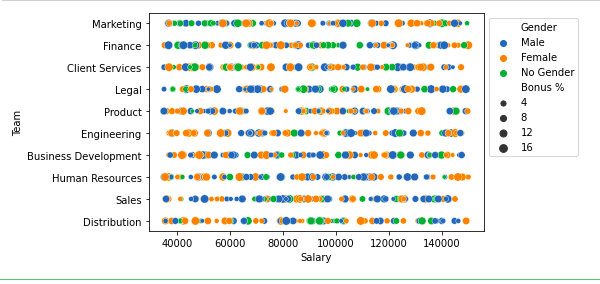
Para el análisis multivariante, podemos utilizar el método pairplot() del módulo seaborn. También podemos usarlo para las múltiples distribuciones bivariadas por pares en un conjunto de datos.
Ejemplo:
Python3
# importing packages import seaborn as sns import matplotlib.pyplot as plt sns.pairplot(df, hue='Gender', height=2)
Producción:
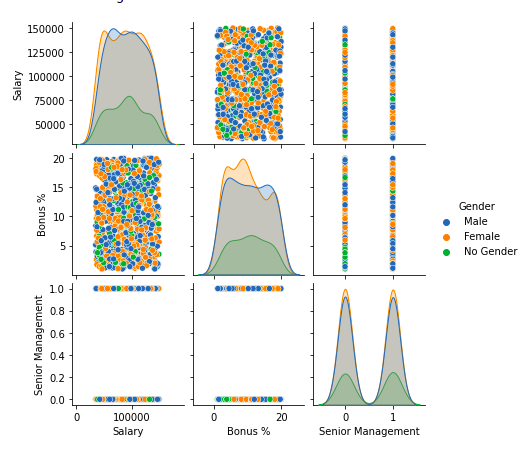
Manejo de valores atípicos
Un valor atípico es un elemento/objeto de datos que se desvía significativamente del resto de los objetos (llamados normales). Pueden ser causados por errores de medición o de ejecución. El análisis para la detección de valores atípicos se denomina minería de valores atípicos. Hay muchas formas de detectar los valores atípicos, y el proceso de eliminación es el marco de datos igual que eliminar un elemento de datos del marco de datos del panda.
Consideremos el conjunto de datos del iris y tracemos el diagrama de caja para la columna SepalWidthCm.
Ejemplo:
Python3
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
df = pd.read_csv('Iris.csv')
sns.boxplot(x='SepalWidthCm', data=df)
Producción:
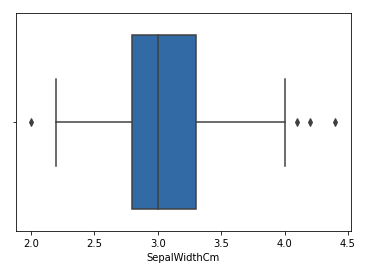
En el gráfico anterior, los valores por encima de 4 y por debajo de 2 actúan como valores atípicos.
Eliminación de valores atípicos
Para eliminar el valor atípico, se debe seguir el mismo proceso de eliminar una entrada del conjunto de datos usando su posición exacta en el conjunto de datos porque en todos los métodos anteriores para detectar los valores atípicos, el resultado final es la lista de todos los elementos de datos que satisfacen la definición de valor atípico. según el método utilizado.
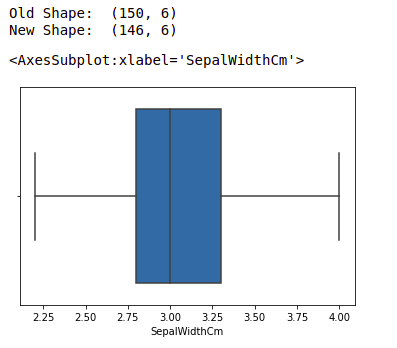
Ejemplo: Detectaremos los valores atípicos usando IQR y luego los eliminaremos. También dibujaremos el diagrama de caja para ver si se eliminan los valores atípicos o no.
Python3
# Importing
import sklearn
from sklearn.datasets import load_boston
import pandas as pd
import seaborn as sns
# Load the dataset
df = pd.read_csv('Iris.csv')
# IQR
Q1 = np.percentile(df['SepalWidthCm'], 25,
interpolation = 'midpoint')
Q3 = np.percentile(df['SepalWidthCm'], 75,
interpolation = 'midpoint')
IQR = Q3 - Q1
print("Old Shape: ", df.shape)
# Upper bound
upper = np.where(df['SepalWidthCm'] >= (Q3+1.5*IQR))
# Lower bound
lower = np.where(df['SepalWidthCm'] <= (Q1-1.5*IQR))
# Removing the Outliers
df.drop(upper[0], inplace = True)
df.drop(lower[0], inplace = True)
print("New Shape: ", df.shape)
sns.boxplot(x='SepalWidthCm', data=df)
Producción:
Nota: para obtener más información, consulte Detectar y eliminar los valores atípicos mediante Python
Publicación traducida automáticamente
Artículo escrito por nikhilaggarwal3 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA