Dado que la red neuronal de convolución (CNN) con una capa completamente conectada no puede manejar la frecuencia de ocurrencia y los objetos múltiples. Entonces, una forma podría ser que usemos una búsqueda de fuerza bruta de ventana deslizante para seleccionar una región y aplicar el modelo CNN en eso, pero el problema de este enfoque es que el mismo objeto se puede representar en una imagen con diferentes tamaños y diferentes aspectos. relación. Si bien consideramos estos factores, tenemos muchas propuestas regionales y, si aplicamos el aprendizaje profundo (CNN) en todas esas regiones, sería computacionalmente muy costoso.
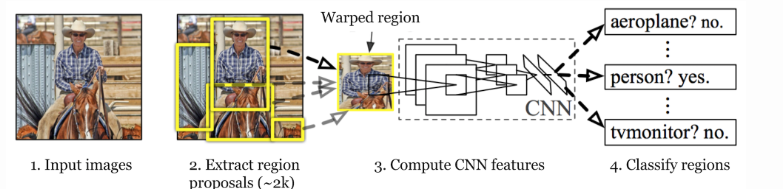
arquitectura R-CNN
Propuestas de regiones:
las propuestas de regiones son simplemente las regiones más pequeñas de la imagen que posiblemente contengan los objetos que estamos buscando en la imagen de entrada. Para reducir las propuestas de región en la R-CNN se utiliza un algoritmo voraz llamado búsqueda selectiva.
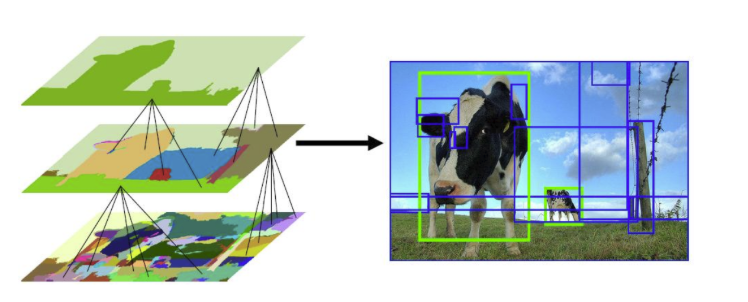 Región Generación de propuestas mediante búsqueda selectiva (Fuente de la imagen:)
Región Generación de propuestas mediante búsqueda selectiva (Fuente de la imagen:)
Búsqueda selectiva:
la búsqueda selectiva es un algoritmo codicioso que combina regiones segmentadas más pequeñas para generar una propuesta de región. Este algoritmo toma una imagen como entrada y genera propuestas de región sobre ella. Este algoritmo tiene la ventaja sobre la generación de propuestas aleatorias de que limita el número de propuestas a aproximadamente 2000 y estas propuestas regionales tienen un alto recuerdo.
Algoritmo:
- Genere una subsegmentación inicial de la imagen de entrada.
- Combine cuadros delimitadores similares en otros más grandes recursivos
- Utilice estos cuadros más grandes para generar propuestas de regiones para la detección de objetos.
En el Paso 2, las similitudes se consideran en función de la similitud del color, la similitud de la textura, el tamaño de la región, etc. Hemos analizado el algoritmo de búsqueda selectiva con gran detalle en este artículo .
Arquitectura CNN de R-CNN:
después de eso, estas regiones se deforman en el único cuadrado de regiones de dimensión según lo requiere el modelo CNN. El modelo de CNN que usamos aquí es un modelo de AlexNet pre-entrenado, que es el modelo de CNN de última generación en ese momento para la clasificación de imágenes. Veamos aquí la arquitectura de AlexNet.
Aquí la entrada de AlexNet es (227, 227, 3) . Entonces, si las propuestas de la región son pequeñas y grandes, entonces debemos redimensionar esa propuesta de región a las dimensiones dadas.
De la arquitectura anterior, eliminamos la última capa softmax para obtener el vector de características (1, 4096) . Pasamos este vector de características a SVM y al regresor de cuadro delimitador.

SVM (Máquina de vectores de soporte):
el vector de características generado por CNN es luego consumido por el SVM binario que se entrena en cada clase de forma independiente. Este modelo SVM toma el vector de características generado en la arquitectura CNN anterior y genera una puntuación de confianza de la presencia de un objeto en esa región. Sin embargo, hay un problema para el entrenamiento con SVM: requerimos vectores de características de AlexNet para entrenar la clase SVM. Por lo tanto, no pudimos entrenar a AlexNet y SVM de manera independiente en forma paralela. Este desafío se resuelve en futuras versiones de R-CNN (Fast R-CNN, Faster R-CNN, etc.).
Regresor de cuadro delimitador:
para ubicar con precisión el cuadro delimitador en la imagen, utilizamos un modelo de regresión lineal de escala invariable llamado regresor de cuadro delimitador. Para entrenar este modelo, tomamos pares predichos y reales de cuatro dimensiones de localización. Estas dimensiones son (x, y, w, h) donde x e y son las coordenadas de píxel del centro del cuadro delimitador, respectivamente. w y h representan el ancho y el alto de los cuadros delimitadores. Este método aumenta la precisión media media (mAP) del resultado en un 3-4 % .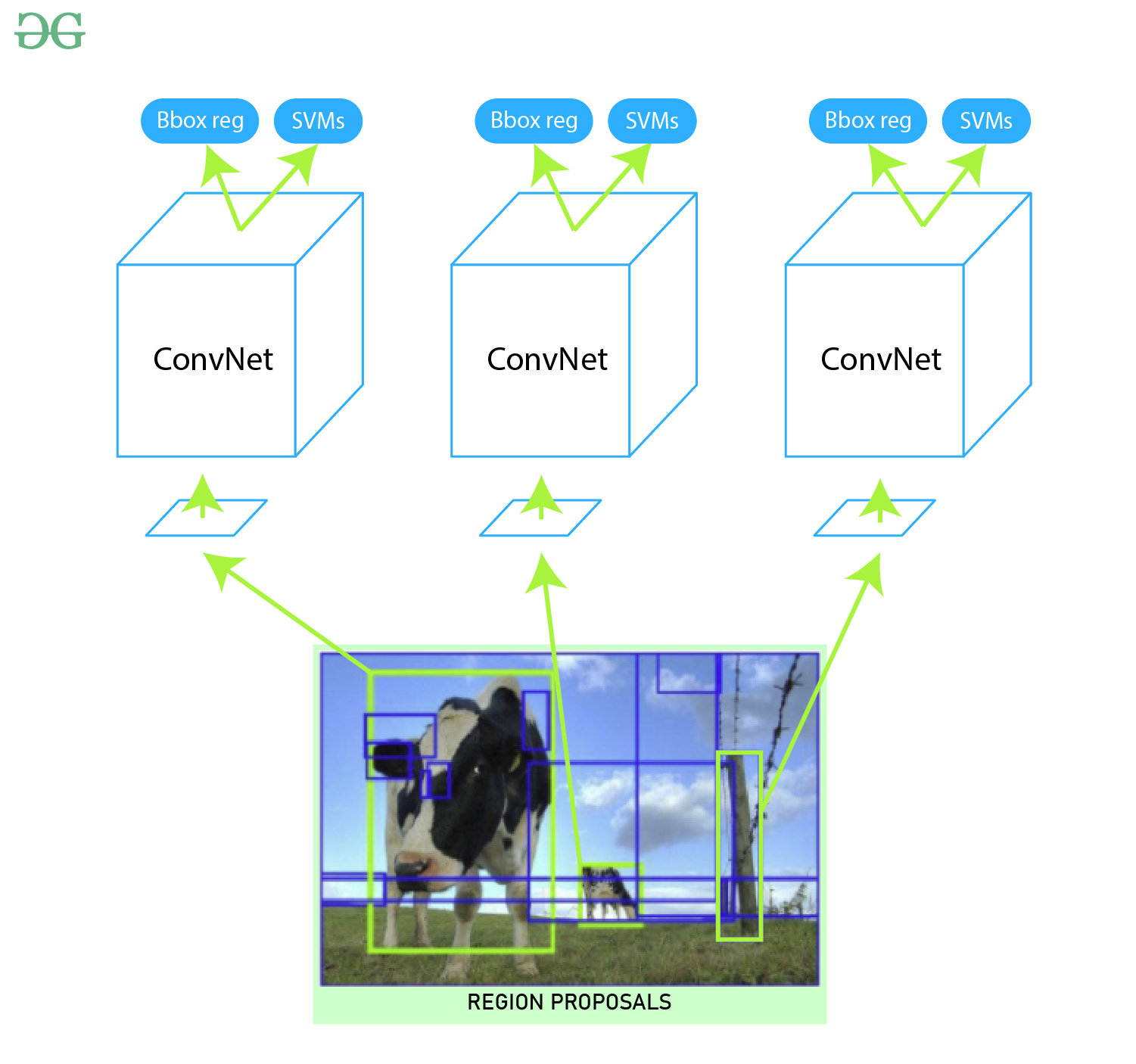
Salida:
Ahora tenemos propuestas de región que están clasificadas para cada etiqueta de clase. Para lidiar con el cuadro delimitador adicional generado por el modelo anterior en la imagen, usamos un algoritmo llamado supresión no máxima.
Funciona en 3 pasos:
- Deseche aquellos objetos en los que la puntuación de confianza sea inferior a un determinado valor de umbral (por ejemplo, 0,5) .
- Seleccione la región que tenga la probabilidad más alta entre las regiones candidatas para el objeto como región predicha.
- En el paso final, descartamos aquellas regiones que tienen IoU (intersección sobre unión) con una región prevista superior a 0,5.

Después de eso, podemos obtener resultados trazando estos cuadros delimitadores en la imagen de entrada y etiquetando los objetos que están presentes en los cuadros delimitadores.
Resultados:
el R-CNN proporciona una precisión media media (mAP) del 53,7 % en el conjunto de datos VOC 2010. En el conjunto de datos de detección de objetos ILSVRC 2013 de clase 200, proporciona un mAP de 31,4 % , lo que representa una gran mejora con respecto al mejor 24,3 % anterior . Sin embargo, esta arquitectura es muy lenta de entrenar y tarda ~ 49 segundos en generar resultados de prueba en una sola imagen del conjunto de datos de VOC 2007.
Desafíos de R-CNN:
- El algoritmo de búsqueda selectiva es muy rígido y no hay aprendizaje en eso. Esto a veces conduce a la generación de propuestas de regiones incorrectas para la detección de objetos.
- Ya que hay aproximadamente 2000 propuestas de candidatos. Se necesita mucho tiempo para entrenar la red. También necesitamos entrenar varios pasos por separado (arquitectura CNN, modelo SVM, regresor de cuadro delimitador). Entonces, esto hace que sea muy lento de implementar.
- R-CNN no se puede utilizar en tiempo real porque se tarda aproximadamente 50 segundos en probar una imagen con un regresor de cuadro delimitador.
- Ya que necesitamos guardar mapas de características de todas las propuestas de la región. También aumenta la cantidad de memoria de disco necesaria durante el entrenamiento.
Referencias: