R-CNN:
R-CNN fue propuesto por Ross Girshick et al. en 2014 para abordar el problema de la localización eficiente de objetos en la detección de objetos. Los métodos anteriores utilizan lo que se denomina Búsqueda exhaustiva, que utiliza ventanas deslizantes de diferentes escalas en la imagen para proponer propuestas de regiones. Este algoritmo de búsqueda selectiva propone aproximadamente 2000 propuestas de región por imagen. Estos luego se pasan al modelo CNN (aquí se usa AlexNet).
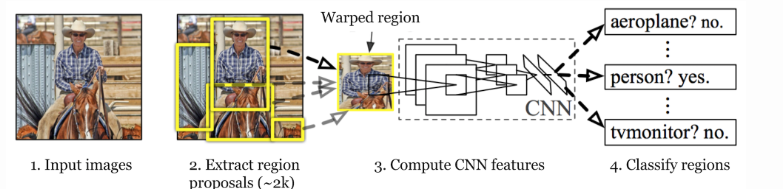
arquitectura R-CNN
Este modelo CNN luego genera un vector de características (1, 4096) de cada propuesta de región. Este vector luego pasó al modelo SVM para la clasificación del objeto y el regresor de cuadro delimitador para la localización.
Problema con R-CNN:
- Se requieren 49 segundos para detectar los objetos en una imagen en GPU.
- Para almacenar el mapa de características de la propuesta de región, también se requiere mucho espacio en disco.
Fast R-CNN:
en R-CNN pasamos cada propuesta de región una por una en la arquitectura de CNN y la búsqueda selectiva generó alrededor de 2000 propuestas de región para una imagen. Por lo tanto, es computacionalmente costoso entrenar e incluso probar la imagen usando R-CNN. Para hacer frente a este problema, se propuso Fast R-CNN, que toma la imagen completa y las propuestas de región como entrada en su arquitectura CNN en una propagación hacia adelante. También combina diferentes partes de la arquitectura (como ConvNet, agrupación de RoI y capa de clasificación) en una arquitectura completa. Eso también elimina el requisito de almacenar un mapa de características y ahorra espacio en disco. También utiliza la capa softmax en lugar de SVM en su propuesta de clasificación de regiones, que demostró ser más rápida y generar una mayor precisión que SVM.

Arquitectura R-CNN rápida
Fast R-CNN mejora drásticamente el entrenamiento (8,75 horas frente a 84 horas) y el tiempo de detección de R-CNN. También mejora marginalmente la precisión media media (mAP) en comparación con R-CNN.
Problemas con Fast R-CNN:
- La mayor parte del tiempo que tarda Fast R-CNN durante la detección es un algoritmo de generación de propuesta de región de búsqueda selectiva. Por lo tanto, es el cuello de botella de esta arquitectura el que se trató en Faster R-CNN.
R-CNN más rápido:
Faster R-CNN fue presentado en 2015 por k He et al. Después del Fast R-CNN, el cuello de botella de la arquitectura es la búsqueda selectiva. Ya que necesita generar 2000propuestas por imagen. Constituye una parte importante del tiempo de formación de toda la arquitectura. En Faster R-CNN, fue reemplazada por la red de propuesta de región. En primer lugar, en esta red, pasamos la imagen a la red troncal. Esta red troncal genera un mapa de características de convolución. Estos mapas de características luego se pasan a la red de propuesta de región. La red de propuesta de región toma un mapa de características y genera los anclajes (el centro de la ventana deslizante con un tamaño y una escala únicos). Estos anclajes luego se pasan a la capa de clasificación (que clasifica si hay un objeto o no) y la capa de regresión (que localiza el cuadro delimitador asociado con un objeto).
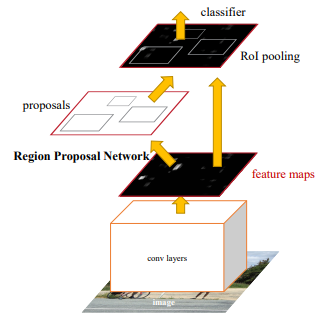
Arquitectura R-CNN más rápida
En términos de tiempo de detección, Faster R-CNN es más rápido que R-CNN y Fast R-CNN. El Faster R-CNN también tiene mejor mAP que los dos anteriores.
Comparación entre R-CNN, Fast R-CNN y Faster R-CNN:
| R-CNN | R-CNN rápido | R-CNN más rápido | |
|---|---|---|---|
| Método para generar propuestas de regiones | Búsqueda selectiva | Búsqueda selectiva | Región Propuesta Red |
| El conjunto de datos de prueba mAp en Pascal VOC 2007 (%) | 58.5 |
66.9 (solo cuando se entrena con VOC 2007) 70.0 (cuando se entrena con VOC 2007 y 2012 ambos) |
69.9 (solo cuando se entrena con VOC 2007) 73.2 (cuando se entrena con VOC 2007 y 2012 ambos) 78,8 (cuando se entrena con VOC 2007 y 2012 y COCO) |
| El conjunto de datos de prueba mAp en Pascal VOC 2012 (%) | 53.3 |
65.7 (solo cuando se entrena con VOC 2012) 68.4 (cuando se entrena con VOC 2007 y 2012 ambos) |
67.0 (solo cuando se entrena con VOC 2012) 70.4 (cuando se entrena con VOC 2007 y 2012 ambos) 75.9 (cuando se entrena con VOC 2007 y 2012 y COCO) |
| Tiempo de detección (seg) | ~ 49 (con generación de propuesta de región) | ~ 2.32 (con generación de propuesta de región) |
0.2 (con VGG), 0,059 (con ZF) |
Los resultados del tiempo de detección anteriores son del trabajo de investigación. Pueden variar dependiendo de las configuraciones de la máquina.
Referencias: