Después de la mejora en la arquitectura de la red de detección de objetos en R-CNN a Fast R_CNN. El tiempo de entrenamiento y detección de la red disminuye considerablemente, pero la red no es lo suficientemente rápida para ser utilizada como un sistema en tiempo real porque tarda aproximadamente (2 segundos) en generar una salida en una imagen de entrada. El cuello de botella de la arquitectura es un algoritmo de búsqueda selectiva. Por lo tanto , K He et al. propuso una nueva arquitectura llamada Faster R-CNN. No utiliza la búsqueda selectiva, sino que propone otro algoritmo de generación de propuestas de región llamado Red de propuesta de región. Analicemos la arquitectura Faster R-CNN.
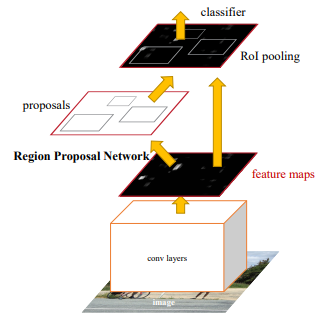
Arquitectura R-CNN más rápida
La arquitectura R-CNN más rápida contiene 2 redes:
- Red de Propuestas Regionales (RPN)
- Red de detección de objetos
Antes de discutir la propuesta de la Región, debemos analizar la arquitectura de CNN, que es la columna vertebral de esta red. Esta arquitectura CNN es común entre la Red de propuesta de región y la Red de detección de objetos. Experimentamos con ZF (que tiene 5 capas de Conv compartibles) o VGG-16 (que tiene 13 Conv compartibles) como la columna vertebral de su arquitectura. Ambas redes troncales tienen un paso de red de 16, lo que significa que una imagen de dimensión 1000 * 600 se reduce a (1000/16 * 600/16) o aproximadamente (~ 62 * 37) mapa de características de tamaño antes de pasar a la red propuesta de región.
Red de propuesta de región (RPN):
esta red de propuesta de región toma el mapa de características de convolución generado por la capa troncal como entrada y genera los anclajes generados por la convolución de ventana deslizante aplicada en el mapa de características de entrada.
Anclajes:
Para cada ventana deslizante, la red genera el número máximo de k-cajas de anclaje. Por defecto, el valor de k=9 ( 3 escalas de (128*128, 256*256 y 512*512) y 3 relaciones de aspecto de (1:1, 1:2 y 2:1)) para cada uno de los diferentes deslizamientos posición en la imagen. Por lo tanto, para un mapa de características de convolución de W * H , obtenemos N = W* H* k cajas de anclaje. Estas propuestas de región luego pasaron a una capa intermedia de 3*3 convolución y 1 relleno y 256 (para ZF) o 512 (para VGG-16)canales de salida La salida generada a partir de esta capa se pasa a dos capas de convolución 1*1 , la capa de clasificación y la capa de regresión. la capa de regresión tiene 4*N (W * H * (4*k)) parámetros de salida (que indican las coordenadas de los cuadros delimitadores) y la capa de clasificación tiene 2*N (W * H * (2*k)) parámetros de salida ( que denota la probabilidad de objeto o no objeto).
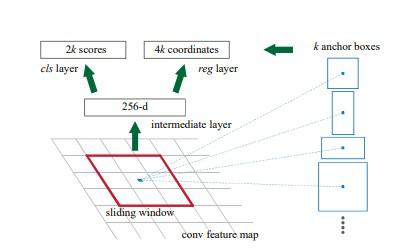
Generación de anclas
Función de entrenamiento y pérdida (RPN):
en primer lugar, eliminamos todas las anclas transfronterizas para que no aumenten la función de pérdida. Para una imagen típica de 1000*600 , hay aproximadamente 20000 (~ 60*40*9) anclajes. Si eliminamos los anclajes transfronterizos, quedan aproximadamente 6000 anclajes por imagen. El documento también utiliza la supresión no máxima en función de su clasificación y IoU. Aquí usan un IoU fijo de 0.7 . Esto también reduce el número de anclas a 2000 .. La ventaja de usar la supresión no máxima es que tampoco perjudica la precisión. RPN se puede entrenar de extremo a extremo mediante el uso de retropropagación y descenso de gradiente estocástico. Genera cada mini-lote a partir de los anclajes de una sola imagen. No entrena la función de pérdida en cada ancla, sino que selecciona 256 anclas aleatorias con muestras positivas y negativas en una proporción de 1:1 . Si una imagen contiene <128 positivos, utiliza más muestras negativas. Para entrenar RPN, primero, debemos asignar una etiqueta de clase binaria (si el ancla en cuestión contiene un objeto o un fondo). En el artículo más rápido de R-CNN, el autor usa dos condiciones para asignar una etiqueta positiva a un ancla. Estos son :
- aquellas anclas que tienen la Intersección sobre Unión (IoU) más alta con un cuadro de verdad de tierra, o
- un ancla que tiene una superposición de IoU superior a 0,7 con cualquier cuadro de verdad en el terreno.
y la etiqueta negativa para aquellos que tienen superposición de IoU es <0.3 para todas las cajas de verdad de tierra. Aquellas anclas que no tengan etiqueta ni positiva ni negativa no contribuyen a la formación. Ahora la función de pérdida se define de la siguiente manera:

where, pi = predicted probability of anchors contains an object or not. pi* = ground truth value of anchors contains and object or not. ti = coordinates of predicted anchors. ti* = ground truth coordinate associated with bounding boxes. Lcls = Classifier Loss (binary log loss over two classes). Lreg = Regression Loss (Here, Lreg = R(ti-ti*) where R is smooth L1 loss) Ncls = Normalization parameter of mini-batch size (~256). Nreg = Normalization parameter of regression (equal to number of anchor locations ~2400).In order to make n=both loss parameter equally weighted right.
Red de detección de objetos:
la red de detección de objetos utilizada en Faster R-CNN es muy similar a la utilizada en Faster R-CNN. También es compatible con VGG-16 como red troncal. También utiliza la capa de agrupación RoI para hacer una propuesta de región de tamaño fijo y capas gemelas de clasificador softmax y el regresor de cuadro delimitador también se utiliza en la predicción del objeto y su cuadro delimitador.
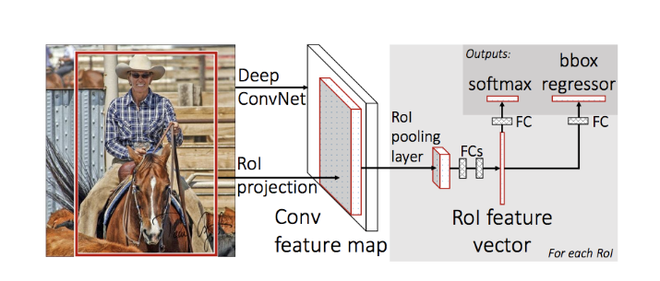
Arquitectura R-CNN rápida
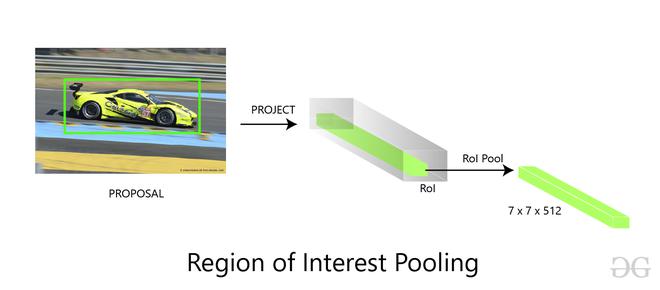
Agrupación de RoI:
tomamos la salida generada a partir de la propuesta de región como entrada y la pasamos a la capa de agrupación de RoI, esta capa de agrupación de RoI tiene la misma función que la que realizaba en Fast R-CNN, para hacer propuestas de región de diferentes tamaños generadas a partir de RPN en un fijo mapa de características de tamaño. Hemos discutido la agrupación de ROI en este artículo en gran detalle. Esta capa de agrupación de RoI genera la salida de tamaño (7*7*D) (donde D = 256 para ZF y 512 de VGG-16 ).
Softmax y capa de regresión de cuadro delimitador:
el mapa de características de tamaño (7 * 7 * D) generado en la agrupación de RoI se envía a dos capas completamente conectadas, estas capas completamente conectadas aplanan los mapas de características y luego envían la salida a dos capas paralelas completamente conectadas. capa cada uno con la tarea diferente asignada a ellos:
- La primera capa es una capa softmax de N+1 parámetros de salida ( N es el número de etiquetas de clase y fondo) que predice los objetos en la propuesta de región. La segunda capa es una capa de regresión de cuadro delimitador que tiene 4* N parámetros de salida. Esta capa hace retroceder la ubicación del cuadro delimitador del objeto en la imagen.
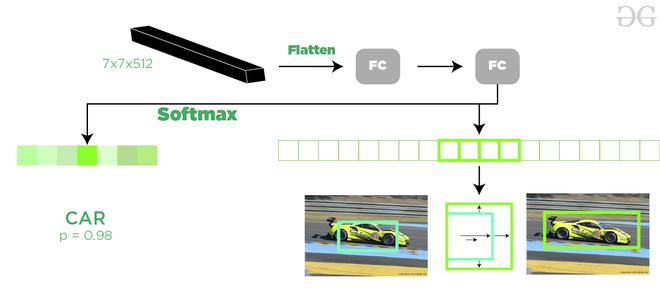
Clasificador Softmax y regresor de cuadro delimitador
Entrenamiento (Arquitectura Completa):
Hemos discutido el entrenamiento del RPN pero en esta parte, discutiremos el entrenamiento de toda la arquitectura. Los autores de los artículos de Faster R-CNN utilizan un enfoque llamado método de entrenamiento alternativo de 4 pasos. Este enfoque es el siguiente
- Primero inicializamos la red troncal CNN con pesos de ImageNet y ajustamos estos pesos para la propuesta de región. Ahora, entrenamos el RPN como se describe arriba.
- Por separado entrenamos la red de detección de objetos utilizando la propuesta generada por la red RPN. En esta parte también se inicializa la red troncal con peso ImageNet y hasta el momento no está conectada a la red RPN.
- El RPN ahora se inicializa con pesos de una red de detectores (Fast R-CNN). Esta vez solo se ajustan los pesos de las capas exclusivas del RPN.
- Usando el nuevo RPN ajustado, el detector Fast R-CNN está ajustado. Una vez más, solo se ajustan las capas exclusivas de la red de detectores y se fijan los pesos de las capas comunes.
Resultados y Conclusión:
- Dado que el cuello de botella de la arquitectura Fast R-CNN es la generación de propuestas de región con la búsqueda selectiva. Faster R-CNN lo reemplazó con su propia red de propuestas regionales. Esta red de propuestas regionales es más rápida en comparación con la selectiva y también mejora el modelo de generación de propuestas regionales durante el entrenamiento. Esto también nos ayuda a reducir el tiempo de detección general en comparación con Fast R-CNN ( 0,2 segundos con Faster R-CNN (red VGG-16) en comparación con 2,3 en Fast R-CNN).
- R-CNN más rápido (con RPN y VGG compartidos) cuando se entrena con el conjunto de datos COCO, VOC 2007 y VOC 2012 genera mAP de 78,8 % frente al 70 % en Fast R-CNN en el conjunto de datos de prueba VOC 2007)
- Region Proposal Network (RPN), en comparación con la búsqueda selectiva, también contribuyó marginalmente a la mejora de mAP.
Referencias :